Mycroft - Load Data into Redshift Automatically

-
John R., Software Engineer
- Apr 30, 2015
Yelp generates terabytes of logs every day. Starting in 2010 with the release of mrjob, Yelp has relied heavily on Amazon Elastic MapReduce (EMR) and MapReduce jobs to analyze this data. While MapReduce works well to repeatedly answer the same question, it’s not a great tool to answer questions that are not well defined or that need to be answered only once. Consequently, we started using Redshift, Amazon’s Postgres-compatible column-oriented data warehouse, to explore our data.
Yelp’s log data already lands on S3 every day making it a convenient location to stage data for loading into Redshift. Unfortunately, most of our logs aren’t in a format that can be directly loaded but instead need to be lightly transformed, then converted into JSON or CSV for loading. mrjob is the perfect tool to perform these light transformations - so much so that we started building infrastructure to make this extremely common pattern as easy as possible.
Mycroft is an orchestrator that coordinates mrjob, S3, and Redshift to automatically perform light transformations on daily log data. Just specify a cluster, schema version, S3 path, and start date, and Mycroft will watch S3 for new data, transforming and loading data without user action. Mycroft’s web interface can be used to monitor the progress of in-flight data loading jobs, and can pause, resume, cancel or delete existing jobs. Mycroft will notify users via email when new data is successfully loaded or if any issues arise. It also provides tools to automatically generate schemas from log data, and even manages the expiration of old data as well as vacuuming and analyzing data.
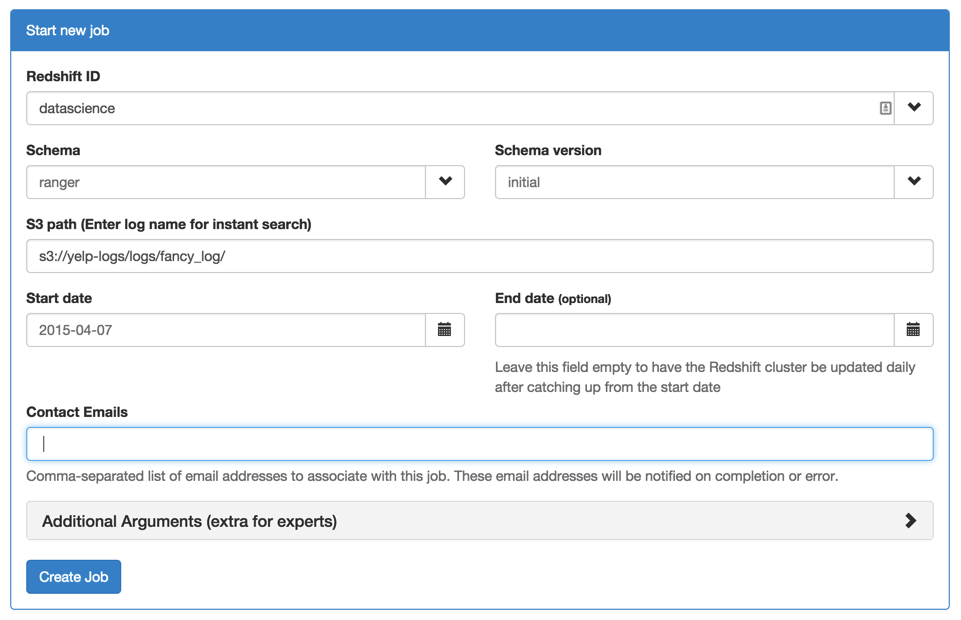
Mycroft provides a web interface that makes it easy to create new data loading jobs.
Mycroft ships as a set of Docker containers which use several AWS services, so we’ve provided a small configuration script to ease the initial customization. Once configured, the service itself can be started using docker-compose, making getting it up and running relatively painless.
A comprehensive Quickstart is available for getting Mycroft up and running. The guide steps through getting a copy of Mycroft, configuring Mycroft and launching the required AWS services, and culminates in generating a schema for some example data and loading that data into Redshift.
Mycroft is available on GitHub. Please let us know if you encounter any issues with Mycroft, and don’t hesitate to submit pull requests with any great features you decide to develop.
Acknowledgements
Thanks to the team and everyone that helped build Mycroft: John Roy, Boris Senderzon, Anusha Rajan, and Justin Cunningham.