How We Scaled Our Ad Analytics with Apache Cassandra

-
Qui N. and Shafi B., Software Engineers
- Aug 8, 2016
On the Ad Backend team, we recently moved our ad analytics data from MySQL to Apache Cassandra. Here’s why we thought Cassandra was a good fit for our application, and some lessons we learned that you might find useful if you’re thinking about using Cassandra!
Why Cassandra?
First, a little bit about our application. We have over 100,000 paying advertisers. Every day, we calculate the numbers of views and clicks each ad campaign received the previous day and the amount of money spent by each campaign. With these analytics, we generate bills and many different types of reports.
Back in the early days of Yelp, we chose to store this data in MySQL. As we scaled and our advertising product evolved, we realized that Cassandra was a better fit. We didn’t need the benefits of traditional relational databases because we don’t have a transactional workload or a complex data model that would require joining tables. For us, the main advantages of Cassandra were simple scaling of storage, flexible schemas, and high write performance.
Simple scaling of storage
Growing our ad business means more campaigns, which means more analytics data. Because Cassandra is designed to be distributed, it’s easy to increase storage space - all you have to do is add more nodes.
Flexible schema
Our data requirements change over time. For example, we recently decided to start breaking down analytics information by ad type like mobile search or desktop review. With Cassandra’s flexible schemas, we can easily add new columns to our data tables.
High write performance
Cassandra is well-known for its impressive write capacity. In one benchmark test, Netflix achieved over 1 million writes per second! As we increase the amount of analytics data we write each day, we need to be sure that our system can handle it quickly, especially because we need the latest data available for daily reports and billing.
Lessons learned
Here are a few of the most interesting things we learned about developing with Cassandra.
1. Rethink your queries along with your schema
Cassandra is essentially a structured key-value store and the choice of columns used for the primary key dramatically impacts the performance of queries. As a result, the cardinal rule in Cassandra data modeling is to design your schema for your queries. Something less obvious, though, is that you may also need to redesign your queries.
In Cassandra, only the columns in the primary key can be used to query data - if you select data with conditions on other columns, Cassandra will need to do a full table scan. Each column in the primary key can either be part of the partition key or a clustering column. The partition key determines the node that data is stored on. Then, within each partition with a particular set of partition key values, clustering columns determine the sort order.
We noticed that all analytics queries in our existing system looked something like this:
analytics = get_stats_for_campaign(campaign_id, time_period)
In other words, our clients were requesting analytics for a particular campaign over some time period. Given that, we chose campaign_id as our partition key and used day as a clustering column.
As expected, this schema worked well for cases where the client needed analytics for a single campaign, such as a report for one campaign over time. However, it was not the ideal schema for clients that needed analytics for all campaigns, e.g. our monthly overall reports. We found that a query for one primary key took slightly longer in Cassandra than in MySQL. This was imperceptible for one query, but in a report where thousands of queries were made, the extra time added up. With Cassandra, you want to minimize the number of partitions read.
Those reports ultimately needed data on all campaigns for the same time period, even though the code queried a single campaign at a time. In this case, it would have been more efficient to use day as the partition key and query analytics by day.
When using Cassandra, it can make sense to denormalize or duplicate your data to improve query performance because of Cassandra’s good write performance and storage scalability. If you find yourself reading many partitions to satisfy some requests, consider redesigning your queries and using another schema for those requests.
2. Definition of rows and how that affects compaction
Compaction is the process of merging updated rows in Cassandra. Cassandra provides a few different compaction strategies, and the main factor in choosing one is how and when your application updates rows. While we were making this decision, we found existing documentation on the definition of row updates unclear, so we’d like to share what we learned.
We initially thought that rows would be infrequently updated in our application, because we simply write new analytics data for the previous day every day. We don’t change data for other days except in special circumstances.
Remember, though, that we chose campaign_id as the partition key and day as a clustering column. We assumed that the primary key, including both partition and clustering columns, defined separate rows:
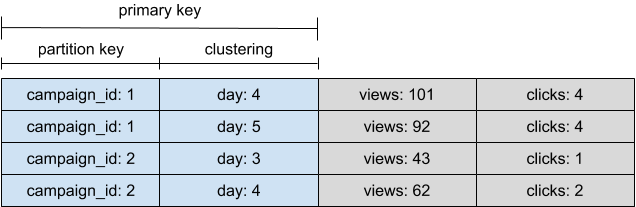
In reality, however, Cassandra stores the data for each partition key in wide rows. The clustering columns just determine the ordering of cells within that row:

As a result, each of our writes for a new day for an existing campaign actually counted as a row update that could be compacted. Once data is flushed to disk, Cassandra uses compaction to maintain clustering within partitions.
With the default compaction strategy, size-tiered compaction, the data for a single campaign ended up spread out all over disk, because the updates each day were not frequently merged. Switching to leveled compaction, which provides guarantees on the number of unmerged updates for each row, vastly improved our overall read performance. Leveled compaction does require more I/O at write time, but if you frequently update rows, it may be worth the tradeoff.
3. Migration to Cassandra will increase your write needs
Keeping data normalized is considered a best practice in MySQL. As we mentioned before, however, when using a NoSQL database like Cassandra, denormalizing data often improves query performance. One row in a normalized table could become tens of rows in many denormalized tables, meaning migrating to Cassandra can really increase your write load. Cassandra does have better write performance, but you should still keep that consideration in mind.
We didn’t fully appreciate the magnitude of this increase at the beginning, when we were deciding whether or not to use a object relational mapper (ORM). ORMs abstract out the complex underlying relational data models, making code easier to reason about. At Yelp, we already use the SQLAlchemy ORM for almost all of our MySQL operations. Given the benefits we’ve observed from SQLAlchemy, we decided to use cqlengine, the ORM packaged with the Cassandra python driver.
In our application, all writes happen in a nightly batch, which aggregates statistics for the previous day and writes them to a number of denormalized tables. During the pilot stage of the project, we were experimenting with one Cassandra table. At this stage, we were satisfied with the write performance we achieved with cqlengine. When we wrote to multiple tables, though, the nightly batch started taking too long, holding up other things in our pipeline.
Unfortunately, cqlengine does not support asynchronous writes. You can only send one write at a time, and it’s a blocking call. This really limits how quickly you can process writes. One of the reasons Cassandra can have such great write performance is that all nodes can handle writes, but you can’t take advantage of that if you’re only sending one write at a time.
As a result, if you have a large volume of data to write, cqlengine may not be the best choice. Instead, you might prefer to write asynchronously by using the execute_async operation from the Cassandra driver directly. We made this realization in a later stage of our project, so we ended up sticking with cqlengine and using some tricks to speed up writes, which we describe in the next section.
4. Cassandra batch statements can be useful
A batch operation in Cassandra combines multiple data modification operations (such as insert, update, and delete) into a single logical operation. Unlike MySQL batch operations, Cassandra batch operations are rarely used for performance optimization. Instead, batch operations are mostly used to provide atomicity, and using them to perform bulk writes is considered an anti-pattern. In our project, though, we found that using batch operations was an effective way to improve our write performance.
Our initial method of writing each row synchronously using the cqlengine save operation turned out to be really slow. For each row, we were sending a write request from our service to Cassandra and then waiting for it to complete. That is, each row written required a complete network round trip from our service to the Cassandra cluster. Furthermore, we had to wait for each round trip sequentially. This is where the batch operation came in handy. By combining writes for several rows together into a single cqlengine batch query, we were able to reduce the number of round trips needed by almost tenfold, and the Cassandra nodes could coordinate the writes in each batch in parallel. This technique cut our nightly batch run time in half.
5. TTL may not be the right choice
Cassandra supports an optional time to live (TTL) expiration period for each column of a data row. If a column has a TTL value set, it will expire automatically after that period, so you don’t have do anything extra to delete old data later.
During the initial stages of our project, the requirement was to keep analytics data in Cassandra for one year. Accordingly, in our first backfill of data from MySQL, we set the TTL on all the data to one year in the future.
Then, as the project progressed, the requirement increased to two years. Turns out, to change the TTL on data, you need to re-insert that data with the new TTL value, so we had to rerun the entire backfill again!
Whether or not TTL is the right choice depends on your application. When using Cassandra as a cache, for example, TTL can be very useful because it clears old data automatically, and it’s not necessary to update the TTL of existing data. In an analytics use case like ours, however, the data in Cassandra is very critical, and automatically expiring data can become problematic if data requirements ever change. In that case, running a periodic batch to delete old data may be a better choice.
Final thoughts
Moving our ad analytics data from MySQL to Cassandra has produced benefits across the organization. It increased the flexibility of the ad analytics system in terms of data growth and schema changes while also removing the load of one of the largest tables from our shared MySQL clusters. If you’re looking to build or migrate a system with a high volume of writes, Cassandra could be a good choice as long as you consider the lessons we learned.