Monitoring Cassandra at Scale

-
Joseph Lynch, Software Engineer
- Jun 1, 2016
At Yelp we leverage Cassandra to fulfill a diverse workload that seems to combine every consistency and availability tradeoff imaginable. It is a fantastically versatile datastore, and a great complement for our developers to our MySQL and Elasticsearch offerings. However, our infrastructure is not done until it ships and is monitored. When we started deploying Cassandra we immediately started looking for ways to properly monitor the datastore so that we could alert developers and operators of issues with their clusters before cluster issues became site issues. Distributed datastores like Cassandra are built to deal with failure, but our monitoring solution had to be robust enough to differentiate between routine failure and potentially catastrophic failure.
Monitoring Challenges
We access Cassandra through our standard NoSQL proxy layer Apollo, which gives us great application level performance and availability metrics for free via our uwsgi metrics framework. This immediately gives us the capability to alert developers when their Cassandra based application is slow or unavailable. Couple these pageable events with reporting the out of the box JMX metrics on query timing to customers and the monitoring story is starting to look pretty good for consumers of Cassandra.
The main difficulty we faced was monitoring the state of the entire database
for operators of Cassandra. Some of the
metrics exposed
over JMX are useful to operators. There are a lot of
good
resources
online to learn which JMX metrics are most relevant to operators, so I won’t
cover them here. Unfortunately, most of the advanced cluster state monitoring
is built into
nodetool
which is useful for an operator tending to a specific cluster but does not
scale well to multiple clusters with a distributed DevOps ownership model where
teams are responsible for their own clusters. For example, how would one
robustly integrate the output of nodetool with
Nagios or Sensu?
OpsCenter is
closer to what we need, especially if you pay for the enterprise edition, but
the reality is that this option is expensive, does not monitor ring health in
the way we want and does not (yet) support 2.2 clusters.
We need to be able to determine a datastore is going to fail before it fails. Good datastores have warning signs, but it’s a matter of identifying them. In our experience, the JMX metrics monitoring technique works well when you’re having a performance or availability problem isolated to one or two nodes. The technique falls flat, however, when trying to differentiate between an innocuous single node failure impacting a keyspace with a replication factor of five and a potentially critical single node failure impacting a keyspace with a replication factor of two.
Finding Cassandra’s Warning Signs
Cassandra uses a ring topology to store data. This topology divides the
database into contiguous ranges and assigns each of the ranges to a set of
nodes, called replicas. Consumers query the datastore with an associated
consistency
level
which indicates to Cassandra how many of these replicas must participate when
answering a query. For example, a keyspace might have a replication factor of
3, which means that every piece of data is replicated to three nodes. When a
query is issued at LOCAL_QUORUM, we need to contact at least ⅔ of the
replicas. If a single host in the cluster is down, the cluster can still
satisfy operations, but if two nodes fail some ranges of the ring will become
unavailable.
Figure 1 is a basic visualization of how data is mapped onto a single Cassandra ring with virtual nodes. The figure elides details of datacenter and rack awareness, and does not illustrate the typically much higher number of tokens than nodes. However, it is sufficient to explain our monitoring approach.
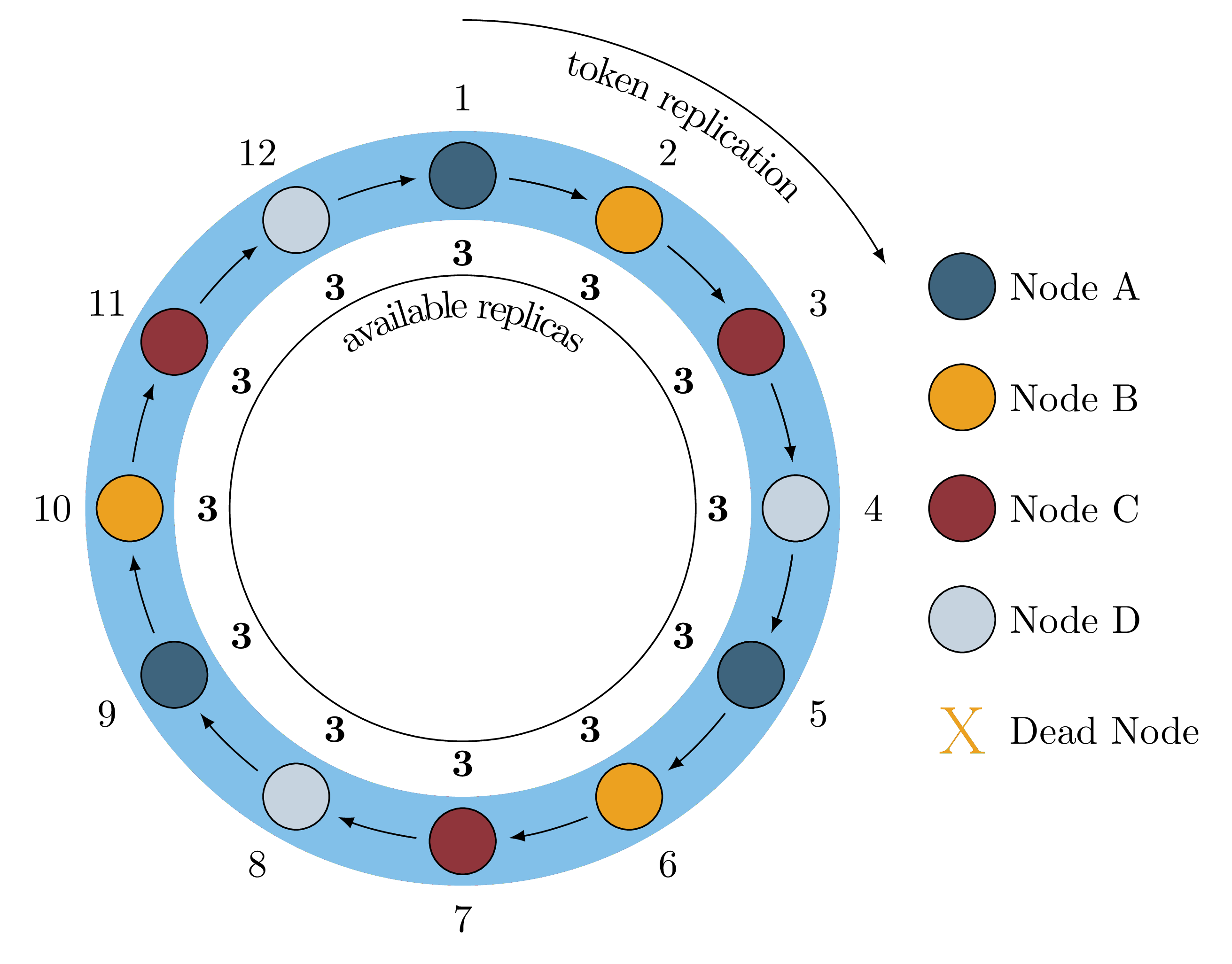
Figure 1: A Healthy Ring
In this case we have four nodes, each with three “virtual” nodes (a.k.a.
vnodes
) and the keyspace has a replication factor of three. For the sake of
explanation, we assume that we only have twelve ranges of data and data
replicates to the three closest virtual nodes in a clockwise fashion. For
example, if a key falls in token range 9, it is stored on Node A, Node B
and Node C. When all physical hosts are healthy, all token ranges have all
three replicas available, indicated by the threes on the inside of the ring.
When a single node fails, say Node A, we lose a replica of nine
token ranges because any token range that would replicate to Node A is
impacted. For example, a key that would map to token range 8 would typically
replicate to Node D, Node A and Node B but it cannot replicate to to
Node A because Node A is down. This is illustrated in Figure 2.
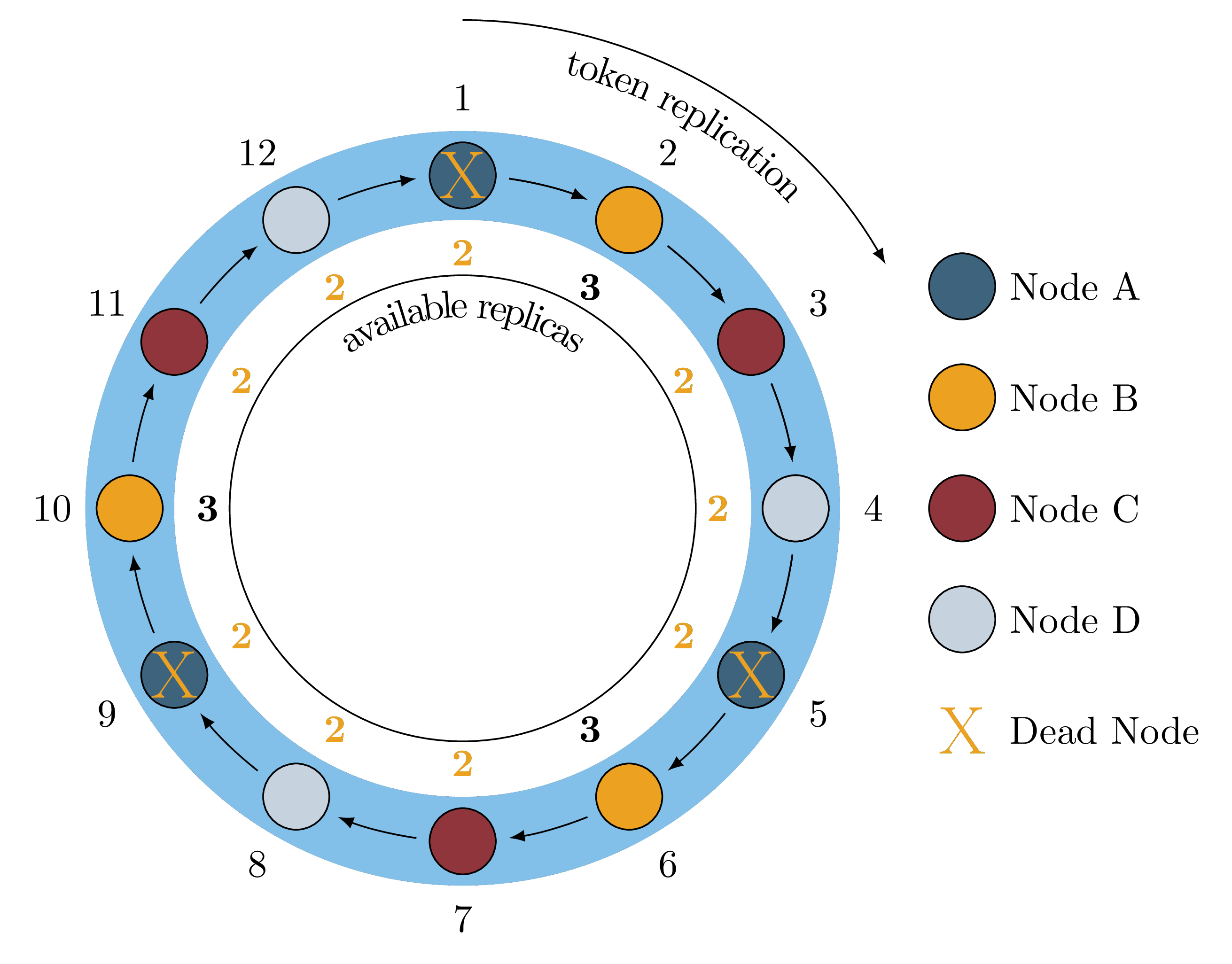
Figure 2: Single Node Failure
At this point we can still execute operations at LOCAL_QUORUM because ⅔ of
replicas are still available for all token ranges, but if we were to lose
another node, say Node C, we would lose a second replica of six token ranges
as shown in Figure 3.
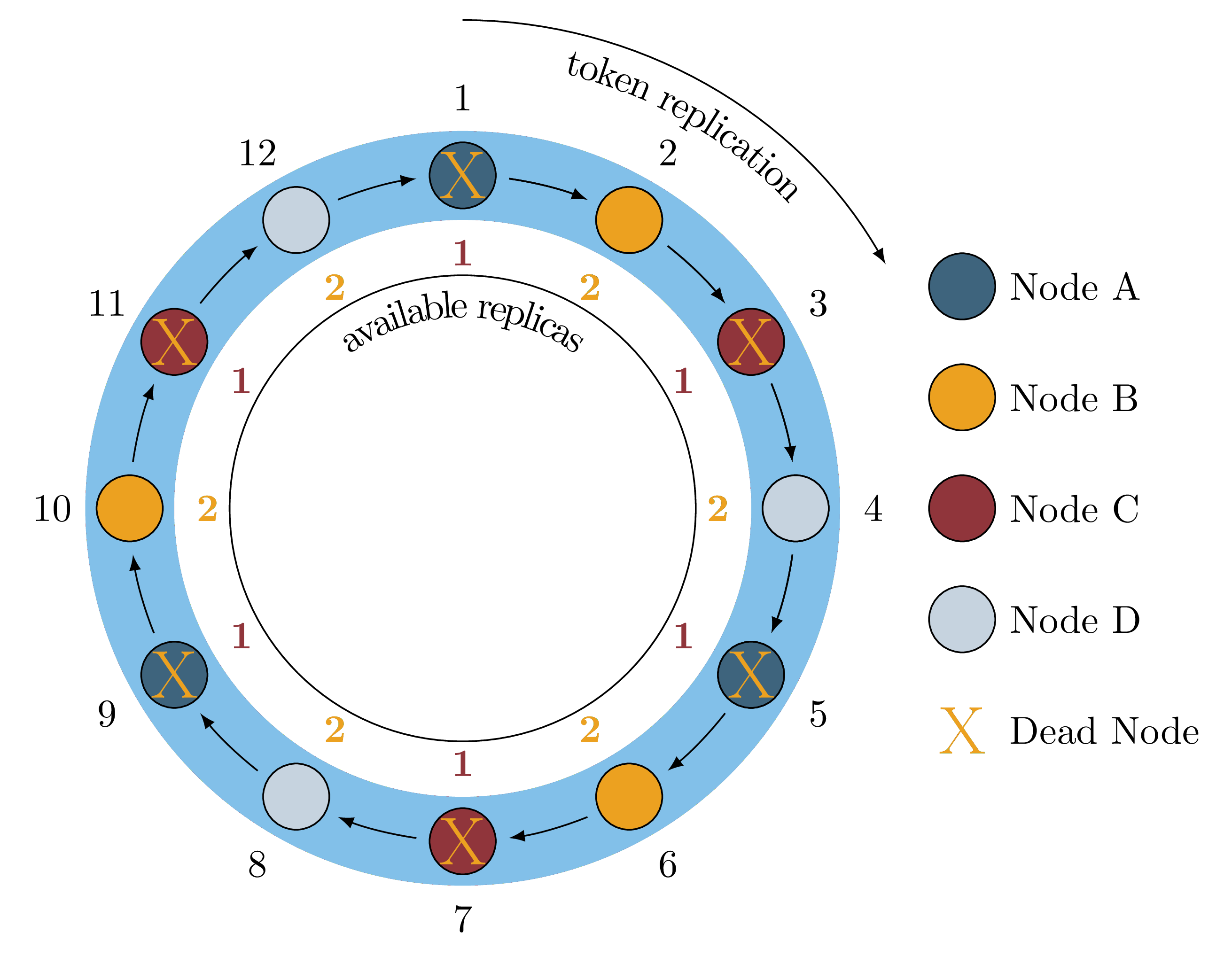
Figure 3: Two Node Failures
This means that any key which exists on those six token ranges is unavailable
at LOCAL_QUORUM, while any keys not in those ranges are still available.
This understanding allows us to check if a cluster is unavailable for a particular consistency level of operations by inspecting the ring and verifying that all ranges have enough nodes in the “UP” state. It is important to note that client side metrics are not sufficient to tell if a single additional node failure will prevent queries from completing, because the client operations are binary: they either succeed or not. We can tell they are failing, but can’t see the warning signs before failure.
Monitoring Cassandra’s Warning Signs
Under the hood, nodetool uses a JMX interface to retrieve information like
ring topology, so with some sleuthing in the nodetool and Cassandra source
code we can find the following useful
mbeans:
- type=StorageService/getRangeToEndpointMap/{keyspace}
- type=EndpointSnitchInfo/getDatacenter/{node}
- type=StorageService/Keyspaces
- type=StorageService/LiveNodes
In order to programmatically access these mbeans we install jolokia on all of our Cassandra clusters. An HTTP interface to Cassandra’s mbeans is extremely powerful for allowing quick iteration on automation and monitoring. For instance, our monitoring script can be as simple as (pseudocode):
Often our applications using Cassandra read and write at LOCAL_ONE, which
means that we can get robust monitoring by deploying the above check twice: the
first monitoring LOCAL_ONE that pages operators, and the second monitoring
LOCAL_QUORUM that cuts a ticket on operators. When running with a replication
factor of three, this allows us to lose one node without alerting anyone,
ticket after losing two (imminently unavailable), and page upon losing all
replicas (unavailable).
This approach is very flexible because we can find the highest consistency
level of any operation against a given cluster and then tailor our monitoring
to check the cluster at the appropriate consistency level. For example, if the
application does reads and writes at quorum we would ticket after LOCAL_ALL
and page on LOCAL_QUORUM. At Yelp, any cluster owner can control these
alerting thresholds individually.
A Working Example
The real solution has to be slightly more complicated because of cross-datacenter replication and flexible consistency levels. To demo this approach really works, we can setup a three node Cassandra cluster with two keyspaces, one with a replication factor of one (blog_1) and one with a replication factor of three (blog_3). In this configuration each node has the default 256 vnodes.
We like to write our monitoring scripts in Python because we can integrate seamlessly with our pysensu-yelp library for emitting alerts to Sensu, but for this demo I’ve created a simplified monitoring script that inspects the ring and exits with a status code that conforms to the Nagios Plugin API. As we remove nodes we can use this script to see how we gradually lose the ability to operate at certain consistency levels. We can also check that the number of under-replicated ranges matches our understanding of vnodes and replication:
Now it’s just a matter of tuning the monitoring to look for one level of consistency higher than what we actually query at, and we have achieved robust monitoring!
An important thing to understand is that this script probably won’t “just work” in your infrastructure, especially if you are not using jolokia, but it may be useful as a template for writing your own robust monitoring.
Take it to 11, What’s Next?
Our SREs can sleep better at night knowing that our Cassandra clusters will give us warning before they bring down the website, but at Yelp we always ask, “what’s next?”
Once we can reliably monitor ring health, we can can use this capability to further automate our Cassandra clusters. For example, we’ve already used this monitoring strategy to enable robust rolling restarts that ensures ring health at every step of the restart. A project we’re currently working on is combining this information with autoscaling events to be able to intelligently react to hardware failure in an automated fashion. Another logical next step is to automatically deduce the consistency levels to monitor by hooking into our Apollo proxy layer and updating our monitoring from the live stream of queries against keyspaces. This way if we change the queries to a different consistency level, the monitoring follows along.
Furthermore, if this approach proves useful long term, it is fairly easy to
integrate it into nodetool directly, e.g.
nodetool health <keyspace> <consistency_level>.