MySQL @ Yelp

-
Jenni S., Engineering Manager
- Jan 7, 2015
This past November, Yelp Engineering hosted a Bay Area Girl Geek Dinner and I had the pleasure of presenting a brief overview of how Yelp uses MySQL. I received a lot of great questions and wanted to take a few minutes to share the information with our wider blog audience.
Overview: MySQL @ Yelp
Yelp has used MySQL since the beginning, and in more recent years has adopted the Percona fork. We like MySQL because it fits our data needs, is configurable, fast, and scalable. The Percona fork includes performance enhancements and additional features on top of stock MySQL, we have used their training services in the past, and are currently a support customer. MySQL also has a *huge* online community. I love that a quick search using your favorite search engine will quickly get you started down the right path to solving most problems!
A Little More Detail
We’re running roughly 100 database servers between our dev, staging, and production environments. Our database is split up into several functional shards. Different database servers house different data sets, with different tables and schemas, but all of the data for a single table resides within one shard. The InnoDB storage engine provides us with the ability to handle a fair number of concurrent transactions at a time on masters, and we rely upon it for our transactional consistency. To scale database reads, we use MySQL statement-based replication to propagate data from master DBs to local and remote replicas, which reside in 2+ read-only data centers/locations. Our replication hierarchy uses an intermediate master database in each datacenter to reduce replication bandwidth and to facility easy master promotions:
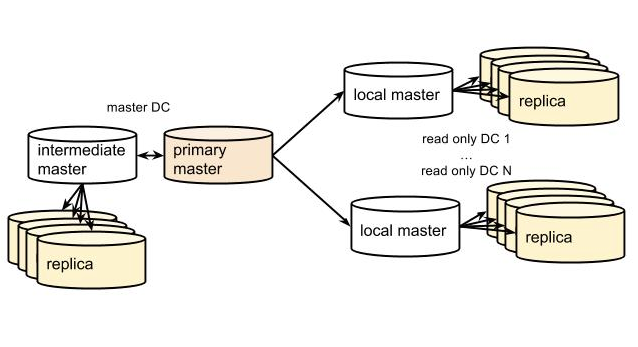
MySQL is also extremely portable, running on almost anything, and has a massive number of variables to tune your performance if you’re inclined. We’re a Python shop, so we use the MySQLdb connector, and SQLAlchemy.
Tools we use with MySQL
At Yelp, we have a saying: “it’s not in production until it’s monitored.” We monitor MySQL with Nagios and Sensu, and graph metrics using Ganglia, Graphite, and Grafana. We also use the Percona Toolkit’s command-line utilities to analyze database query traffic, log deadlocks, collect data during times of database stress, verify the consistency of our data between replicas and MySQL versions, online schema change, and to kill poorly performing queries.
Yelp DBAs
In order to keep Yelp fresh and deliver new features, we push new versions of our application multiple times a day. This means we also have to support frequent schema changes too! There are two rules for our schema changes to keep things moving smoothly:
- They must be backwards-compatible with the previous version of the application
- They must either be online operations, or we must be able to run them using pt-online-schema-change
What’s so important about backwards-compatible schema changes? While I love dropping columns and tables just as much as (if not more!) than the next person, part of pushing often is also being able to safely roll back. If we need to do something like drop a column, we will first deploy code that no longer uses it, take the extra step of renaming the column first, verify that things look good, and then drop the column, each over its own push. We also want to keep in mind that neither database changes nor rolling out a new version of our application happens in a single instant. We always make our database/schema changes before the code deployment part of a push, and there can be a period of time during deployment when two versions of our application are running.
Thus we make our database changes before the code is deployed, and we use pt-online-schema-change to prevent replication delay as the schema change is made. pt-online-schema-change alters a table online by:
- Creating an empty copy of the table to alter
- Running the alter statement against the new, empty copy
- Copying the rows from the original table into the new table
- Replacing the original table with the new one
Yelp DBAs
This wasn’t part of my original presentation but there was an interesting question asked after my talk: do we use an ORM ( Object Relational Mapping) or do we write out all of our SQL as direct queries or stored procedures? As I mentioned above, we do use SQLALchemy and while we have some hand-written queries, we prefer to use the ORM. This debate exists because ORMs can write some, well, interesting (read: awful) queries that can really hurt database performance. However, they also greatly enhance developer productivity! We choose to favor getting new tables and the code that uses them developed and out in the wild quickly, and then iterate from there if we find that specific queries need to be optimized by hand.
We have a couple of practices and/or tools that assist us here:
- Monitoring: we monitor our databases to alert us if application or database timings change
- We have a “ gross query checker,” which I’ve blogged about before: it alerts us to poorly performing queries before we leave the development environment
- We run pt-kill: a tool from the Percona Toolkit that will kill long-running queries in production
What else?
In the slides, you can also find a couple of notes about backups, where to find additional resources when working with MySQL and some book titles I’ve read that I think are worth checking out!
Also, if you’re already a member of the MySQL Community, I will be presenting, and Yelp will be sponsoring a booth, at Percona Live this April. Please come say hi!
The open, supportive community surrounding MySQL fits in well with Yelp Engineering’s culture of collaboration, playing well with others, and technical tenacity. On top of providing the databases, documentation, and tools, it’s important to make sure that our developers have an easy venue to discuss ideas and ask questions. Once a week, the DBA team at Yelp hosts DBA office hours - a time when we’re available to answer any and all database questions, talk about performance, swap ideas, or just generally chat.