Analyzing the Web For the Price of a Sandwich

-
Ben C., Software Engineer
- Mar 20, 2015
I geek out about the Common Crawl. It’s an open source crawl of huge parts of the Internet, accessible for anyone to use. You have full access to the HTML and text of billions of web pages. What’s more, you can scan the entire thing, tens of terabytes, for just a few bucks on Amazon EC2. These days they’re releasing a new dataset every month. It’s awesome.
People frequently use mrjob to scan the Common Crawl, so it seems like a fitting tool for us to use. mrjob, if you’re not familiar, is a Python framework written by Yelp to help run Hadoop jobs locally or on Amazon’s EMR service. Since the Common Crawl is stored in Amazon’s S3, it makes a lot of sense to use EMR to access it.
The Problem
I wanted to explore the Common Crawl in more depth, so I came up with a (somewhat contrived) use case of helping consumers find the web pages for local businesses. Yelp has millions of businesses in its index and we like to provide links back to a business’s own web page wherever possible, but there are plenty of cases where we just don’t have that information.
Let’s try to use mrjob and the Common Crawl to help match businesses from Yelp’s database to the possible web pages for those businesses on the Internet.
The Approach
Right away I realized that this is a huge problem space. Sophisticated solutions would use NLP, fuzzy matching, cluster analysis, a whole slew of signals and methods. I wanted to come up with something simple, more of a proof-of-concept. If some basic approaches yielded decent results, then I could easily justify developing more sophisticated methods to explore this dataset.
I started thinking about phone numbers. They’re easy to parse, identify, and don’t require any fuzzy matching. A phone number either matches, or it doesn’t. If I could match phone numbers from the Common Crawl with phone numbers of businesses in the Yelp database, it may lead to actually finding the web pages for those businesses.
I started planning my MapReduce job:
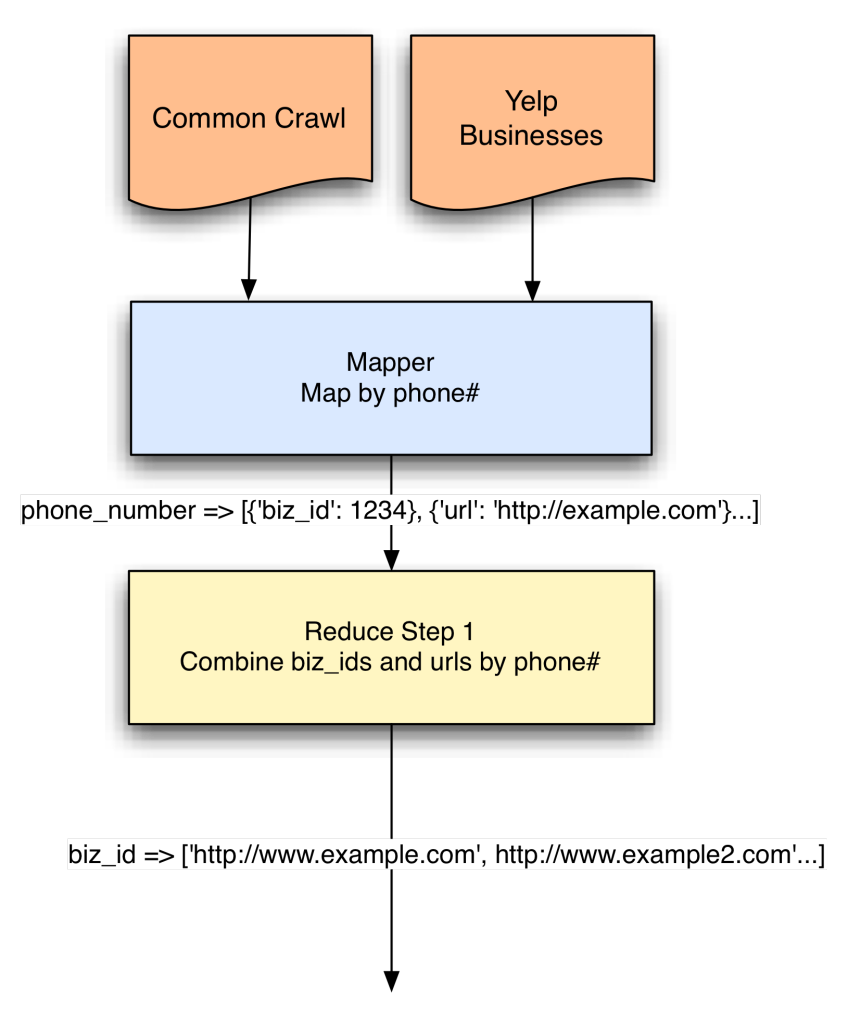
I start with a mapper that takes both Common Crawl WET pages (WET pages are just web page text) and Yelp business data. For each page from the Common Crawl, I parse the page looking for phone numbers and yield the URLs keyed off of each phone number that I find. For the Yelp business data, I yield the ID of the business, keyed off of the phone number that we have on record, which lets me start combining any businesses and URLs that match the same phone number in my reduce step.
Spammy Data
I ran this against a small set of input data to make sure it was working correctly but already knew that I was going to have a problem. There are some websites that just like to list every possible phone number and then there are sites like Yelp which have pages dedicated to individual businesses. A website that simply lists every possible phone number is definitely not going to be a legitimate business page. Likewise, a site like Yelp that has a lot of phone numbers on it is unlikely to be the true home page of any particular business. I need a way to filter these results.
So let’s set up a step where we organize all the entries keyed by domain. That way if it looks like there are too many businesses hosted on that single domain, we can filter them out. Granted this isn’t perfect, it may exclude large national chains, but it’s a place to start.
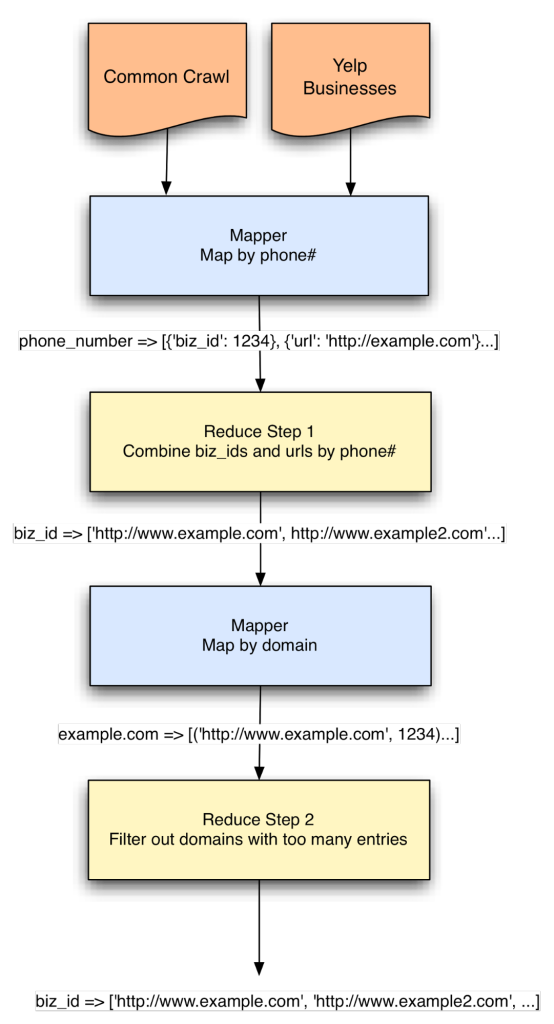
The Input
The Common Crawl data files are in WARC format. The warc python package can help us parse these files, but WARC itself isn’t a line-by-line format that’d be suitable as direct input to our job. Instead, the input to our mapper will be the paths to WARC files stored in S3. Conveniently, the Common Crawl provides a file that is exactly that.
According to the Common Crawl blog, we know that the WET paths for the December 2014 crawl live at:
https://aws-publicdatasets.s3.amazonaws.com/common-crawl/crawl-data/CC-MAIN-2014-52/wet.paths.gz
We’ll supply that path and a path to a similar file of our Yelp dataset to our mrjob:
Here’s an excerpt from the full job that illustrates how we load the WARC files and map them into phone numbers and URLs:
Performance Problem: Distribute Our Input To More Mappers
The default Hadoop configuration assumes that there are many lines of input and each individual line is relatively fast to process. It designates many lines to a single map task.
In this case, given that our input is a list of WET paths, there’s a relatively small amount of line input, but each line is relatively expensive to process. Each WET file is about 150MB so each line actually represents a whole lot more input than just that single line. For best performance, we actually want to dole out each input to a separate mapper.
Fortunately this is pretty easy by simply specifying the input format to NLineInputFormat:
Note that NLineInputFormat will reformat our input a bit. It will change our input lines S3 paths into '\t' so we need to treat our input as tab-delimited key, value pairs and simply ignore the key. MRJob’s RawProtocol can do this:
Identifying Phone Numbers
This part isn’t too complicated. To find possible phone numbers on a given page, I use a simple regex. (I also tried the excellent phonenumbers Python package, which is far more robust but also much slower, it wasn’t worth it.) It can be expanded to work on international phone numbers, but for now we’re only looking at US-based businesses.
Running the Job (On the Cheap!)
The WET files for the December 2014 Common Crawl are about 4TB compressed. That’s a fair bit of data, but we can process it pretty quickly with a few high-powered machines. Given that AWS charges you by the instance-hour, it’s most cost effective to just use as many instances required to process your job in a little less than 60 minutes. I found that I could process this job in about an hour with 20 c3.8xlarge instances.
The normal rate for a c3.8xlarge is currently $1.68/hour. Plus $.270/hr for EMR. Thus under standard pricing, our job would cost ($1.68 + $0.27) * 20 = $39. But with spot pricing, we can do much better!
Spot pricing lets you get EC2 instances at much lower rates when there is unused capacity. The current spot price for a c3.8xlarge in us-east-1 is around $0.26. We still have to pay the additional EMR charge, but this gets us to a much more reasonable ($0.26 + $0.27) * 20 = $10.60.
Results
The mrjob found approximately 748 million US phone numbers in the Common Crawl December 2014 dataset. Of the ones we were able to match against businesses in the Yelp database, 48%, already had URLs associated with them. If we assume the Yelp businesses that have URLs are correct URLs, we can get a rough estimate of accuracy by comparing the URLs in the Yelp database against the URLs that our MRJob identified.
So of the businesses that matched and already had URLs, 48% of them were the same URLs that we already had. 61% had matching domains. If we wanted to use this for real, we’d probably want to combine this with other signals to get higher accuracy. But this isn’t a bad first step.
Conclusion
The Common Crawl is a great public resource. You can scan over huge portions of the web with some simple tools and a price of a sandwich. MRJob makes this super easy with Python. Give it a try!