Towards Building a High-Quality Workforce with Mechanical Turk

-
Paul W. Search Data-Mining Engineer
- Feb 18, 2011
In addition to having written over 15 million reviews, Yelpers also contribute hundreds of thousands of business listing corrections each year. Not all of these corrections are accurate, though, and there are quite a few jokers out there (e.g. suggesting the aquariums category for popular seafood restaurants… very funny!). Yelp is serious about the correctness of business listings, so in order to efficiently validate each and every change, we’ve turned to Amazon’s Mechanical Turk (AMT) as well as other automated methods. We recently published a research paper [1] at the NIPS 2010 Workshop on Computational Social Science and the Wisdom of Crowds reporting on our experiences.
Vetting Workers On Test Tasks
Our experiences agree with several other studies in finding that the AMT workforce has many high-quality workers but also many spammers who don’t perform tasks reliably. In particular, only 35.6% of workers passed our basic multiple-choice pre-screening test. We used expert-labeled corrections in order to test worker performance and found that the variance of worker accuracies was very high:
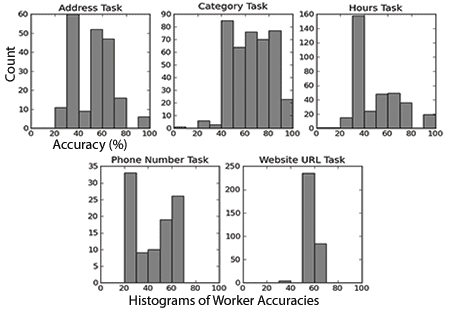
Please see our paper for a full discussion of our observations. Previous studies have proposed mechanisms to correct for the sort of worker biases we observed. However, these mechanisms correct results as a post-processing step after workers have been paid for completing all tasks. Given our experiences and financial goals, we find that a useful mechanism must vet workers online as they complete tasks.
Naïve Bayes Classifier Bests Categorization Task
As highlighted in a recent MIT Technology Review article, one of the notable results of our study is that a Naïve Bayes classifier trained on Yelp reviews outperformed AMT workers on a business categorization task. Naïve Bayes classifiers have been highly successful in various domains from email spam detection to predicting gene expression. We trained and evaluated our classifier on over 12 million reviews and business names using our open source mrjob framework and compared its prediction performance to that of our workforce. Using a combination of the classifier and simple heuristics to clean up common misclassifications, the classifier outperformed workers for both accepting and rejecting category changes.

While we might expect traditional machine learning techniques to perform well on our particular document categorization task, other tasks such as phone number verification are more readily crowdsourced. Furthermore, in the future we may build upon techniques pioneered in other studies that use crowdsourced labels to train classifiers to perform well on hard problems.
Lessons Learned
We learned a ton at the NIPS Workshop and are very thankful for a number of very helpful comments. Much of the crowdsourcing research presented at the workshop illustrates that very careful attention to the incentive structure of AMT tasks is critical to attracting and retaining the best workers. In particular:
- John J. Horton shows that task pricing is critical to attracting high-output workers. Some AMT workers have wage targets, and AMT Requesters who only offer low wages may have trouble retaining the best workers.
- Winter Mason shows how, for small tasks similar to those in our study, quota systems elicit more effort than piece-rate pay. Workers put forth more effort when small tasks are grouped together and require workers to form a plan of attack to complete work on time. Furthermore, making tasks collaborative (e.g. where workers can work together on a result or communicate in a chat room) may also improve worker performance. Some Workers Take Longer Than Others
We would like to expand on a fact mentioned in the paper that has led to some misconceptions about the rates at which we paid workers. In the paper, we report that the median worker task completion time was 5 minutes and that workers were paid about USD$0.05 per task. First, the reported completion time statistic is improperly represented: we observed a median HIT completion of 5 minutes, where each HIT included between two to four tasks. Second, the modal HIT completion time was 60 seconds overall and 90 seconds for workers with low completion time variance. Given our HIT pricing, there were many workers who earned between USD$6 and USD$9 per hour for their work. We chose our pricing in part based upon the prices of other HITs posted on AMT.
Though many workers completed HITs quickly, we question the accuracy and usefulness of AMT’s recorded completion times because we observed a very high variance in this data. The histogram below shows that some workers accepted tasks hours before submitting answers.

Workers tended to complete batches of test tasks within a day or two after we posted them on AMT. We rarely rejected work, so many workers may have seen our tasks as a guaranteed source of income. Assuming that AMT’s completion time records are accurate, we hypothesize that some workers hoard batches of tasks far in advance of actually completing them.
Acknowledgements
We would like to again thank the workshop attendees and the anonymous reviewers for their helpful comments. We would also like to thank Professor Jenn Wortman Vaughan for her feedback on a preliminary draft of this work. Please send any questions or comments to the corresponding author.
[1] Wais, P., Lingamneni, S., Cook, D., Fennell, J., Goldenberg, B., Lubarov, D., Marin, D., Simons, H. “Towards Building a High-Quality Workforce with Mechanical Turk.” In NIPS Workshop on Computational Social Science and the Wisdom of Crowds, Whistler, BC. 2010. [citeulike/bibtex]