How We Made Yelp Search Filters Data Driven

-
Ray M. G., Software Engineer Data Mining
- Dec 2, 2015
Yelp has an incredible amount of information about businesses to power local search experiences. Many of our users use our advanced search filters to explore and find exactly the place they are looking for.
While most people don’t have any trouble filtering their searches using filters such as price, distance, and rating, it was harder for users to employ our more specialized filters such as “Outdoor Seating” or “Live Music”. We set off on a mission to make our advanced filters more approachable for casual users without hindering the experience for our advanced users.
Before designing the new filters, we wanted to better understand how our users engaged with them, so we began digging into the data. People typically choose no more than a few filters at a time. The filter(s) they chose largely depended on the search query they used. We started by doing a lengthy data exploration. We came up with a set of exploratory data questions that would guide our design, such as:
- What are the most popular filters?
- When and how often do people use filters?
- Which filters have the highest impact for search?
- Which filters do we over-show and are under-used and vise versa?
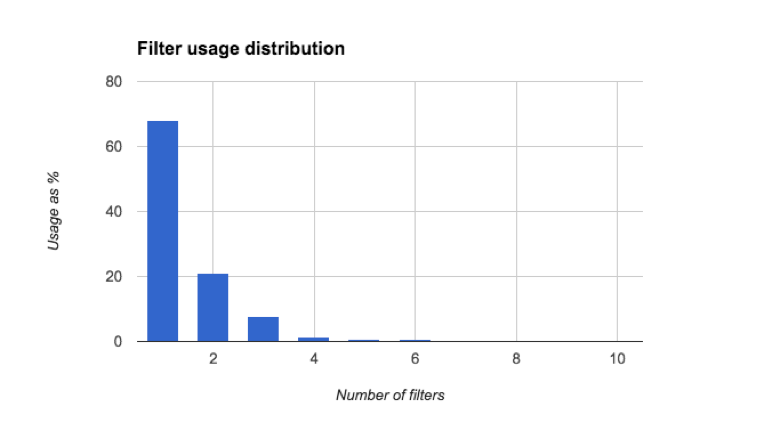
For example, the plot below shows that of all the searches that use filters, most of them only use a single filter. This tells us that we want a simple design to highlight only a few filters relevant to the search.
Based on the exploration, we came up with a new design shown below. Not only does the new design take significantly less space, reducing the time it takes to get to the search results, but hides less relevant filters for the users that want to use them. By revealing the most relevant filters based on a search, we are able to cater to almost all users. If we are unable to accurately make a prediction, all of Yelp’s powerful filters are still available a click away.
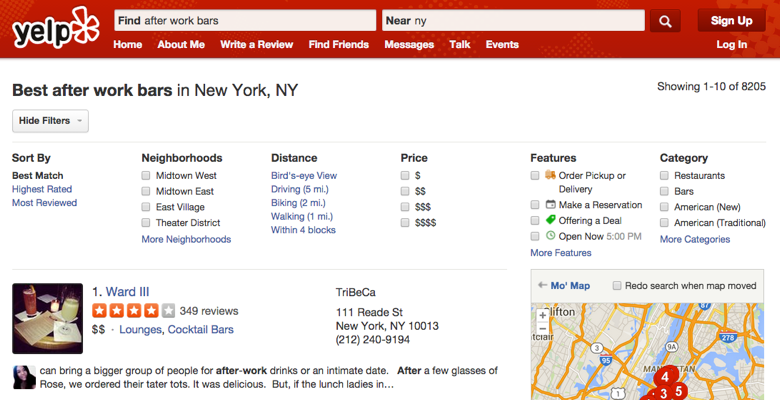 Old Search Filters
Old Search Filters
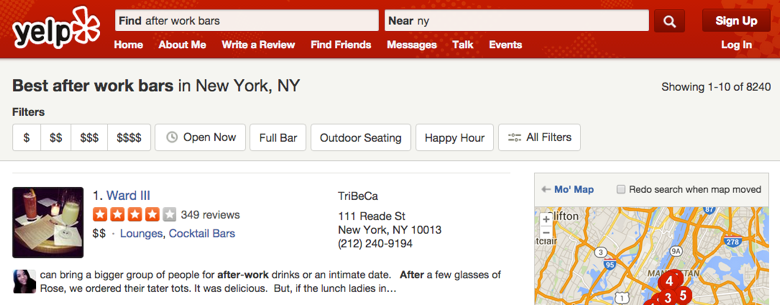 New Search Filters
New Search Filters
Building a model to recommend filters
We wanted to build a model that can take a set of informative features such as the query, date & time, location, personal preferences and a variety of other feature to suggest a set of most relevant filters to show to our users.
One of the most important features here is the query string: what the user is searching for will have a huge impact on the filters they plan to use. We can see this easily from our data. For example, searching for “birthday dinners” or “romantic dinners” often leads to the make a reservation filter. When people search for “coffee shops”, they often want to look for free-wifi or outdoor-seating.
Unfortunately, the query text is a super-sparse, long-tailed, feature with high cardinality (we receive tens of millions of distinct queries in a year in over 30 different countries), making it difficult to engineer and feed into a model. We wanted to build a function that maps the query text into a single number that tells us how relevant is this query to a particular filter. Ideally this function should be continuous and smooth; “Birthday dinner” and “Best birthday dinners” should produce very similar scores. The simplest approach here is look at our click data and see which filters people use for which queries and generate a signal based on that. However, this is not a very flexible approach as click data and can be very sparse and drops off quickly after the top queries. In addition, approximately 10 - 15% of queries are ones that we have never seen before. This is where language models become useful.

A language model can be thought of as a function that takes as an input a sequence of words and returns a probability (likelihood) estimate of that sequence. If we can build a language model for every search filter, we can use it to calculate the posterior probability of all filters being used given the query and thus help decide which filters are most relevant to our query. To calculate the posterior probability of P(filter | query), we use a simple application of Bayes rule (see diagram above). Intuitively, we want to ask how probable a query is to be generated by some particular filter language model versus how common the query is overall in the language of Yelp queries.
In the diagram above searching for “after work bars”, HappyHour and OutdoorSeating are given a positive score in our model and deemed relevant whereas GoodForBrunch and GoodForKids are deemed as not relevant.
Data Analysis
We launched the new filter redesign as an experiment and waited for results to roll in. The data analysis here is rather tricky; we completely rebuilt the filter panel and needed to carefully define what metrics we want to measure.
- Filter Engagement: Increase user engagement with Yelp search filters because they help our users discover relevant content faster.
- Search Quality: Improve the search experience by providing more relevant content through recommending better filters.
Filter Engagement
The first metric appears simple: loosely speaking we want to increase total number of filter clicks normalized by the total number of searches in each cohort. But as with all data analysis, there are many caveats to consider. For example:
- We are reducing the number of filters we show and the total real-estate of the filter panel. The more rigorous metric here would be click density, or clicks per pixel.
- Since this an optimization problem over a large parameter space (of filters), we are inevitably going to increase usage for some filters but decrease for others. Which ones do we care about more?
- In the new filter panel, users can actually access all the old filters by clicking on the all-filters button. We need to keep track of the source of the clicks to make sure the users are actually interacting with the new panel.
- Being such a prominent feature, we need to account for the novelty effect and run our experiment for a sufficient amount of time.
However for simplicity, the filter usage in the experimental cohort was about 20% more than that in the status quo. Certain filters such as Open Now and Happy Hour received huge gains in usage while others saw slight decreases. This is important feedback that tells us which filters we over-weighted and which ones are under-weighted.
Search Quality
Increasing filter engagement is good but ultimately our goal is to improve the search experience for our users. But how do we measure “search experience”? The most frequently used success metrics are clicked based. (ie: Click Through Rate (CTR), MAP (Mean Average Precision), or RR (Reciprocal Rank)). The graph below shows that over 10 days, we saw a consistent, statistically significant (p-value « 0.05), increase in search session CTR in the experimental cohort.
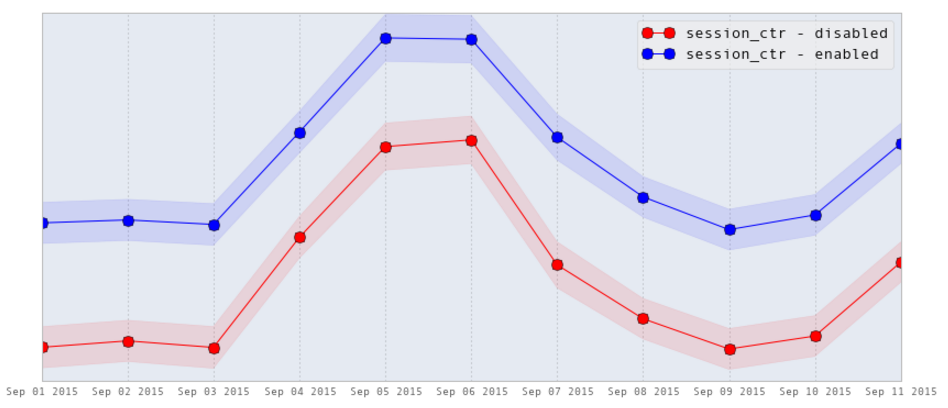
While clicks are easy to measure, they can often be the most deceptive metrics. Just because a user clicks on a result, doesn’t make it relevant. Instead, we use a number of other metrics that more closely couples to user interactions with the site to define success. For example, this includes user engagement metrics on the business page following a search and time it takes for a user to find relevant results.
Future
In this blog, we mostly discussed the usage of filter language models to build an engine to power our new search filters UI. These new filters were very well received and beat our expectations on almost every metric. However, as mentioned earlier, the filter language model is one of many powerful features that can be combined to make an even better prediction. Stay tuned to hear about follow up work on building a machine learning model to combine these features.
Acknowledgements: Special thanks to the whole filter redesign team. Back-end by Ray M. G.; Front-end by Peter R; Design by Taron G.; Product Management by Natarajan S.
Become a Part of the Data Revolution at Yelp
Interested in using natural language processing and machine learning to build amazing features like this for Yelp and our users? Apply to become a Data-Mining Engineer.
View Job