Scaling Elasticsearch to Hundreds of Developers

-
Joseph Lynch, Software Engineer
- Nov 12, 2014
Yelp uses Elasticsearch to rapidly prototype and launch new search applications, and moving quickly at our scale raises challenges. In particular, we often encounter difficulty making changes to query logic without impacting users, as well as finding client library bugs, problems with multi-tenancy, and general reliability issues. As the number of engineers at Yelp writing new Elasticsearch queries grew, our Search Infrastructure team was having difficulty supporting the multitude of ways engineers were finding to send queries to our Elasticsearch clusters. The infrastructure we designed for a single team to communicate with a single cluster did not scale to tens of teams and tens of clusters.
Problems we Faced with Elasticsearch at Yelp
Elasticsearch is a fantastic distributed search engine, but it is also a relatively young datastore with an immature ecosystem. Until September 2013, there was no official Python client. Elasticsearch 1.0 only came out in February of 2014. Meanwhile, Yelp has been scaling search using Elasticsearch since September of 2012 and as early adopters, we have hit bumps along the way.
We have hundreds of developers working on tens of services that talk to tens of clusters. Different services use different client libraries and different clusters run different versions of Elasticsearch. Historically, this looked something like:
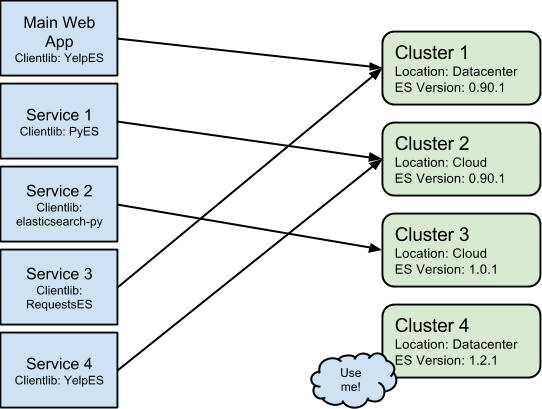
Figure 1: Yelp Elasticsearch Infrastructure
What are the Problems?
- Developers use many different client libraries, we have to support this.
- We run multiple version of Elasticsearch, mostly 0.90.1, 1.0.1 and 1.2.1 clusters.
- Multi-tenancy is often not acceptable for business critical clients because Elasticsearch cannot offer machine level resource controls and its JVM level isolation is still in development.
- Having client code spread over a multitude of services and applications makes auditing and changing client code hard.
These problems all derive from Elasticsearch’s inevitably wide interface. Elasticsearch developers have explicitly chosen a wide interface that is hard to defend due to lack of access controls, which makes sense given the complexity they are trying to express with an HTTP interface. However, it means that treating Elasticsearch as just another service in a Service Oriented Architecture rapidly becomes difficult to maintain. The Elasticsearch API is continually evolving, sometimes in backwards incompatible ways, and the client libraries built on top of that API are continually changing as well, which ultimately means that iteration speeds suffer.
Change is Hard
As we scaled usage of Elasticsearch here at Yelp, it became harder and harder to change existing code. To illustrate these concerns let us consider two examples of developer requests on the infrastructure mentioned in Figure 1:
Convert Main Web App to use the RequestsES Client Library
This involves finding all the query code in our main web app and then, for each one:
- Create secondary paths that use RequestsES
- Setup RequestBucketer groups.
- Write duplicate tests.
- Deploy the change.
- Remove duplicate tests.
We can make the code changes fairly easily but deploying our main web app takes a few hours and we have a lot of query code that needs to be ported. This would take significant developer time due to the amount of complexity involved in deploying our main web application. The high developer cost of changing this code outweighs the infrastructure benefits, which means this change is not pursued.
Convert Service 4 to elasticsearch-py and move them to Cluster 4
Service 4’s SLA has become stricter and they can no longer tolerate the downtime caused by Service 1’s occasionally expensive facet queries. Service 4’s developers also want the awesome reliability features that Elasticsearch 1.0 brought such as snapshot and restore. Unfortunately, our version of the YelpES client library does not support 1.X clusters, but the official Python client does, which is ok because engineers in Search Infrastructure are experts in porting YelpES code to the official Python client. Alas, we do not know anything about Service 4. This means we have to work with the team that owns Service 4, have them build parallel paths, and tell them how to communicate with the new cluster. This takes significant developer time because of coordination overhead between our teams.
It is easy to see that as the number of developers grows, these development patterns just do not scale. Developers are continually adding new query code in various services, using various client libraries, in various programming languages. Furthermore, developers are afraid to change existing code because of long deployment times and business risk. Infrastructure and operations engineers must maintain multi-tenant clusters housing clients with completely different uptime requirements and usage patterns.
Everything about this is bad. It is bad for developers, infrastructure engineers, and operations engineers, and it leads to the following lesson learned:
Systems that use Elasticsearch are more maintainable when query code is separated from business logic
Our Solution
Search Infrastructure at Yelp has been employing a proxy service we call Apollo to separate the concerns of the developers from the implementation details so that now our infrastructure looks like this:
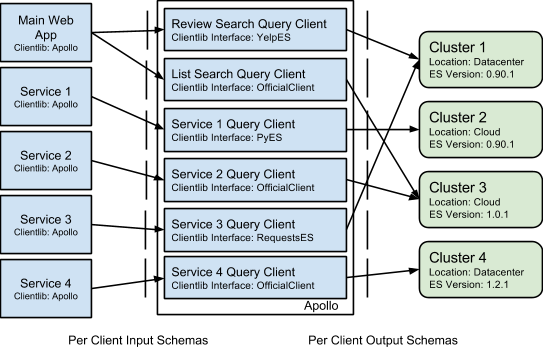
Figure 2: Apollo
Key Design Decisions
Isolate infrastructure complexity
The first and foremost purpose of Apollo is to isolate the complexity of our search infrastructure from developers. If a developer wants to search reviews from their service, they post a json blob:
{"query_text": "chicken tikka masala", "business_ids": [1, 2, 3] }
to an Apollo url:
apollo-host:1234/review/v3/search
The developer need never know that this is doing an Elasticsearch query using the elasicsearch-py client library, against an Elasticsearch cluster running in our datacenter that happens to run Elasticsearch version 1.0.1.
Validation of all incoming and exiting json objects using json-schema ensures that interfaces are respected and because these schemas ship with our client libraries we are able to check interfaces in calling code, even when that calling code is written in Python.
Make it easy to iterate on query code
Every query client is isolated in their own client module within Apollo, and each client is required to provide an input and output schema that governs what types of objects their client should accept and return. Each such interface is bound to a single implementation of a query client, which means that in order to write a non-backwards compatible interface change, one must write an entirely new client that binds to a new version of the interface. For example, if the interface to review search changes, developers write a separate module and bind it to /review/v4/search, while continuing to have the old module bound to /review/v3/search. No more “if else” experiments, just self contained modules that focus on doing one thing well.
A key feature of per module versioning is that developers can iterate on their query client independently and the Apollo service is continuously delivered, ensuring that new query code hits production in tens of minutes. Each client can also be selectively turned off or redirected to another cluster if they are causing problems in production.
As for language, we chose Python due to Yelp’s mature Python infrastructure and the ease in which consumers could quickly define simple and complicated query clients. For a high throughput service like Apollo, Python (or at least Python 2) is usually the wrong choice due to high resource usage and poor concurrency support, but by using the excellent gevent library for concurrency and the highly optimized json parsing library ujson, we were able to scale Apollo to extremely high query loads. In addition, these libraries are all drop-ins so clients do not have to design concurrency into their query logic, it comes for free. At peak load Apollo with gevent can do thousands if not tens of thousands of concurrent Elasticsearch queries on a single uwsgi worker process, which is pretty good compared to the single concurrent query that normal Python uwsgi workers can achieve.
Make it easy to iterate on infrastructure
Because the only thing that lives in Apollo is code that creates Elasticsearch queries, it is easy to port clients to new libraries or move their client to a different cluster in a matter of minutes. The interface stays the same and end to end tests ensure functionality is not broken.
Another key capability is that from the start we designed these modules to implement a simple interface that is composable. This composable-first architecture has allowed us to provide wrappers like:
SlowQueryLogger: A unary wrapper that logs any slow requests to a log for auditing and monitoring.Tee: A binary wrapper that allows us to make requests to two clients but only wait on results from one of them. This is useful for dark launching new clients or load testing new clusters.Mux: A n-ary wrapper that directs traffic between many clients. This is useful for gradual rollouts of new query code or infrastructure.
As an example, let us assume there are two query clients which differ only in the client library they use and Elasticsearch version they expect: ReviewSearchClient and OfficialReviewSearchClient. Furthermore, let us say our operations engineer has just provisioned a new shiny cluster running Elasticsearch 1.2.1 that lives in the cloud and is ready to be load tested. An example composition of these clients within Apollo might be:
This maps to the following request path:

Figure 3: Life of a Request in Apollo
In this short amount of Python code we achieved the following:
- If any query takes longer than 500ms, log it to our slow query log for inspection
- Send all traffic to a
Muxthat muxes between an old PyES implementation and our new official client implementation. We can change theMuxweights at runtime without a code push - Separately send traffic to a cloud cluster that we want to load test. Do not wait for the result.
Most importantly of all, we never had to worry about which consumers are making review search requests because there is a well defined interface that is well tested. Additionally, because Apollo uses Yelp’s mature Python service stack we have performance and quality metrics that can be monitored for this client, meaning that we do not have to be afraid to make these kinds of changes.
Revisiting developer requests
Now that Apollo exists, making changes goes from weeks to days, which means our organization can continue to be agile in the face of changing developer needs and backwards incompatible Elasticsearch versions. Let us revisit those developer requests now that we have Apollo:
Convert Main Web App to use the RequestsES Client Library
We have to find all the clients in Apollo that the Main Web App queries and implement their interfaces using the RequestsES client library. Then we wire up a Mux for each client that allows us to switch between the two implementations of the interface, deploy our code (~10 minutes) and gradually roll out the new code using configuration changes. From experience, query code like this can get ported in an afternoon. Having minute long deploys to production makes all the difference because it means that you can get multiple pushes to production in one day instead of one week. Also, because the elasticsearch query crafting code is separate from all the other business logic, it is easier to reason about and feel confident in changes.
Convert Service 4 to elasticsearch-py and move them to Cluster 4
We can implement Service 4’s interface using the new client library, re-using existing tests to ensure functional equivalence between the two implementations. Then we set up a Tee to the new cluster to make sure our new code works and the cluster can handle Service 4’s load. Finally, we wait a few days to ensure everything works and then we change the query client to point at the new cluster. If we really want to be safe we can setup a Mux and gradually roll it over. This whole process takes a few days or less of developer time.
Infrastructure Win
Now that Yelp engineers can leverage Apollo, along with our real time indexing system and dynamic Elasticsearch cluster provisioning, they can develop search applications faster than ever. Whereas before Search Infrastructure was accustomed to telling engineers “unfortunately we can’t do that yet”, today we have the flexibility to support even the most ambitious projects.
Since the release of Apollo just a few months ago, we have ported every major Yelp search engine running on Elasticsearch to use Apollo as well as enabled dozens of new features to be developed by other teams. Furthermore, due to the power of Apollo we were able to seamlessly upgrade to Elasticsearch 1.X for a number of our clients where prior to this that would have been nearly impossible given our uptime requirements.
As for performance, we have found that the slight overhead of running this proxy have proved more than worth it in deployment, cluster reconfiguration, and developer iteration time, enabling us to make up for the request overhead by deploying big win refactors that improve performance.
At the end of the day Apollo gives us flexibility, fast deploys, new Elasticsearch versions, performant queries, fault tolerance and isolation of complexity. A small abstraction and the right interface turns out to be a big win.