Reading Between the Lines: How We Make Sense of Users' Searches

-
Heath V., Software Engineer
- Feb 11, 2015
The Problem
People expect a lot out of search queries on Yelp. Understanding exact intent from a relatively vague text input is challenging. A few months ago, the Search Quality team felt like we needed to take a step back and reassess how we were thinking about a user’s search so that we could return better results for a richer set of searches.
Our main business search stack takes into account many kinds of features that can each be classified as being related to one of distance, quality and relevance. However, sometimes these signals encode related meaning, making the equivalence between them difficult to understand (e.g., we know a business is marked as “$ – inexpensive” and that people mention “cheap” in their reviews), but often they capture orthogonal information about a business (e.g., reviews are not a reliable source of a business’ hours). We need a stage where we discern which parts of a query tell us what types of information should be searched over.
It’s also useful to embellish the plain text of a search query with context. Are there related words that are very relevant to a substring of text? Is it possible that the user misspelled part of the query? Having this extended information would enhance our ability to recall relevant businesses, especially in low content areas.
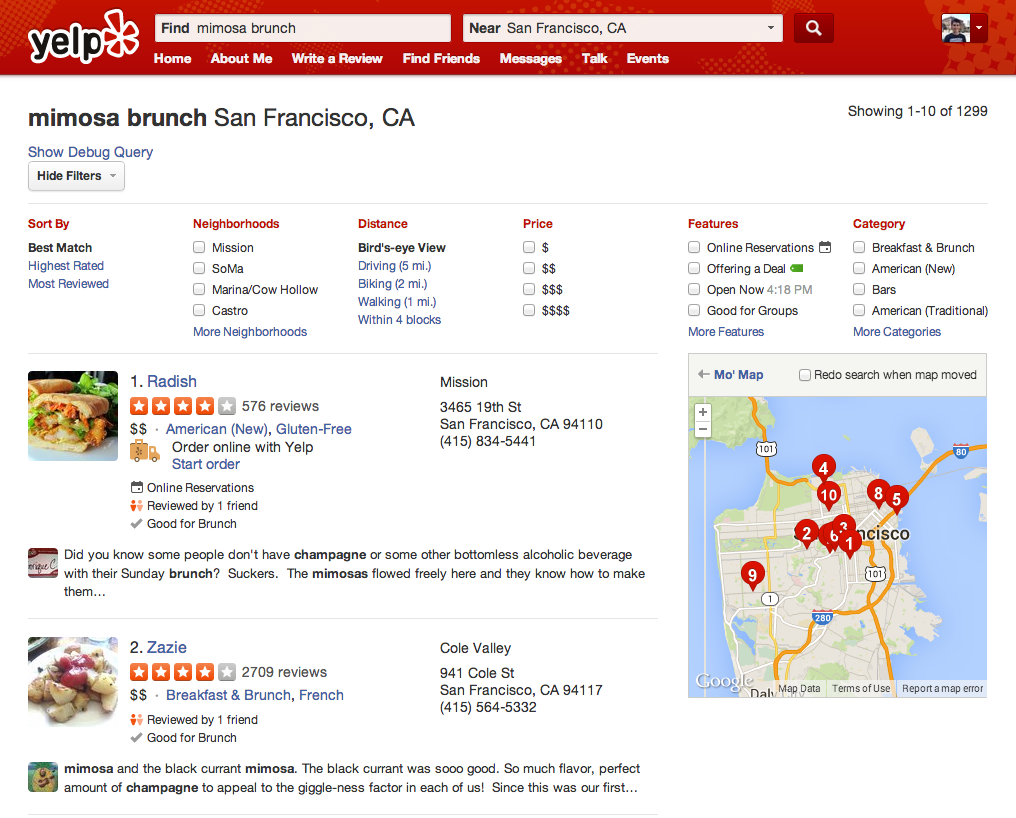
Let’s consider a more concrete example, such as a search for “mimosa brunch” in San Francisco. The above search results show some features that our desired (and now current) query understanding system should be able to extract:
- “mimosa” has the related search term “champagne”
- “brunch” maps to the attribute “Good for Brunch”
All these enhancements sounded great but were becoming increasingly difficult to implement. Our old search stack combined the understanding of the intent and semantics of a query and its execution into a single step. This resulted in engineers having a hard time adding new quality features: concepts were overloaded (the word “synonym” had very different meanings in different parts of the code), questions of semantics were tied up in execution implementation, and there was no way for other parts of Yelp to understand the semantic knowledge locked up in our Lucene search stack.
Semantics as Abstraction
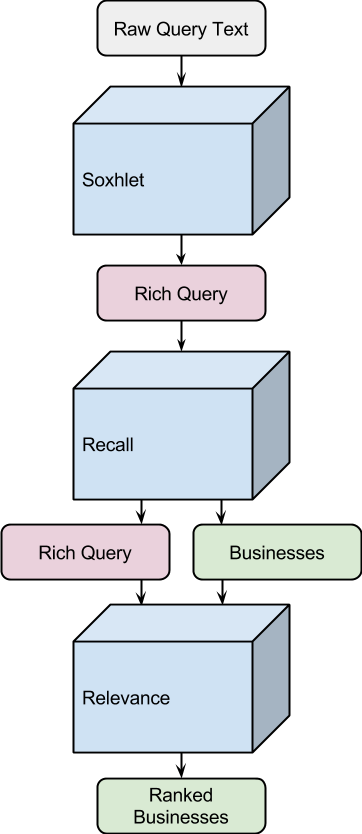
To help solve these problems, we found it useful to formally split up the process of extracting meaning from the process of executing a search query. To that end, we created a component named Soxhlet (named after a kind of extractor used in chemistry labs) which runs before search execution, and whose sole job is to extract meaning from a raw text query. It turns the input text into a Rich Query that holds structured semantics in the context of business search. This Rich Query then becomes the preferred abstraction for the rest of the search stack to execute upon.
Encoding Meaning
What does this Rich Query data structure look like? When we were first whiteboarding possible representations we tended to underline parts of the query and assign semantics to each part.
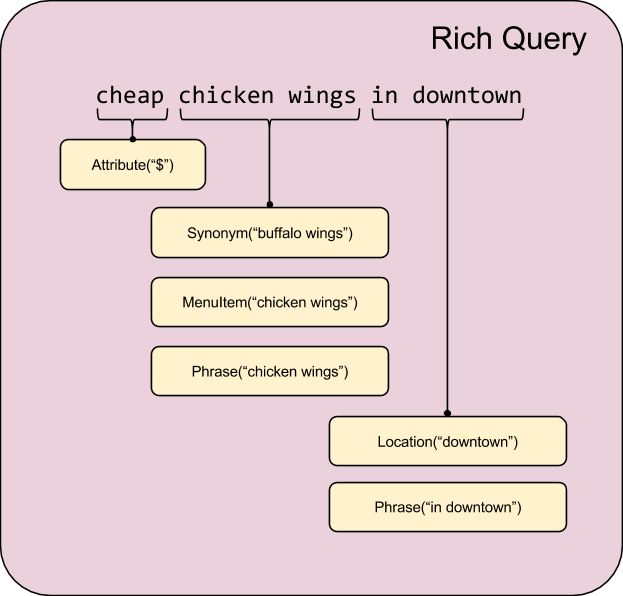
As you can see from the above representation, there are complex semantics encoded in a signal that is mostly textual (the query text). Therefore, we think that annotating the query string is a good way to represent a Rich Query: ranges of the original query text are marked as having typed information via various kinds of Annotations.
For those of you familiar with Lucene, this data structure is very similar to a TokenStream but with annotations instead of attributes. This makes consumption of the Rich Query in the recall and relevance steps straightforward while at the same time giving enough abstraction so that non-search components can also easily consume Rich Queries.
As an example, the extracted RichQuery for a query popular with our team is:
When the above Rich Query is analyzed by our core relevance stack (a service called “Lucy”) from the AttributeQueryAnnotation, it knows to also search over the attribute field of businesses for the “$” attribute. Furthermore, the confidence of 1.0 implies that an attribute match should be considered equivalent to a textual match for “cheap.” Other annotations may have lower confidences associated with them if their extraction process is less precise and this is factored into the scoring function of constructed Lucene queries.
By being able to use the way Annotations overlap in the original search query, it’s now possible to more easily cross-reference Annotations with each other and with the original text. The recall and relevance stages of the search stack use this ability to ensure that the right constraints are used.
Extraction Process
What is the architecture within Soxhlet that allows us to turn a plain query into a Rich Query? Our first observation is that we should have specialized components for producing each type of Annotation. Our second observation is that basic Annotations can help identify more complex ones; you could imagine taking advantage of detected synonyms to properly identify cost attributes in the search query string, etc.
From these observations, we decided that a good starting design was a series of transformation steps that iteratively adds new Annotation types. Each one of these steps is called a Transformer. Each transformer takes a Rich Query as input, looks at all existing Annotations and the original query text, and produces a modified Rich Query as output that possibly contains new annotations. Stripped of boilerplate, the code for the top-level Soxhlet class is very simple:
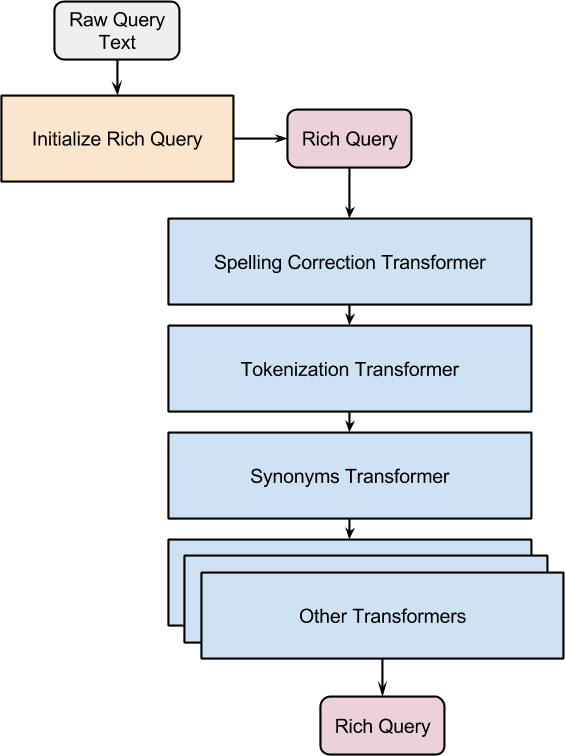
This architecture also provides us with a mechanism for sharing prerequisite work between Transformers, while not forcing coupling between earlier Transformers or the search recall and relevance steps. As an example, although all Transformers could operate on the raw query string, many kinds of text analysis work on the token level, so many Transformers would have to duplicate the work of tokenizing the query string. Instead, we can have a tokenization Transformer create token Annotations from the raw string, and then every subsequent Transformer has access to that tokenization information.
This optimization should be used carefully though with Soxhlet being internationalized into dozens of languages and more being regularly added, normalization (accent removal, stemming etc.) is an important part of extracting rich queries. It’s tempting to store to normalized queries at beginning of the extraction process but we have avoided doing so to prevent couplings among Transformers and between Soxhlet and other services such as the recall and relevance stage of the search stack.
The Transformers themselves can vary in complexity so let’s dive into some details on how they actually work:
Spelling Transformer
We actually use two different types of spelling transformations. “Spelling Suggestion” is where we still perform the Rich Query extraction and search on the original query but offer a “Did You Mean” link in the results for queries that could be good suggestions. These suggestions are computed at query time by generating candidate suggestions within a small edit distance of the original query and then scoring them with a noisy channel model that takes into account query priors and likelihood of edits.
“Spelling Correction” occurs when we are very confident about a correction and perform the Rich Query extraction and search on the corrected query. These corrections are generated by promoting Spelling Suggestions that have performed well in the past based on click rates for their “Did You Mean” link. At query time we simply lookup a map from query to correction.
This two-tiered approach is very effective in that it allows us to achieve high precision with Spelling Correction without sacrificing recall by allowing Spelling Suggestions for lower confidence suggestions. Our future plans for spelling include improving internationalization and incorporating more advanced features such as a phonetic algorithm into our suggestion scorer.
Synonyms Transformer
Context is very important to synonym extraction and this drove a number of our design decisions:
- The same word can have different synonyms in different query contexts. For example, the word “sitting” in the query “pet sitting” has the synonym “boarding”. However, the same word in the query “house sitting” probably shouldn’t have “boarding” as a synonym.
- The same word in the same query can have different synonyms in different domain contexts. For example the word “haircut” could have the synonym “barber” in a local business search engine such as Yelp. However, on an online shopping website a better synonym would be “hair clippers”.
- The same word can be used very differently in queries compared to documents. For example, it might be common for a review to mention “I got my car repaired here” but it would be very unusual to write “I got my auto repaired here”. As a result, an algorithm that uses only document data to extract synonyms would likely not recall “auto repair” having the synonym “car repair” despite this being a very good query synonym. In fact, research has shown that the similarity between queries and documents is typically very low.
To solve the above problems we adopted a two-step approach to synonym extraction. In the first step we extract possible candidate synonyms from user’s query refinements. In the second step we create vectors for each query containing the distribution of clicked businesses and then score synonyms based on the cosine similarity of their query vectors. We store this information in a lookup table that is accessed at query time to find synonyms.
Attributes Transformer
We found a simple lookup table mapping between phrases and attributes to be very effective for extracting attributes. This transformer also illustrates one of the benefits of a unified query understanding framework - by piggy-backing off the results of the Synonyms Transformer we are able to use the knowledge that “cheap” is a synonym of “inexpensive” to extract the attribute of “$” from “inexpensive restaurant” without explicitly having the mapping of the “inexpensive” to “$” in our attribute lookup. Although the Attributes Transformer is very simple but precise, you could imagine ways of improving the recall such as using a language model for each attribute.
For example the Synonyms Transformer simply contains a dictionary to lookup synonyms that have been pre-generated by batch jobs from query logs. On the other hand, the Spelling Correction Transformer uses a more complex noisy channel model at query time to determine likely corrections.
Conclusion
Using Soxhlet in our business search stack, we’ve been able to roll out the ability to use query synonyms to enhance recall and relevance, more intelligently spell-correct query mistakes, better detect attributes in queries and most importantly we now have an elegant framework for extending our query understanding functionality by adding new transformers. We have already seen significant search results CTR gains as a result of these changes and have set a foundation for sharing with other parts of Yelp our concept of meaning for business search queries. Although it is a major undertaking to move many of the existing “meaning extraction,” like parts of our search stack into Soxhlet, we believe the benefits from this architecture are well worth it.
Special thanks to David S. for helping author this blog post and the Query Understanding team who helped build the platform: Chris F., Ray G., Benjamin G., Natarajan S., Maria C., and Denis L.