Event Listing Classifier: an Intern Story

-
Jim B., Engineering Manager
- Apr 4, 2013
What projects do interns work on? What are some of the machine learning algorithms we use to solve real world problems? Do interns work in teams solving critical problems, or just do small research tasks? These are some of the questions I frequently get when talking with candidates, so I invited Shengwei L., former intern and now full-time employee, to talk about one of his projects. As you can see, interns at Yelp get to apply the principles they learned in school to make Yelp better for millions of people. They sit alongside full-time members and take responsibility for projects that can span multiple teams and systems. But you don’t have to take my word for it, let’s hear from Shengwei!
Yelp events are awesome, and we enjoy throwing great events around the world. After events, which are usually free for attendees, Community Managers create a new event listing specifically for their party so that all the participants can write reviews of the event itself instead of posting their reviews of an event onto the business listing that is only for the venue. It would be misleading to see so many reviews on a business listing if they were for a party and not a standard consumer experience with the business.
In Yelp’s system, those event listings are essentially the same as other real business listings, such as a restaurant or hair dresser. Because event listings are mainly about past events, they are not useful for ordinary users. Hence we want to remove them from search after events are over and people have had time to review them. However, no one’s perfect, and we may occasionally lose track of some event listings and they will show up in search results. In order to improve the information/noise ratio for our users, we have implemented a system to automatically detect such listings so that we may exclude as many event listings as possible from search results.
It can be tedious for a human to pick out a few event listings we have missed from numerous real business listings, but computers are good at screening large datasets in a short amount of time. Before tracking dogs start looking for a suspect, they need to sniff some of the suspect’s belongings to learn about the smell. Similarly, a computer needs to learn what an event listing event looks like, as opposed to a real business listing, before it can differentiate them on its own. This is essentially a classification problem. Naive Bayes classifier is broadly used for classification, and it is quite effective for document classification, such as spam email detection. It is based on the Bayes’ theorem, in the form of
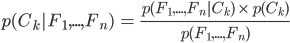 , where
, where
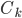 presents different categories, and
presents different categories, and
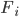 denotes distinctive features that could possibly appear. Translated into more readable English, that’s
denotes distinctive features that could possibly appear. Translated into more readable English, that’s
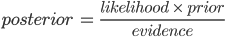 . In our case, classes are “business” and “event,” and the features are explained later in this post.
. In our case, classes are “business” and “event,” and the features are explained later in this post.
Given an instance with a fixed set of features, the denominator
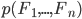 is a constant for different categories. Therefore,
is a constant for different categories. Therefore,
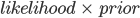 is sufficient to categorize the instance based on certain features. This simplification can be exploited to reduce computation effort. Moreover, as a fundamental assumption, features
is sufficient to categorize the instance based on certain features. This simplification can be exploited to reduce computation effort. Moreover, as a fundamental assumption, features
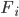 should be independent of each other, and hence
should be independent of each other, and hence
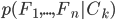 is equivalent to
is equivalent to
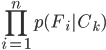 . As a consequence, the probability of the category of one instance based on certain features is assessed by
. As a consequence, the probability of the category of one instance based on certain features is assessed by
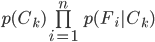 , and we take the category for which the score is higher as the instance’s category.
, and we take the category for which the score is higher as the instance’s category.
Our wonderful summer intern Te T. implemented a naive Bayes classifier using log-likelihood based on both multinomial and Bernoulli distributions (known as event model). This classifier has been an instrumental tool in the analysis of our massive data, such as check-in tips. I decided to also use it for listing classification, because event listings exhibit some obvious patterns (i.e., features) that ordinary business listings usually do not have. For example, the listing names typically contain certain keywords (such as “yelp,” “elite” and “event”), and the creators are normally Community Managers. The naive Bayes classifier uses these patterns like the tracking dog uses smells: it can now sniff out those event listings created for elite events. After scrutiny of many samples and thanks to suggestions from team members, especially Artem A., Marty F., and Zeke K., we finalized about 10 features, and they worked well in experiments with Bernoulli distribution as the event model.
After the system was deployed, we spotted a number of listings for events that were created in the early days and not correctly tracked. In the meantime, we regularly check all newly created business listings to see if we have missed classifying any listings for events. We are not blindly marking business listings relying on the automatic classification. Human verification is also involved to make sure we do not mistakenly exclude real business listings.
Going forward, we will continue to monitor and analyze the classification result, particularly false positive and false negative cases, trying to find out more features we may exploit. In addition, since we utilize Bernoulli distribution as the event model for features, there are thresholds to determine true or false value of features based on experiments with samples. We may also tweak the thresholds here and there according to analysis of the classification result.
This was just one of my intern projects. Without support from my team members and help from other groups, I could hardly figure out all the parts I would need to accomplish this. I really enjoyed the progress, interacting with experienced industry veterans and other awesome interns. It is a great approach to acquire hands-on experience and transfer the knowledge learned in class into a working piece in the real world.