Building the Wordmap

-
Jim B., Engineering Manager
- Jul 11, 2013
Mark W. and Chris C. are part of the team behind our recently launched Wordmap, and today they give us a peek behind the scenes. Read on to learn how we’re helping people with a critical need: avoiding hipsters (oh yea, and connecting with great local businesses!)
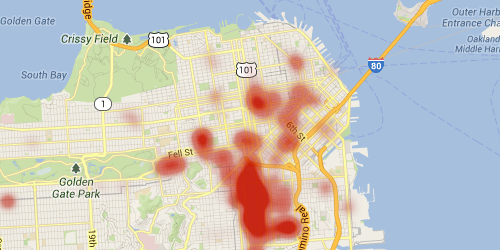
We have a lot of data here at Yelp, and we’re always thinking about cool new ways to explore it. One recent example is the Wordmap, a visualization of geographical patterns of word usage in Yelp reviews across a city. We’ll step through how we built this feature: how we transformed our review data into heat maps of word activity, and how we store and display the data on the front end.
mrjob
How do we make sense of the over 39 million reviews Yelpers have contributed to the site? mrjob! mrjob is an open source project released by Yelp built to provide a way for engineers to run log processing jobs on the hadoop cluster at Yelp while retaining all the benefits of working in Python. Yelp now uses mrjob exclusively with Amazon’s EMR framework to power all the large data processing batches. With mrjob, we were able to quickly tokenize reviews into individual words and then add them up for each business.
In pseudo code:
function map(review):
tokenize into words
discard stop_words
for each word:
emit tuple(business, word), 1
function reduce_word((business, word), partial_count):
emit business, tuple(word, sum(partial_count))
function reduce_business(business, (word, count)):
# emit business and a dictionary of word and counts
emit business, dict(word, count)
Data normalization
We wanted to avoid the common pitfall of geographic heatmaps, so we couldn’t simply plot the raw word counts over a map. Instead, we calculated the number of times the word was mentioned above average at a business. This helps get at the core of the idea, which is to find the most hipster-y/bacon-y/etc neighborhoods. If a business had 1000 reviews, but 20 mentions of a word, that wasn’t as impressive as if a business had 100 reviews but 10 mentions of a word.
Since we had the count of each word for every business, we could calculate the aggregate count for each word by city, and from there, the total word count for each city. This allowed us to find the average frequency of a word in each city.
We then subtracted the number of mentions of a word from the expected number of mentions based on the city-wide frequency of the word and the number of words in reviews a business had.
Since the word counts are consistent with a power-law distribution, to arrive at the final Wordmap we applied a numerical transformation to flatten the data. This places the word counts along a linear and more human relatable scale.
Word selection
We selected some of the words based on how visually interesting their patterns were across cities. For local knowledge we relied on our Community Managers in each city for cool and unique words (for example, “fish and chips” in London). We also discovered some words based on how much more frequently certain cities used a word over the rest of the world (for example, “espresso” in Seattle).
Hosting and displaying the data
Once we had our data formatted in terms of locations and weights, we used the Google Maps APIand its Heatmap Layer functionality to render the word density plot. The more mentions above average a word had for a business, the greater the intensity of the heatmap at that location. Where businesses with high intensity densely cluster, the Wordmap is a deep red. We found that a gradient across opacity created a more compelling view of our data than one across color, since the default sharp boundary at zero makes less sense given how our data is normalized.
We also had to choose how to make it available to the front-end. Because the data is large and rarely changes, it didn’t make sense to store it in an application database. Instead, we formatted the data as JSONP and hosted it in static JS files on our CDN via S3. The JavaScript powering the Wordmap exposes a callback which every script file references as soon as it is loaded. This approach allowed us to decouple the application from the data, so that either can be updated independently.
What’s next
We’ve got a lot more ideas brewing for finding new meaning in the rich content contributed by our passionate users. If building the next great way to explore our data sounds like a fun challenge, we’d love to have you here…
Thanks to engineer Mark W., front end engineer Molly F., designer Stephen V., and data scientist Chris C.!