Yelp Restaurant Photo Classification, Winner's Interview: 1st Place, Dmitrii Tsybulevskii

-
Fang-Chieh C., Data Mining Engineer
- Apr 28, 2016
A few months ago, Yelp partnered with Kaggle to run an image classification competition, which ran from December 2015 to April 2016. 355 Kagglers accepted Yelp’s challenge to predict restaurant attributes using nothing but user-submitted photos. We’d like to thank all the participants who made this an exciting competition!
Dmitrii Tsybulevskii took the cake by finishing in 1st place with his winning solution. In this blog post, Dmitrii dishes on the details of his approach including how he tackled the multi-label and multi-instance aspects of this problem which made this problem a unique challenge.
This interview blog post is also published on Kaggle’s blog.
The Basics
What was your background prior to entering this challenge?
I hold a degree in Applied Mathematics, and I’m currently working as a software engineer on computer vision, information retrieval and machine learning projects.

Dmitrii on Kaggle
Do you have any prior experience or domain knowledge that helped you succeed in this competition?
Yes, since I work as a computer vision engineer, I have image classification experience, deep learning knowledge, and so on.
How did you get started competing on Kaggle?
At first I came to Kaggle through the MNIST competition, because I’ve had interest in image classification and then I was attracted to other kinds of ML problems and data science just blew up my mind.
What made you decide to enter this competition?
There are several reasons behind it:
- I like competitions with raw data, without any anonymized features, and where you can apply a lot of feature engineering.
- Quite large dataset with a rare type of problem (multi-label, multi-instance). It was a good reason to get new knowledge.
Let’s get technical:
What preprocessing and supervised learning methods did you use?
Outline of my approach depicted below:

Photo-level feature extraction
One of the most important things you need for training deep neural networks is a clean dataset. So, after viewing the data, I decided not to train a neural network from scratch and not to do fine-tuning. I’ve tried several state-of-the-art neural networks and several layers from which features were obtained. Best performing (in decreasing order) nets were:
The best features were obtained from the antepenultimate layer, because the last layer of pretrained nets are too “overfitted” to the ImageNet classes, and more low-level features can give you a better result. But in this case, dimensions of the features are much higher (50176 for the antepenultimate layer of “Full ImageNet trained Inception-BN”), so I used PCA compression with ARPACK solver, in order to find only few principal components. In most cases feature normalization was used.
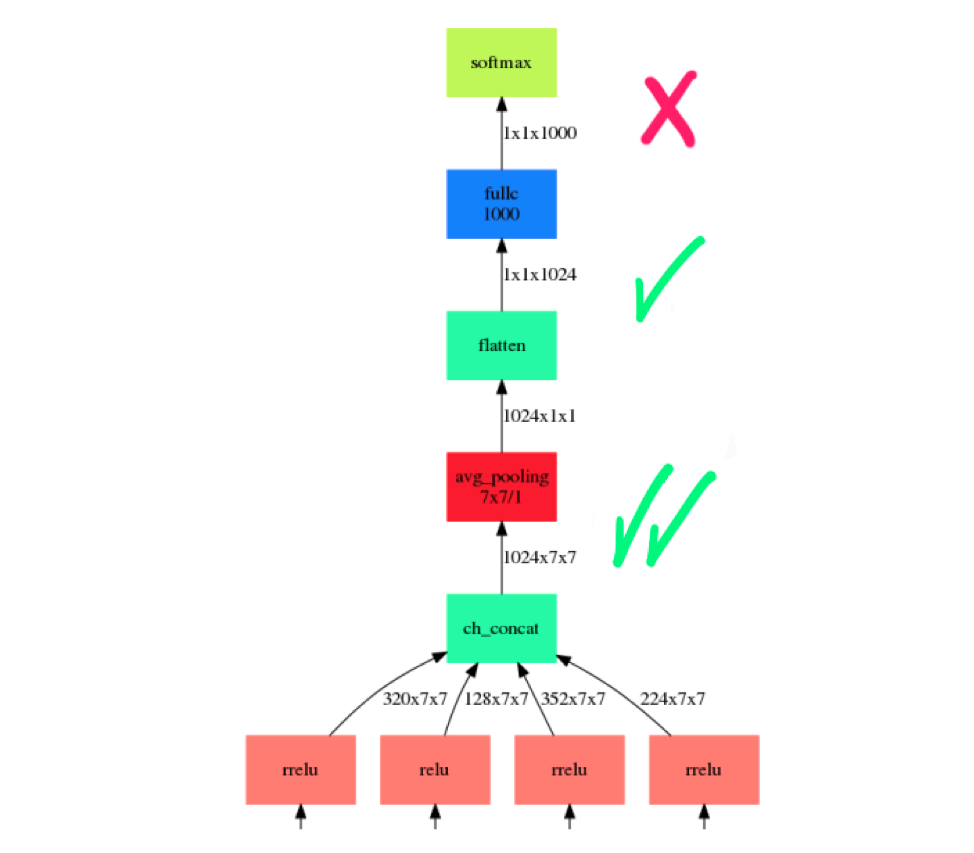
How did you deal with the multi-instance aspect of this problem?
In this problem we only needed in the bag-level predictions, which makes it much simpler compared to the instance-level multi-instance learning. I used a paradigm which is called “Embedded Space”, according to the paper: Multiple Instance Classification: review, taxonomy and comparative study. In the Embedded Space paradigm, each bag X is mapped to a single feature vector which summarizes the relevant information about the whole bag X. After this transform you can use ordinary supervised classification methods.
For the business-level (bag-level) feature extraction I used:
- Averaging of photo-level features
- Simple, but very efficient in the case of outputs of neural networks.
- Fisher Vectors
- Fisher Vector was the best performing image classification method before “Advent” of deep learning in 2012. Usually FV was used as a global image descriptor obtained from a set of local image features (e.g. SIFT), but in this competition I used them as an aggregation of the set of photo-level features into the business-level feature. With Fisher Vectors you can take into account multi-instance nature of the problem.
- Very similar to Fisher Vectors.
After some experimentation, I ended up with a set of the following business-level features:
- Averaging of L2 normalized features obtained from the penultimate layer of [Full ImageNet Inception-BN]
- Averaging of L2 normalized features obtained from the penultimate layer of [Inception-V3]
- Averaging of PCA projected features (from 50716 to 2048) obtained from the antepenultimate layer of [Full ImageNet Inception-BN]
- L2 normalized concatenation of 2., 3.
- PCA projected 4. to 128 components.
- Fisher Vectors over PCA projected 3. to 64 components.
- VLAD over PCA projected 3. to 64 components.
How did you deal with the multi-label aspect of this problem?
I used Binary Relevance (BR) and Ensemble of Classifier Chains (ECC) with binary classification methods in order to handle the multi-label aspect of the problem. But my best performing single model was the multi-output neural network with the following simple structure:

This network shares weights for the different label learning tasks, and performs better than several BR or ECC neural networks with binary outputs, because it takes into account the multi-label aspect of the problem.
Classification

Neural network has much higher weight(6) compared to the LR(1) and XGB(1) at the weighing stage. After all, 0, 1 labels were obtained with a simple thresholding, and for all labels a threshold value was the same.
What didn’t work for you?
- Label powerset for multi-label classification
- RAkEL for multi-label classification
- Variants of ML-KNN for multi-label classification
- Removing duplicate photos
- XGBoost. I added some XGBoost models to the ensemble just out of respect to this great tool, although local CV score was lower.
- MISVM for multi-instance classification
- More image crops in the feature extractor
- Stacking. It’s pretty easy to overfit with a such small dataset, which has only 2000 samples.
Were you surprised by any of your findings?
- Features extracted from the Inception-V3 had a better performance compared to the ResNet features. Not always better error rates on ImageNet led to the better performance in other tasks.
- Simple Logistic Regression outperforms almost all of the widely used models such as Random Forest, GBDT, SVM.
- Binary Relevance is a very good baseline for the multi-label classification.
Which tools did you use?
MXNet, scikit-learn, Torch, VLFeat, OpenCV, XGBoost, Caffe
How did you spend your time on this competition?
50% feature engineering, 50% machine learning
What was the run time for both training and prediction of your winning solution?
Feature extraction: 10 hours
Model training: 2-3 hours
Words of wisdom:
What have you taken away from this competition?
A “Prize Winner” badge and a lot of Kaggle points.
Do you have any advice for those just getting started in data science?
Kaggle is a great platform for getting new knowledge.
Just for fun:
If you could run a Kaggle competition, what problem would you want to pose to other Kagglers?
I’d like to see reinforcement learning or some kind of unsupervised learning problems on Kaggle.
Bio
Dmitrii Tsybulevskii is a Software Engineer at a photo stock agency. He holds a degree in Applied Mathematics, and mainly focuses on machine learning, information retrieval and computer vision.
Become a Part of the Data Revolution at Yelp
Interested in using machine learning to unlock information contained in Yelp's data through problems like this? Apply to become a Data-Mining Engineer.
View Job