Yelp Restaurant Photo Classification, Winner's Interview: 2nd Place, Thuyen Ngo

-
Fang-Chieh C., Data Mining Engineer
- May 4, 2016
The Yelp Restaurant Photo Classification competition challenged Kagglers to assign attribute labels to restaurants based on a collection of user-submitted photos. At the final tally, 355 players tackled this unique machine learning problem. Last week, we published Dmitrii Tsybulevskii’s 1st place solution here; Thuyen Ngo finished in 2nd place, with an F1 score of 0.83168, and describes his strategy in this week’s interview.

The Basics
What was your background prior to entering this challenge?
I am a PhD student in Electrical and Computer Engineering at UC Santa Barbara. I am doing research in human vision and computer vision. In a nutshell I try to understand how humans explore the scene and apply that knowledge to computer vision systems.

Thuyen (AKA Plankton) on Kaggle
How did you get started competing on Kaggle?
My labmate introduced Kaggle to me about a year ago and I participated in several competitions since then.
Do you have any prior experience or domain knowledge that helped you succeed in this competition?
All of my projects involved images. So It’s fair to say that I have some “domain knowledge”. However, for this competition I think knowledge from image processing is not as important as machine learning. Since everyone uses similar image features (from pre-trained convolutional neural networks, which have been shown to contain good global descriptions of images and therefore are very suitable to our problem), the difficult part is to choose a learning framework that can combine information from different instances in an effective way.
What made you decide to enter this competition?
I am interested in image data in general (even though in the end there was not much image analysis involved). The problem is very interesting itself since there’s no black-box solution that can be applied directly.
Let’s get technical
What preprocessing and supervised learning methods did you use?
Like most participants, I used pre-trained convolutional networks to extract image features, I didn’t do any other preprocessing or network fine-tuning. I started with the inception-v3 network from google but ended up using the pre-trained resnet-152 provided by Facebook.
My approach is super simple. It’s just a neural network.
How did you deal with the multi-instance and multi-label aspect of this problem?
I used multilayer perceptron since it gave me the flexibility to handle both the multiple label and multiple instance at the same time. For multiple label, I simply used 9 sigmoid units and for multiple instance, I employed something like the attention mechanism in the neural network literature. The idea is to let the network learn by itself how to combine information from many instances (which instance to look at).
Each business is represented by a matrix of size N x 2048, where N is the number of images for that business. The network is composed of four fully connected (FC) layers. Attention model is a normal FC layer but the activation is a softmax over images, weighting the importance of each image for a particular feature. I experimented with many different architectures, in the end, the typical architecture for the final submission is as follows:
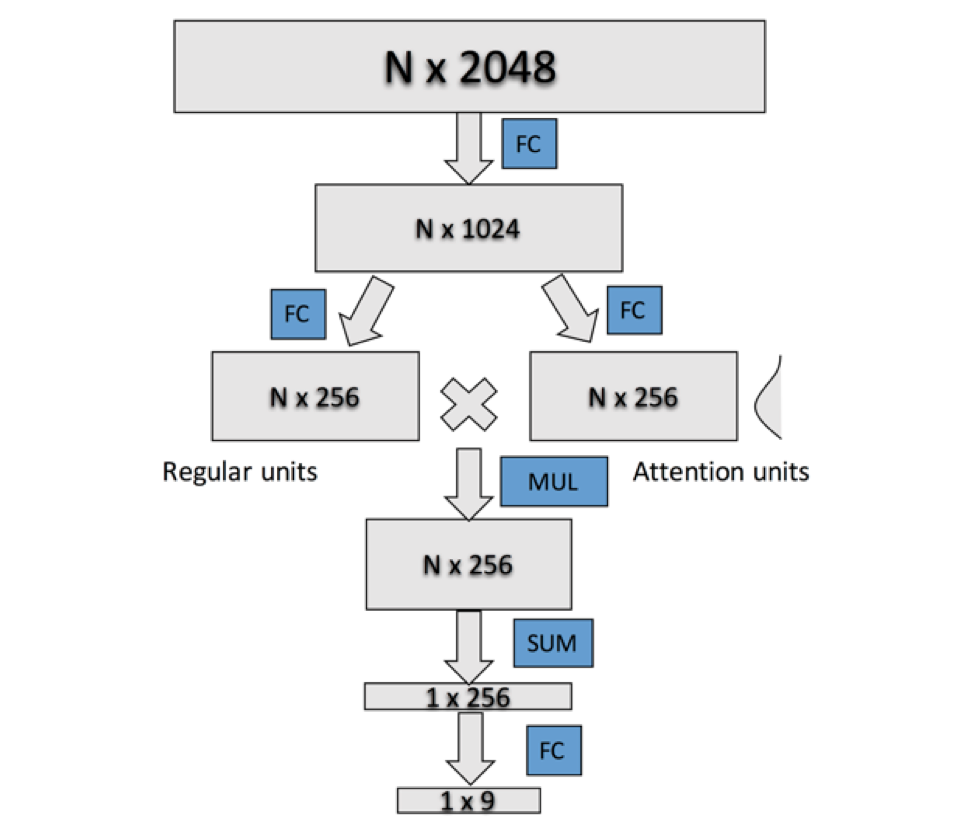
The model is trained using the business-level labels (each business is a training example) as opposed to image-level labels (like many others). I used the standard cross entropy as the loss function. The training is done with Nesterov’s accelerated SGD.
What was your most important insight into the data?
Finding the reliable local validation is quite challenging to me. It’s a multiple label problem, and thus there’s no standard stratified split. I tried some greedy methods to do stratified 5-fold split but it didn’t perform very well. At the end I resorted to a random 5-fold split. My submission is normally the average of 5 models from 5-fold validation.
Another problem is that we only have 2000 businesses for training and another 2000 test cases. Even though it sounds a lot of data, training signals (the labels) are not that many. In combination with the instability of F measure, it makes the validation even more difficult.
Since the evaluation metric is F1 score, it is reasonable to use F-measure as the loss function, but somehow I couldn’t make it work as well as the cross entropy loss.
With limited labeled data, my approach would have badly overfitted the data (it has more than 2M parameters). I used dropout for almost all layers, applied L2 regularization and early stopping to mitigate overfitting.
How did you spend your time on this competition?
Most of the time for machine learning (training), 1% for preprocessing I guess.
Which tools did you use?
I used Tensorflow/torch for feature extraction (with the provided code from Google/Facebook) and Lasagne (Theano) for my training.
What was the run time for both training and prediction of your winning solution?
It takes about two and a half hours to train one model and about a minute to make the predictions for all test images.
Words of wisdom
What have you taken away from this competition?
Neural networks can do any (weird) thing :)
Do you have any advice for those just getting started in data science?
Just do it, join Kaggle, participate and you will improve.
Bio
Thuyen Ngo is a PhD student in Electrical and Computer Engineering at the University of California, Santa Barbara.
Become a Part of the Data Revolution at Yelp
Interested in using machine learning to unlock information contained in Yelp's data through problems like this? Apply to become a Data-Mining Engineer.
View Job