Autoscaling PaaSTA Services

-
Matt S., Software Engineer
- May 25, 2016
If you haven’t heard about PaaSTA before, feel free to check out the blog post introducing it.
One step in creating a service is to decide how many compute resources it needs. From the inception of PaaSTA, changing a service’s resource allocation has required manually editing and pushing new configs, and service authors had to pore over graphs and alerts to determine the proper resource allocation for a service whenever load requirements changed. This changed earlier this month when autoscaling was introduced into PaaSTA.
Why did we do this?
Autoscaling was introduced into PaaSTA to make sure services are allocated an appropriate amount of resources as their load changes. Many services at Yelp have large differences in how many resources they need throughout the day. Previously we’ve dealt with this by overprovisioning – giving services the resources they need to operate at peak load, even if they’re only using a fraction of that most of the time. Autoscaling allows PaaSTA to free up resources from services that aren’t using them and either give those resources to services that need them or scale down our clusters and cut our infrastructure bill. Alternatively, if usage increases we can prevent performance degradation by automatically allocating more resources to a service.
How did we do this?
One of our goals when developing autoscaling was to make it as easy as possible for service authors to migrate to autoscaling. When a service author enables autoscaling, they only need to specify the minimum and maximum number of instances for their service.
Here’s an example of a PaaSTA service’s config file with autoscaling enabled:
---
main:
cpus: 1
mem: 1024
# All that's required to enable autoscaling
min_instances: 3
max_instances: 12
That’s it!
PaaSTA then chooses sane defaults for the other autoscaling parameters: the
metrics_provider and the decision_policy. The metrics_provider tells the
autoscaler how much a service is under load. The decision_policy code takes
load information from a metrics_provider and determines how many instances a
service should be running. If a service author wants more control, they can
override PaaSTA’s defaults by specifying a metrics_provider and
decision_policy in their service configs. They can also inject additional
autoscaling
parameters
by adding them to their service configs.
Here’s an example of a customized service config:
---
main:
cpus: 1
mem: 1024
min_instances: 3
max_instances: 12
# Advanced configuration
autoscaling:
metrics_provider: http
endpoint: metrics.json
decision_policy: threshold
setpoint: 0.5
If the autoscaler decides to scale a service, the new instance count is written to Zookeeper and an event is logged describing why the service was scaled. The next time PaaSTA updates Marathon, it reads the updated instance count and scales the corresponding Marathon app. As the app scales, Smartstack handles service discovery by registering or de-registering instances. Our Sensu replication alerts and other tools are also automatically updated to use the new instance counts specified in Zookeeper.
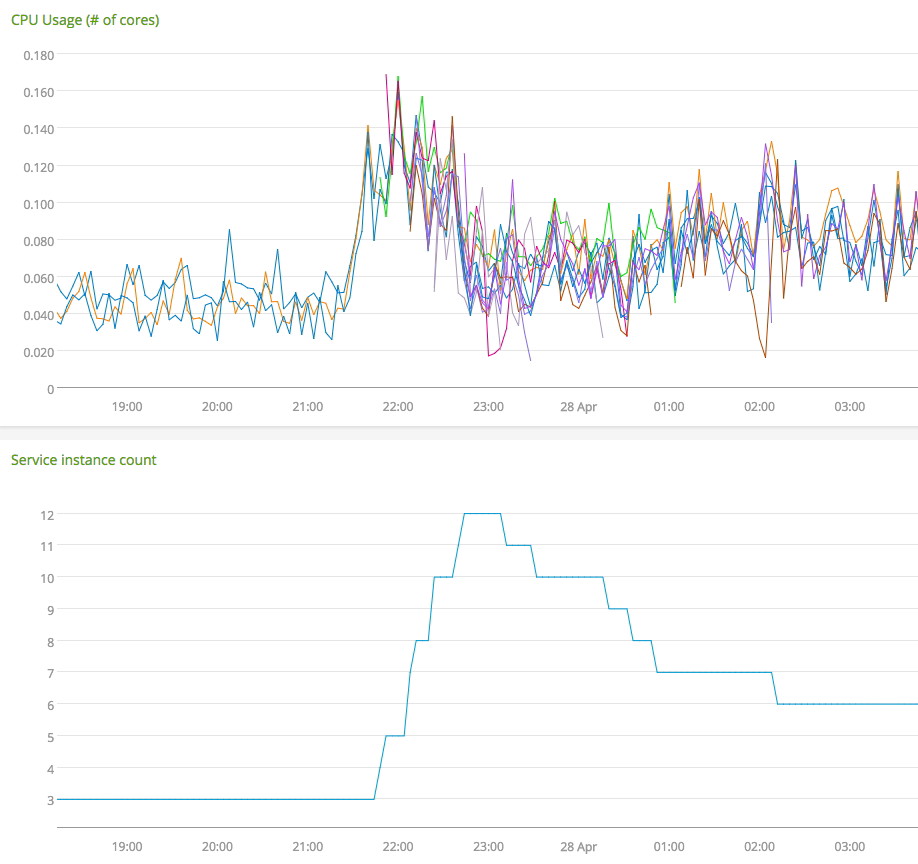
Above is an example of PaaSTA dealing with a spike in CPU usage for a service.
This service uses a
metrics_provider
that emits the average cpu utilization for a service and a
decision_policy
that uses a PID controller to control the instance count.
Bespoke autoscaling methods
But what happens if a service’s utilization isn’t accurately represented by any
metrics_provider? For example: a queue worker might want to scale based on
the change in its queue length over time. Since the instance count for a
service is just a number written in Zookeeper, PaaSTA can get autoscaling
signals from custom external sources. Service authors can specify that they
want to use the 'bespoke' decision_policy and PaaSTA will skip its
internal autoscaling code and instead respond to external autoscaling signals
in Zookeeper.
Why can’t you just use AWS autoscaling (or something similar)?
Let’s compare PaaSTA autoscaling to Amazon’s ECS autoscaling. Both of these technologies can scale Docker containers, and AWS has CloudWatch as a very powerful monitoring and metrics solution. Why didn’t we just use ECS? The biggest difference between the two is that PaaSTA autoscaling is infrastructure-agnostic (just like PaaSTA itself) while ECS autoscaling operates only on Amazon ASGs. ECS autoscaling also creates and destroys EC2 servers, while PaaSTA autoscaling only changes the number of services that are running on existing servers.
Finally, ECS autoscaling uses fairly simple logic for determining to scale up
or down, checking to see if a metric passes above or below a static threshold
for a certain amount of time. PaaSTA autoscaling has multiple decision_policy
that provide different methods of control: some can do simple threshold-based
logic, while other decision_policy use more complicated control systems such
as PID controllers to achieve
better control at the cost of increased complexity and reduced transparency.
Conclusion
PaaSTA autoscaling allows us to ensure services stay performant and cost-efficient even as new code is shipped or their utilization changes. It’s flexible enough to support many of the hundreds of services we have at Yelp; widespread adoption across our services will greatly increase the elasticity of our infrastructure. If you want to learn more about PaaSTA, or see the source for autoscaling, check out our Github. Stay tuned for a future blog post where we use the same concepts to autoscale clusters of virtual machines.
Want to help cook PaaSTA?
Like building this sort of thing? At Yelp we love building systems we can be proud of, and we are proud of PaaSTA. Check out the Site Reliability Engineer positions on our careers page if you like building systems you can be proud of too!
View Job