Finding Beautiful Yelp Photos Using Deep Learning

-
Alex M., Software Engineer
- Nov 29, 2016
Yelp users upload around 100,000 photos a day to a collection of tens of millions, and that rate continues to grow. In fact, we’re seeing a growth rate for photos that is outpacing the rate of reviews. These photos provide a rich tapestry of information about the content and quality of local businesses.
One important aspect of photos is the type of content being displayed. In August of 2015 we introduced a system that classified restaurant photos as food, drink, outside, inside, or menu. Since then, we have trained and put into production similar systems for coffee shops and bars, thus helping users more quickly find the photos they are looking for. More recently, we began to investigate how to make users happier by showing them more beautiful photos and improving our photo ranking system.
Understanding Photo Qualities
Comparing the quality of photos can seem like a very subjective task. What makes one photo preferable to another can depend on many factors, and may be different depending on the user who is performing a search. In order to provide a great experience for Yelp users, the Photo Understanding team had the challenging task of determining what qualities make photos appealing, and developing an algorithm that can reliably assess photos using these characteristics.
We first attempted to build a click rate predictor for photos using click data mined from our logs. Our hypothesis here was that those photos which were clicked a greater proportion of times would be noticeably better. However, this idea did not work that well, for a couple of reasons. For one, people will often click on blurry or text-heavy photos in order to enlarge them and understand what the image shows. In addition, because of the many ways photos are displayed on Yelp it was difficult to meaningfully compare metrics for particular photos.
Following this, we turned to various computer vision techniques, trying to discover intrinsic features of a given image that could be associated with a quality score. For example, one important feature for photographers is depth of field, which measures how much of the image is in focus. Using a “shallow” depth of field can be an excellent way to distinguish the subject of an image from its background, and photos uploaded to Yelp are no exception. In many cases, the most beautiful images of a given restaurant were very sharply focused on a specific entrée.
 |
 |
|
|
|
Another important feature of how people perceive photos is contrast. Contrast measures the difference in brightness and color between an object in an image and other nearby objects. There are several formulas for contrast, but most involve comparing the luminance, or light intensity of neighboring regions of an image.
 |
 |
|
|
|
Finally, the location of objects in an image with respect to one another can be a significant aesthetic consideration. Studies have shown, for example, that people have an innate predisposition towards symmetry in art. In addition, some photographers also promote what is called the “rule of thirds,” a method of aligning important elements of an image along certain axes to create a sense of motion or energy.
 |
 |
|
|
|
Using Deep Learning to Build A Photo Scoring Model
All of these considerations relied on understanding the relationship between regions of photos. So when it came time to implement a photo scoring algorithm, we wanted a method where this relationship was paramount. As a result, we were very keen on using a model called convolutional neural networks, or CNNs.
Over the past decade, CNNs have been hugely successful in image classification and processing tasks, such as facial recognition and molecular disease detection. Similar to ordinary neural networks, they apply a series of transformations to an input vector and use the output errors to dynamically improve future predictions. However, CNNs have a few additional layers that help to take advantage of the spatial features discussed above. Specifically, convolutional layers tile a set of filters across an image, and pooling layers downscale the output of previous layers in order to reduce computation.
To develop this model, we first needed to collect training data. One method of doing so would have been to manually label hundreds of thousands of photos as beautiful or not. However, this approach would have been costly, time-consuming, and highly dependent on the preferences of our graders. Instead, we were able to take advantage of the fact that when photos are uploaded to Yelp, they often contain additional information known as EXIF data.
In particular, we found that a good proxy for quality is whether a photo was taken by a digital single-lens reflex camera, or DSLR. These cameras give the photographer more control over which parts of the image are in focus, by adjusting the lens type and aperture size. Further, DSLR sensors are larger and more sensitive to light, allowing great photos to be taken in even very dim situations. Finally, people who regularly use DSLR cameras may have more experience and skill in capturing higher quality images.
Training our model on such photos allows it to learn important photo features and recognize great photos even when they are not taken by a DSLR camera.

Even though this photo was taken by an iPhone, our model gives it a very high score.
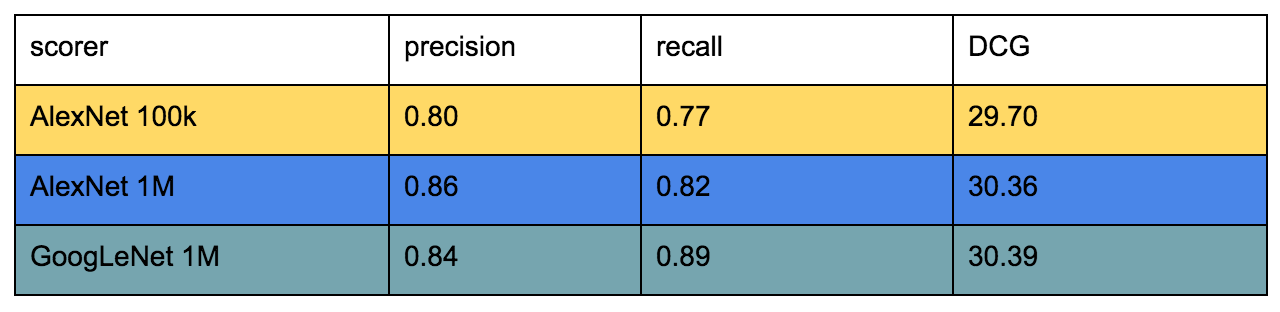
We tried several methods of training this model. Initially, we collected 100,000 DSLR and non-DSLR images to use as positive and negative labels, respectively, and fed these into a model known as AlexNet, which was created by researchers at the University of Toronto in 2012. To improve the accuracy of this model, we trained an additional model with more than ten times the previous amount of training data. Finally, we tested a model called GoogLeNet, which was developed by researchers at Google in 2014 and achieved state of the art performance by having significantly deeper layers than previous top-of-the-line models.
In each of these cases, we further evaluated the model against a dataset of thousands of images manually evaluated by Yelp engineers, which consisted of only those images which we could confidently say were very good or very bad. We saw that with each iteration, our ability to correctly identify good and bad photos improved.
Finally, to convert the results of our model to quality scores, we used the probability output by the final layer of the model that a given photo would generate a positive label. In other words, if our model predicts an 80% chance that the label should be “high quality,” we give that photo a score of 0.8. This gives us a straightforward way of converting the results of a binary classifier into easily ranked results.
The Bigger Picture
Our preliminary analysis showed that the photos algorithm promoted were indeed more focused, bright, and aesthetically pleasing. However, there were cases that prompted us to find ways of re-weighting and reordering certain images. As a result, we have put in place a system to combine multiple pieces of information to show users the best possible photos for a business.
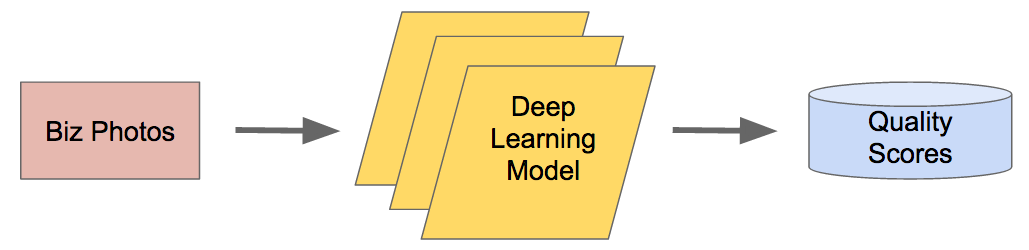
Photo Scoring Algorithm
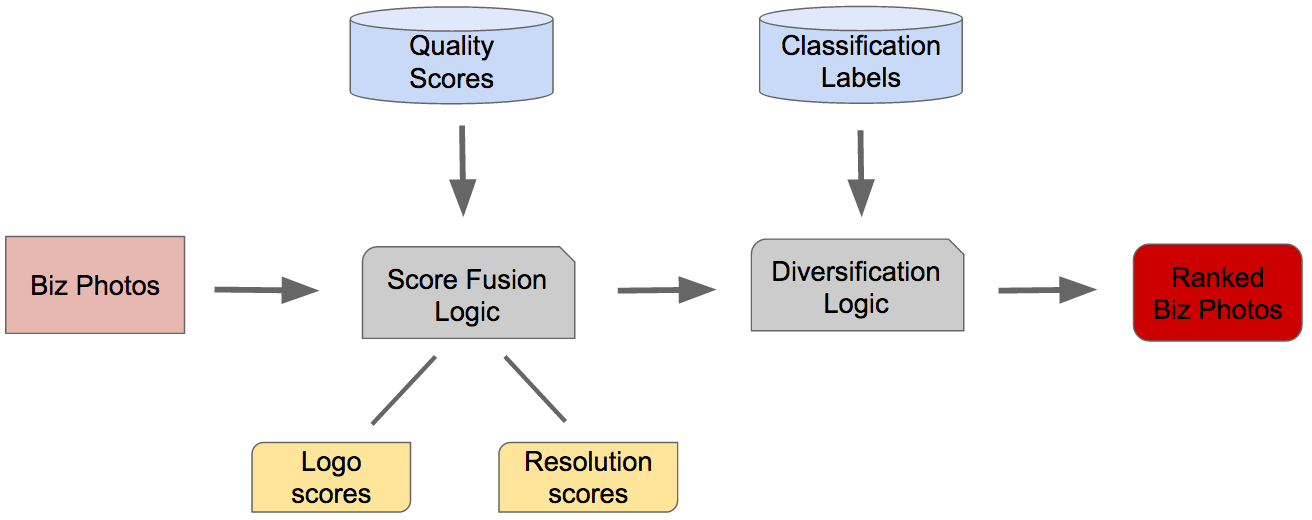
Business Photo Ranking Pipeline
In our current pipeline, we first retrieve all the quality scores for a business generated by the model described above. These scores are then adjusted based on characteristics such as the following:
- Logo filtering: We noticed that photos of logos often earned a high score from our model even though users have very little interest in seeing or clicking on them. This might include, for example, a poster that simply consists of the restaurant’s name. As a result, we trained a separate classification model based on the entropy of the image’s intensity histogram to lower the score of these images.
- Resolution: In order to standardize input to our neural network and speed up computation, we shrink each image to 227 by 227 pixels before feeding it in. However, this means that the model does not recognize whether a photo is too small to provide users with good content about a business. To deal with this, we downgrade photos which fall below a certain size threshold.
Finally, we use the labels determined by our classification algorithm to ensure that different kinds of photos are displayed in the top results for a business.
Application: Cover Photo Sorting
At Yelp, each business’s page showcases a few of its best photos, which we call cover photos. For many years we have chosen these photos purely by calculating a function based on likes, votes, upload date, and image caption. However, this approach suffered from a few drawbacks.
First, this system was highly subject to selection bias. Cover photos are viewed and clicked significantly more often than average. As a result, once a photo ends up on the business page, it is highly likely to remain there, even if more attractive and useful photos are uploaded at a later date. Additionally, relying solely on likes to determine prominent photos can end up promoting “clickbait” photos- that is, those that may have low relevance and quality but are upvoted due to their provocative nature.
Now, as a result of our scoring algorithm, we believe that the quality of cover photos for restaurants has significantly improved. See for yourself!

Old Version
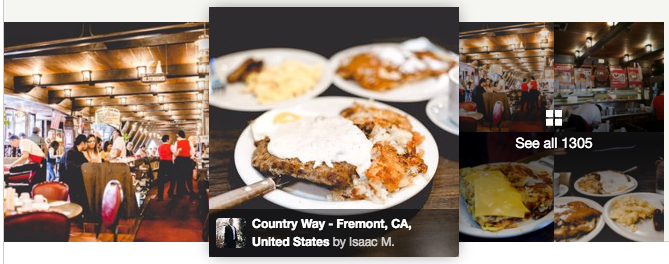
High Quality Version
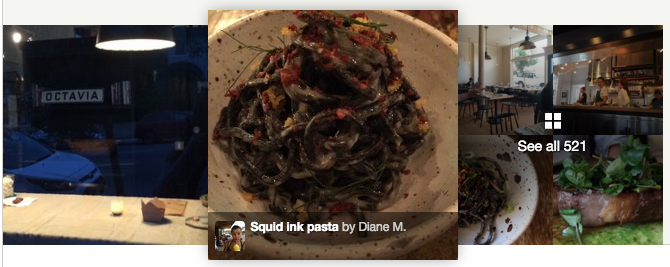
Old Version
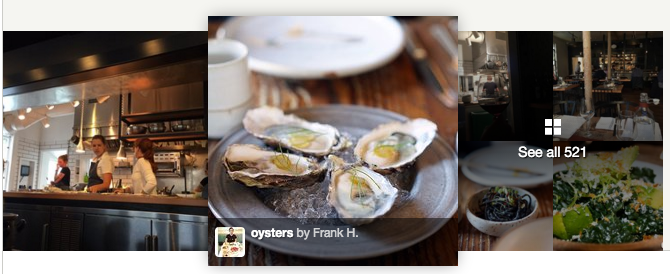
High Quality Version

Old Version

High Quality Version
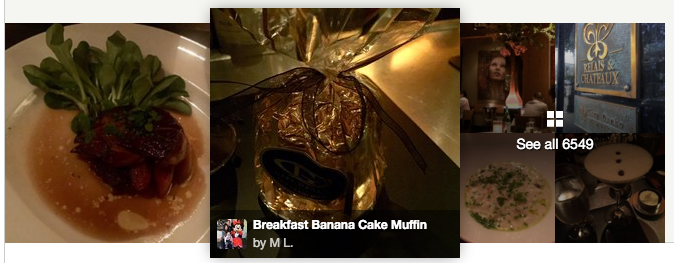
Old Version
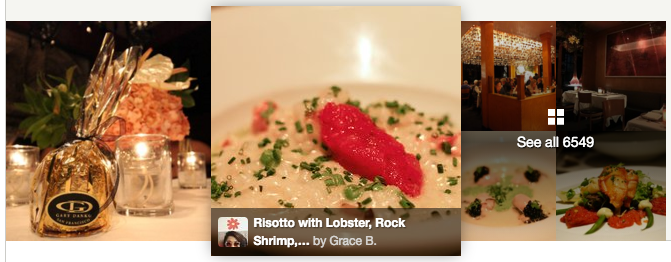
High Quality Version
What’s Next
While the feedback we have received on this change has been very positive, there is more work we can do to improve the usefulness and relevance of our photos. The Photo Understanding team is working on a more comprehensive system that takes into account the type of business and photographer identity, as well as the user feedback and quality signals we discussed above, to provide an even better experience for Yelp users. Stay tuned for another update in the future!
Acknowledgements: The photo scoring system was designed and implemented by Wei-Hong C., Alex M., Colin P., Prasanna S., Joel O., and Frances H.