How Yelp Keeps Server-Driven UI Consistent Across Four Platforms

-
Radu Comaneci, Software Engineer
- Apr 22, 2026
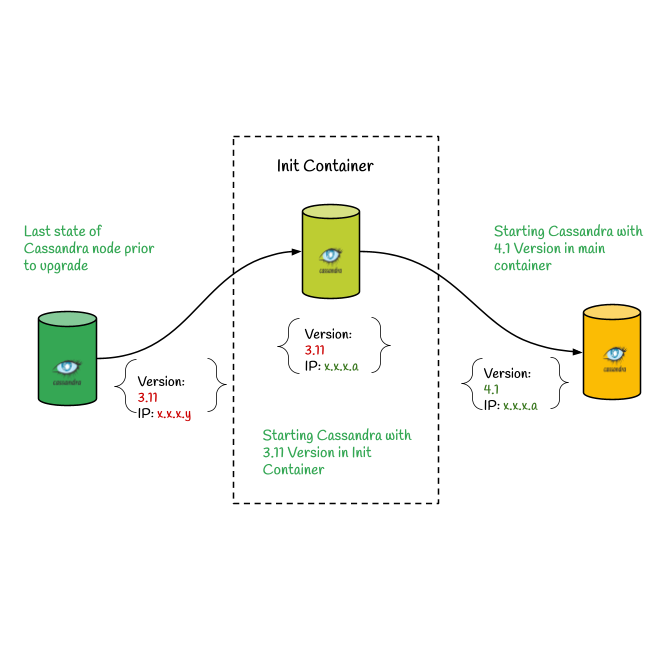
If you’ve read our earlier post, you already know about CHAOS—the server-driven UI (SDUI) framework we built at Yelp that powers our dynamic views. Until now, we’ve explored its architecture, backend implementation, and component model. In this post, we’ll dive into how we integrated CHAOS with Yelp’s cross-platform design system, Cookbook, and the auto-generated bridge library, Konbini. Introduction to Cookbook At Yelp, we support two major applications across our Web, iOS, and Android platforms: Yelp and Yelp for Business. This results in six different variations, which makes it challenging to maintain a unified experience. To address this challenge, we created...