dataloader-codegen: Autogenerate DataLoaders for your GraphQL Server!

-
Mark Larah, Tech Lead
- Apr 8, 2020
We’re open sourcing dataloader-codegen, an opinionated JavaScript library for automatically generating DataLoaders over a set of resources (e.g. HTTP endpoints). Go check it out on GitHub! This blog post discusses the motivation and some the lessons we learned along the way.
Managing GraphQL DataLoaders at Scale
At Yelp, we use GraphQL to provide data for our React webapps. The GraphQL Server is deployed as a public gateway that wraps hundreds of internal HTTP endpoints that are distributed across hundreds of services.
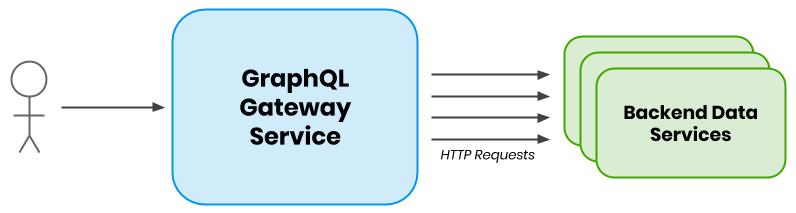
GraphQL Request Diagram
DataLoaders
DataLoaders provide an important caching/optimization layer in many GraphQL servers. If you aren’t already familiar with this pattern, check out this excellent blog post by Marc-André Giroux that covers it in more detail.
Without DataLoaders
Here’s what a Yelpy GraphQL request might do without DataLoaders:
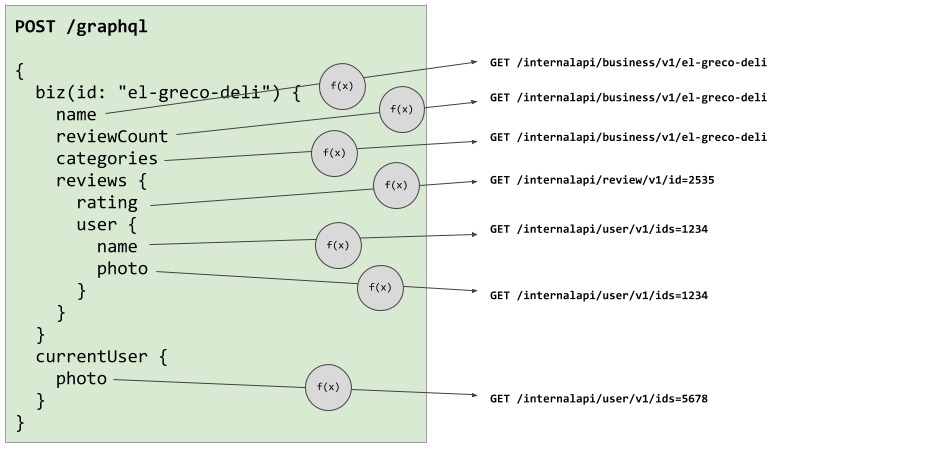
Resolver logic without DataLoaders 😱
Here we can see resolver methods naively making individual upstream requests to fetch their data.
Without the batching and caching features that DataLoaders provide, we could imagine getting into a sticky situation where we issue too many requests and accidentally DoS ourselves.
With DataLoaders
So let’s wrap these HTTP endpoints with DataLoaders:
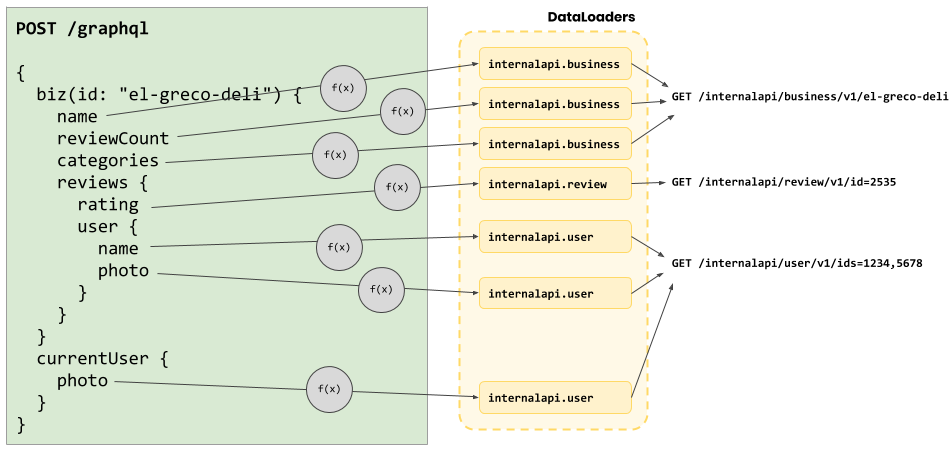
Resolver logic with DataLoaders 😎
In this world, resolvers talk to DataLoaders instead of directly making a network request. The built-in batching and caching logic allows us to greatly cut down on the number of internal API calls we’re making! 🎉
This approach pairs well with the pattern of leaf node resolvers making their own data fetching calls, as described in this blog post.
Scaling it up
In general, this pattern works great. When we go beyond wrapping a few endpoints, we risk running into some challenges in managing the DataLoader layer:
- “Where do I get data from now?!”
- “What does the DataLoader interface look like? How do I maintain type safety?”
- “How do I implement the DataLoader for this endpoint?”
Challenge #1 - Where do I get data from now?
The data available from our endpoints is well understood. All resources are defined by a swagger specification, allowing developers to browse all available endpoints and the data they expose.
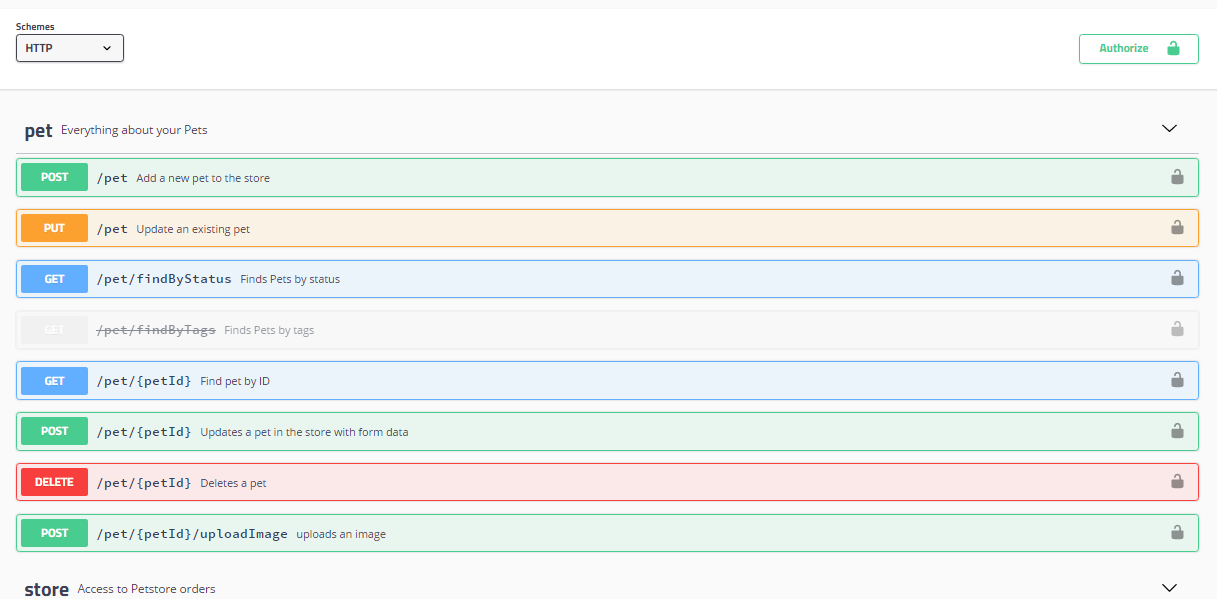
Browsing API endpoints with Swagger UI. Image from https://swagger.io/tools/swagger-ui.
When implementing a resolver method, this makes it easy to know where to fetch data from - just call the corresponding generated method.
Endpoints vs DataLoaders
Adding DataLoaders introduces a layer of indirection. If we were to manually define the DataLoaders and ask developers to call those instead, how would they know which DataLoader to call?
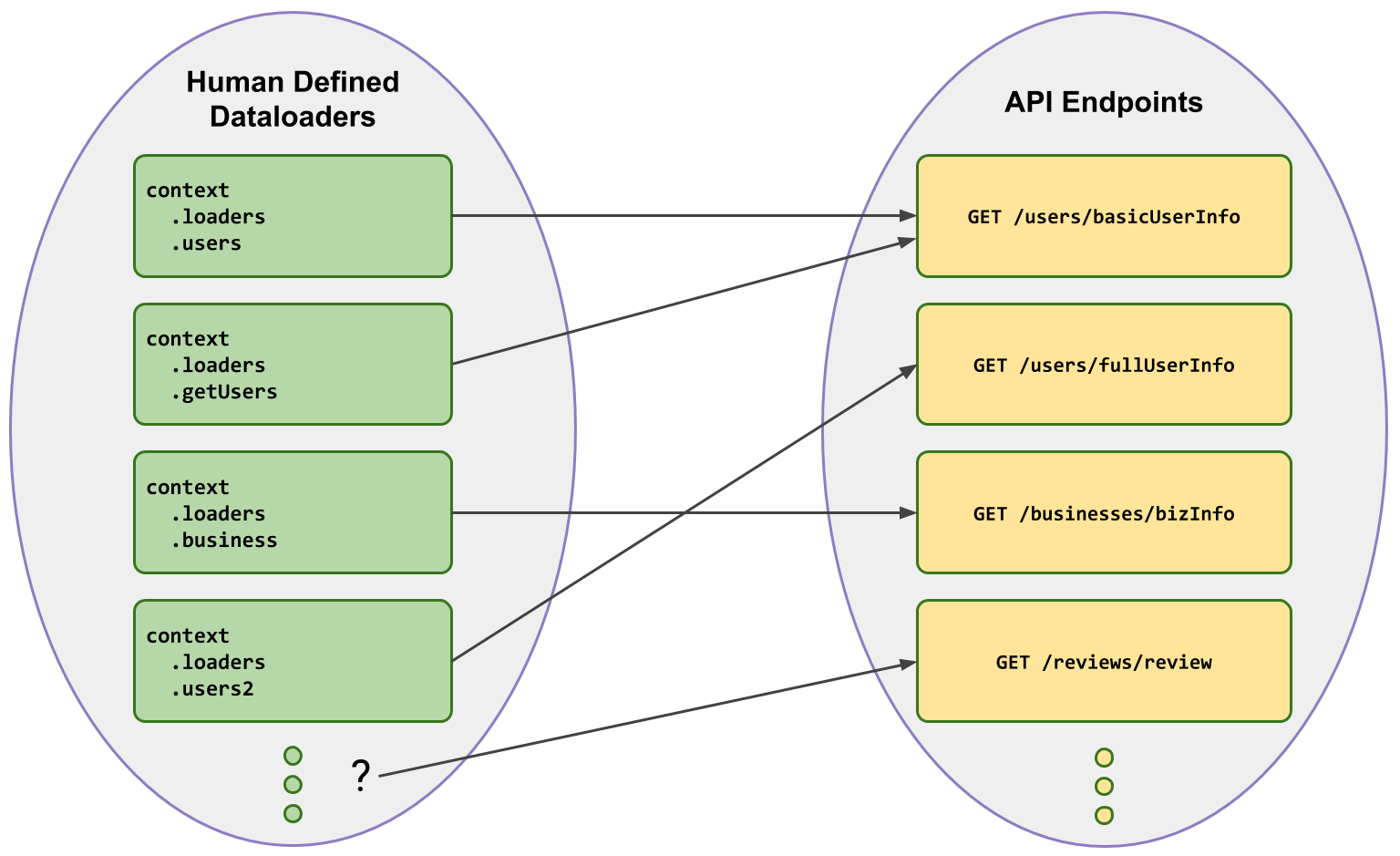
Human-defined DataLoaders
It could be tempting to create a DataLoader with a nice name like users - but
which of our many endpoints that serve user info would this wrap?
And do we end up accidentally wrapping the same endpoint twice (thereby losing out on some batching ability)?
📣 Relying on a human-defined structure of DataLoaders that is different to an existing set of endpoints introduces friction and risks loss of batching behaviour.
We can fix this by asserting that the shape of DataLoaders is a 1:1 mapping to our resources:
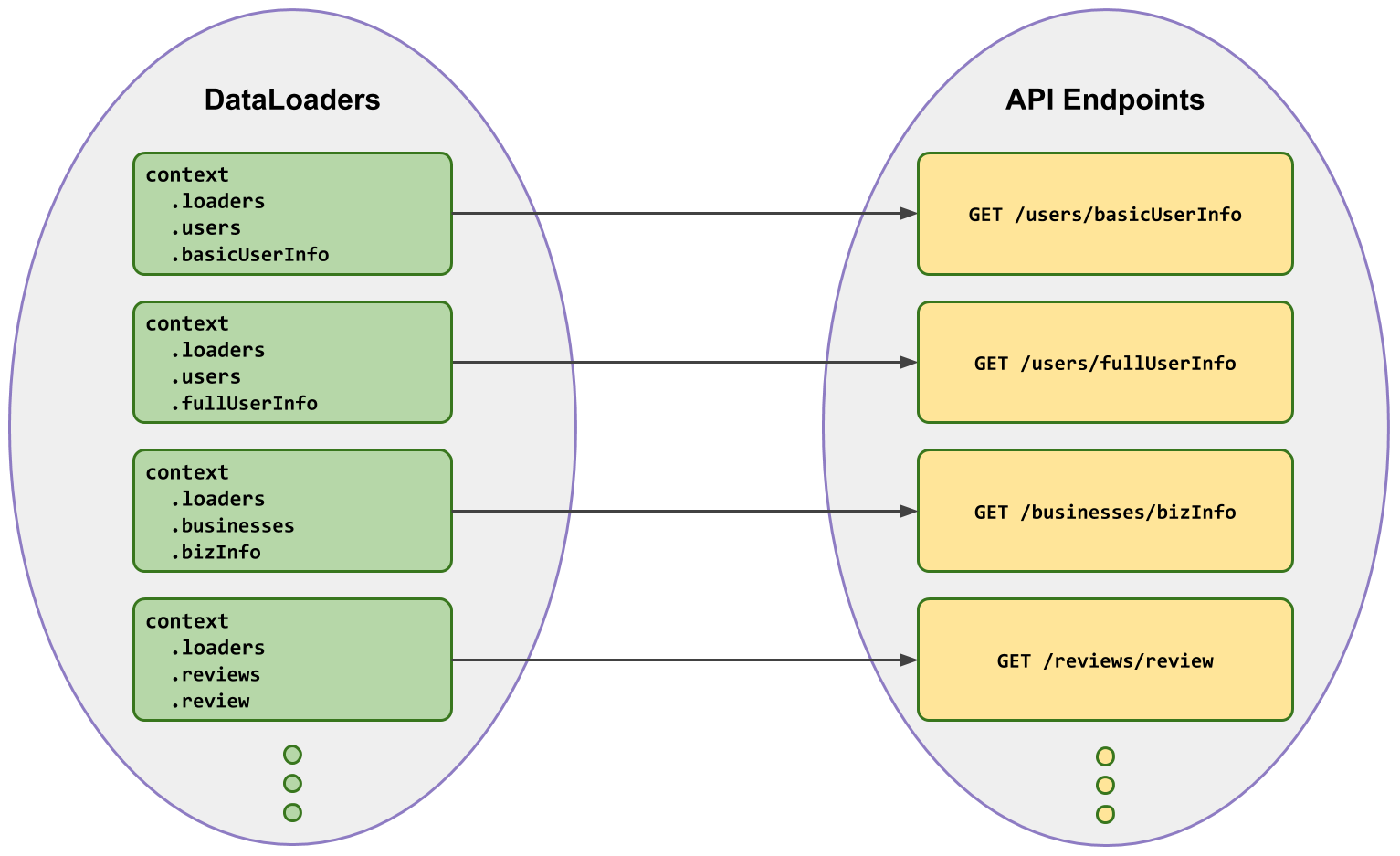
DataLoaders with a 1:1 mapping to resource
Enforcing that the shape (and method names) of the DataLoader object maps 1:1 with the underlying resources makes things predictable when figuring out which DataLoader to use.
📣 We want developers to think in terms of the already familiar, well-documented underlying resources, instead of DataLoaders.
Challenge #2 - What does the DataLoader interface look like? How do I maintain type safety?
Resources come in all shapes and sizes. Some endpoints use a batch interface, some don’t guarantee ordering. Perhaps the response object is nested and needs to be unwrapped etc…
Figuring out the argument/return types of the DataLoader and correctly transforming the interface presents another fun challenge to DataLoader authors.
For example, consider the following batch resource that returns a list of users:
getBasicUserInfo({
user_ids: Array<number>,
locale: string,
include_slow_fields: ?boolean
}) => Promise<Array<UserInfo>>
In our resolvers, we only need to grab a single user object at a time. We should be able to request a single user object from the corresponding DataLoader.
That means we need to map the interface of the DataLoader in the following ways:
| Underlying Resource | DataLoader .load function |
|
|---|---|---|
| Argument | Object containing an Array of user_ids. |
Object containing a single user_id |
| Return | Array of UserInfo objects. |
Single UserInfo object. |
With this approach, the interface for calling the DataLoader version of the resource looks like this:
getBasicUserInfo.load({
user_id: number,
locale: string,
include_slow_fields: ?boolean,
}) => Promise<UserInfo>
Implementing the interface transformation logic consistently and correctly can be hard. Subtle, unexpected differences can cause friction for developers.
📣 We want to maintain a consistent mapping from Resource to DataLoader interface, in order to make things predictable for resolver authors.
Remember the types
If the server codebase uses static types - TypeScript (or in Yelp’s case, Flow), we must also define a type signature for the DataLoader. For our case above, it would look something like this:
DataLoader<
{|
user_id: number,
locale: string,
include_slow_fields: ?boolean,
|},
UserInfo,
>
Transforming the types to match the implementation logic and keeping them in sync presents an additional concern for DataLoader authors.
Challenge #3 - How do I implement the DataLoader for this endpoint?
Writing the DataLoaders over many endpoints results in a lot of imperative boilerplate code that requires an understanding of how the endpoint is implemented.
Here’s what the implementation for the DataLoader over our getBasicUserInfo
endpoint above might look like:
new DataLoader(keys => {
let results;
try {
results = userApi.getBasicUserInfo({
user_ids: keys,
include_slow_fields: false,
locale: 'en_US',
});
} catch (err) {
return Promise.reject(err);
}
// Call a bunch of helper methods to tidy up the response
results = reorderResultsByKey(results, 'id');
results = ...
return results;
}
Yes, we’re totally cheating here! The keys argument here
represents the list of user_ids directly - not a list of objects of arguments
to the resource. This is a decision we might make for the sake of simplicity in
implementing the DataLoader.
In addition to calling the underlying resource, we might also have to deal with:
- Error handling
- Figuring out the argument(s) to the resource from
keys - Normalizing the response shape
- Any other extra logic (e.g. request logging)
This can get pretty tedious when copied and pasted hundreds of times for different endpoints. And since each endpoint could be implemented slightly differently, each DataLoader implementation might be subtly different too.
Since the DataLoader interface is not guaranteed to be predictable, developers have to understand how the DataLoader is implemented, and how it differs from the underlying resource in order to use it.
Dealing with multiple parameters
Consider the getBasicUserInfo DataLoader above - we cheated by never including
include_slow_fields and just using user_ids for keys.
If we want to offer the full flexbility of the underlying resource, we need to
change the getBasicUserInfo DataLoader to use the signature suggested above:
DataLoader<
{|
user_id: number,
locale: string,
include_slow_fields: ?boolean,
|},
UserInfo,
>
Inside of our batch function, keys now becomes a list of objects that looks
like this:
[
{ user_id: 3, include_slow_fields: false, locale: 'en_US' },
{ user_id: 4, include_slow_fields: true, locale: 'en_US' },
{ user_id: 5, include_slow_fields: false, locale: 'en_US' },
]
We need to coalesce these objects so we can make a batched call to
userApi.getBasicUserInfo. It may be tempting to write logic that looks
something like this:
userApi.getBasicUserInfo({
user_ids: keys.map(k => k.user_id),
include_slow_fields: ???,
locale: ???,
})
What would you put for include_slow_fields or locale?
We can’t naively assume the value for keys[0].include_slow_fields, because this
would be unsafe - the second call to .load didn’t request “slow_fields”, but
would receive it, slowing down the whole request - oops!
In this case, we’d have to make two calls to userApi.getBasicUserInfo, and
chunk up the requests accordingly:
userApi.getBasicUserInfo({ user_ids: [3, 5], include_slow_fields: false, locale: 'en_US' });
userApi.getBasicUserInfo({ user_ids: [4], include_slow_fields: true, locale: 'en_US' });
📣 DataLoader authors must take care when coalescing the keys input to ensure correctness in the .load response.
Summary of issues
We have hundreds of internal HTTP API endpoints we may wish to call in GraphQL. Manually writing the DataLoader layer proved to be a significant pain point for the following reasons:
- Implementing the DataLoader batch function logic requires knowledge of the underlying resource and can be hard to implement correctly.
- There’s no guarantee that the shape of the DataLoaders / names of the loaders map perfectly to the endpoints, making them hard to find.
- We risk duplicate loaders being made for the same endpoint due to (2)
- The input / return types of the loaders are manually typed, requiring extra overhead and custom types
- The interface of a DataLoader is separate to the endpoint it’s wrapping, and can be arbitrarily different.
- If the endpoint changes upstream, we have to manually update the DataLoader implementation.
Yikes! After dealing with this for a while, we eventually decided to do something about it :)
Given that there’s a finite amount of variation in the way our endpoints are implemented, this looked it could be a job for codegen…
🤖 dataloader-codegen
dataloader-codegen is a tool we built to automagically generate the DataLoaders used in our GraphQL Server.
We’re excited to announce the release of this tool publicly. Check out the project on GitHub:
https://github.com/Yelp/dataloader-codegen

https://github.com/Yelp/dataloader-codegen
It works by passing in a config file that describes a set of resources - e.g.
resources:
getUserInfo:
docsLink: https://yelpcorp.com/swagger-ui/getUserInfo
isBatchResource: true
batchKey: user_ids
newKey: user_id
getBusinessInfo
docsLink: https://yelpcorp.com/swagger-ui/businessInfo
isBatchResource: false
...
From this, we can generate our DataLoaders at build time:

By letting a tool do the work of writing the DataLoaders, we can solve the issues described above. In particular, dataloader-codegen gives us:
- 🤖 Generated DataLoader implemenations
- ✨ Predictable DataLoader interfaces
- 🤝 1:1 mapping of resource to DataLoader
- 🔒 Type safety of the DataLoaders is preserved
Here we can see Flow complaining about an invalid property passed to a generated DataLoader:
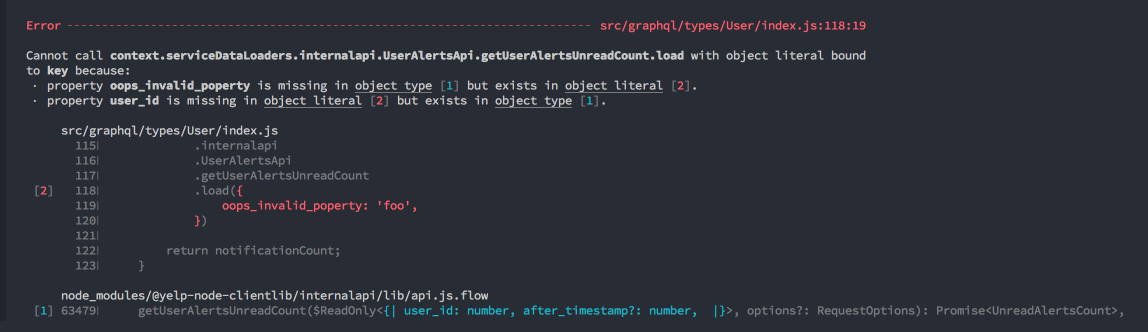
Overall, dataloader-codegen has allowed us to remove a lot of boilerplate code in our server, save time, and reduce friction in dealing with DataLoaders.
For more information about how dataloader-codgen works and how to use it in your project, check out the project on GitHub!
Need help getting set up or have any feature requests for dataloader-codegen? Let us know by opening an issue!
Written By
Mark Larah, Software Engineer (@mark_larah)
Acknowledgments
Thanks to the following folks for contributing internally to dataloader-codegen!
- Ryan Ruan, Software Engineer (@ryanruanwork)
- Jack Guy, Software Engineer