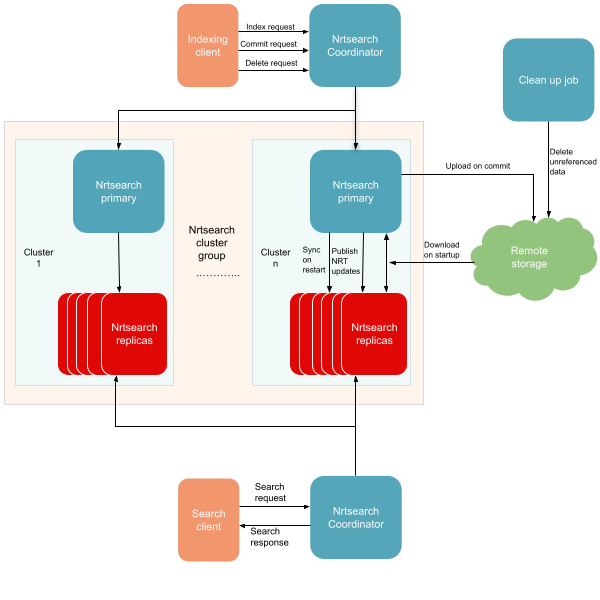
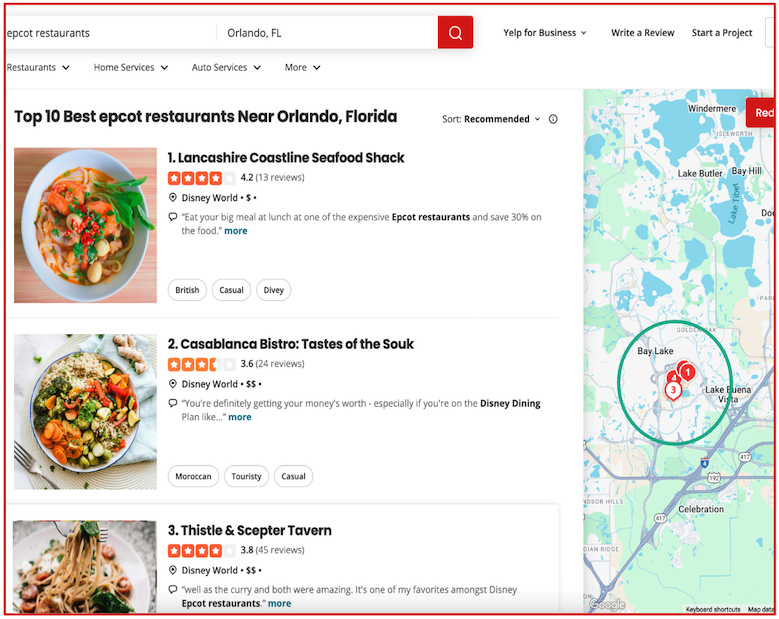
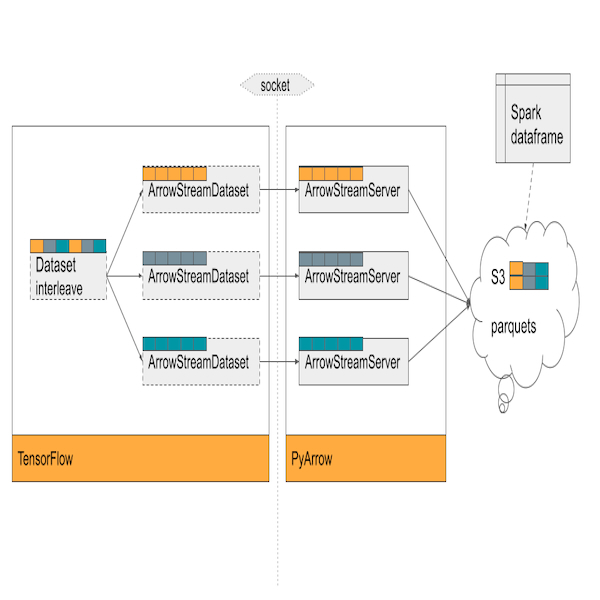
Exploring CHAOS: Building a Backend for Server-Driven UI

-
Jonathan Baird, Software Engineer; Xin Shen, Software Engineer
- Jul 8, 2025
A little while ago, we published a blog post on CHAOS: Yelp’s Unified Framework for Server-Driven UI. We strongly recommend reading that post first to gain a solid understanding of SDUI and the goals of CHAOS. This post builds on those concepts to delve into the inner workings of the CHAOS backend and how it generates server-driven content. To briefly recap, CHAOS is a server-driven UI framework used at Yelp. When a client wants to display CHAOS-powered content, it sends a GraphQL query to the CHAOS API. The API processes the query, requests the CHAOS backend to construct the configuration,...