Moving Yelp's Core Business Search to Elasticsearch

-
Umesh Dangat, Software Engineer
- Jun 29, 2017
While newer search engines at Yelp typically use Elasticsearch as a backend, Yelp’s core business search used its own custom backend, built directly on top of Lucene. This system was one of the oldest systems at Yelp to still be deployed in production. Some features of this custom search engine were
- Distributed Lucene instances
- Master-slave architecture
- Custom text analysis support for various languages
- Custom business ranking which relied mostly on using business features (think business attributes like reviews, name, hours_open, service_areas, etc.)
- Derived Yelp analytics data to improve quality of search results; e.g. most popular queries for a business
Problems with the Legacy System
Suboptimal Support for Realtime Indexing
Our legacy system used a master-slave architecture where masters were responsible for handling writes (indexing requests) and the slaves would serve live traffic. A master instance was responsible for taking a snapshot of the Lucene index and uploading it to S3 so that the slave could download it periodically and serve fresh data. Thus there was a delay in the updated index being served by the queries at search time. Some search features, such as reservations and transactions, could not afford this delay (a few minutes), and required the indexed data to be served instantly (within a few seconds). To solve this problem, we had to use another realtime store, Elasticsearch, and query it in parallel to the business store (legacy search store) which meant that the application service would then need to compute the final search results based on both results. As we grew, this approach did not scale well and we had to deal with performance issues arising from combining and sorting results in the application layer.
Slow code pushes
We have a large team of developers working constantly on improving the ranking algorithm for the search results. We end up making code pushes to the underlying search ranking algorithm multiple times a day and with the legacy system, each code push took several hours. Almost all microservices at Yelp now use PaaSTA as the deployment vehicle. At the time, the legacy system was probably the largest “microservice” at Yelp using PaaSTA. Our data was large enough that it had to be sharded. We used a two-tier sharding approach.
- Geosharding: We split the businesses into separate logical indexes based on their location. For example, a business in San Francisco would be in a separate index from a business in Chicago because the shard might split down the middle of the country.
- Microsharding: We further split each geographical index into multiple “microindexes” or “microshards”. For this we used a simplistic mod-based approach. For example
business_id % n, where “n” is the number of microshards desired
Thus our final lucene index would be
<<geographical_shard>>_<<micro_shard>>
Each Lucene index-backed process was its own service instance. We had to account for replication as well to ensure availability. For example each <geoshard>_<microshard> would have multiple instances called “replicas” to guard against outages of instances. This meant we had a large number of service instances and each instance would take some time to start up since each instance needed to
- download tens of gigabytes of data from S3
- warm the Lucene index to preload Lucene caches
- compute and load various data sets into memory
- force garbage collection, since startup created a lot of ephemeral objects
Each code push meant we would have to cycle the workers and they’d have to go through this process each time.
Inability to do certain feature work
Reindexing all of the data was time consuming which meant that the cost of adding some new features would become exponentially more expensive. We wouldn’t be able to do things like
- Quickly iterate on our sharding algorithm.
- Iterate on analyzers. We developed custom language-based analyzers to tokenize text. Search engines like Lucene use specific analyzers at index time (to do things like generate tokens, filter stopwords) and generally prefer to use the same analyzer at query time so the tokenized query string is found in the inverted index. Changing analyzers means reindexing the entire corpus so we generally tried to stay away from optimizations in our analysis codebase.
- Indexing additional fields to improve ranking. Business attributes are one of our primary signals to rank a business in search result. As our business data got richer we could improve our ranking using this data. Sadly, we had to use other realtime stores to lookup these business attributes since a change to our legacy system was an ordeal.
- We were pushing the JVM heap limits with respect to amount of data we stored in auxiliary data structures. We had custom data that could not be stored on the Lucene index but this data was needed to rank businesses (for example, storing the most popular queries for each business). As this data grew it became harder to scale since this was limited by the JVM heap size.
At this point, we became convinced that the legacy system had to be overhauled. So what would be the design of the new system? First let’s take a look at the existing system so we know the challenges we need to solve in the new system without introducing any regressions.
The Legacy System
Legacy business search stack
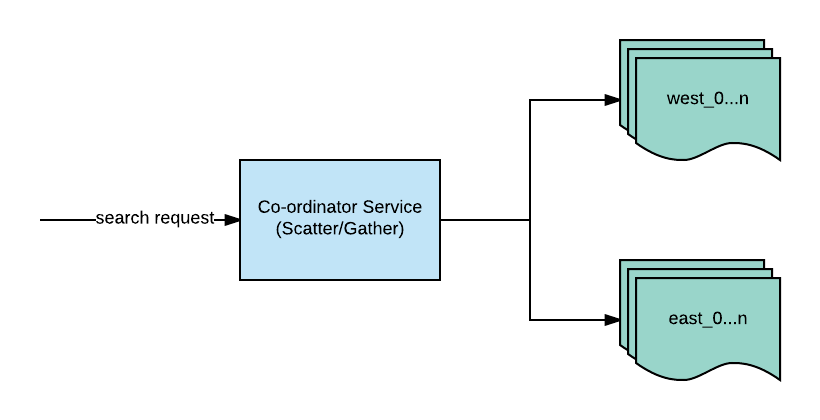
Legacy business search stack
It starts with search requests coming into the coordinator service. This service figures out the corresponding geographical shard to use (based on the physical location of a business) and forwards the request to the appropriate shard, in this simplified case either west or east. The request would be broadcast to all the microshards (2nd tier of sharding for horizontal scaling) within that geographical shard. After getting the result from one to N microshards the coordinator would combine the results.
Microshard (Single legacy search node)
Let’s dive into a single node and go through how we go from a query to a result.
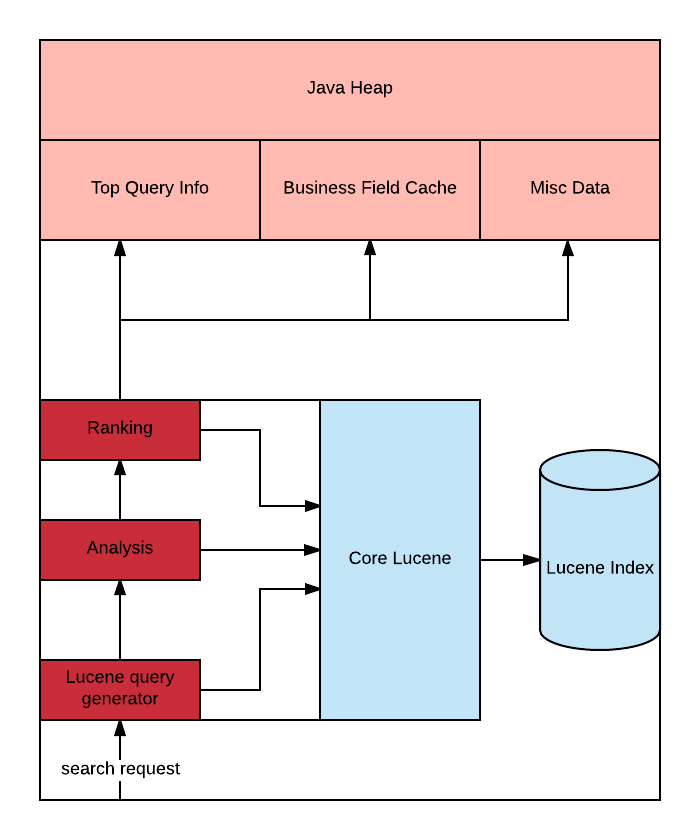
Microshard
A search request is transformed into a Lucene query, which is then sent to the Lucene index. Lucene returns a stream of results as per the collector specified. One can think of the collector as the ranker, the thing deciding the order of the results. This is where the ranking logic is applied. Ranking logic at Yelp uses a number of heuristics to determine the end result ranking. These heuristics include looking into certain business related data
- Business Field cache: forward index for a business (things like business attributes)
- Top Query Info: Data derived from our user activity
- Misc data: includes Yelp-specific data like Yelp categories
With this, we are now ready to define the design goals of the new system.
Goals for the Next-Generation Business Search
Based on the previous sections, we can quickly summarize some of our high-level goals as:
- decoupling of application logic from the backend used
- faster code pushes
- ease of storing custom data and forward indexes that powered the search results ranking (e.g. context specific data)
- real-time indexing
- linear performance scalability with respect to growth of our business data
We looked at Elasticsearch and it seemed to solve some of these goals for us out of the box.
Challenges
Decoupling Application Logic from Backend Used
The ranking code does not need to know what backend it runs on. Thus it made sense to decouple this code from the underlying search backend store. In our case this is a Java codebase which means we can deploy it as a jar. More concretely, we had to be able to run our ranking jar within a distributed search environment. Elasticsearch offers plugin support which allows us to do exactly this. We took care to isolate our ranking code from the Elasticsearch plugin implementation details.
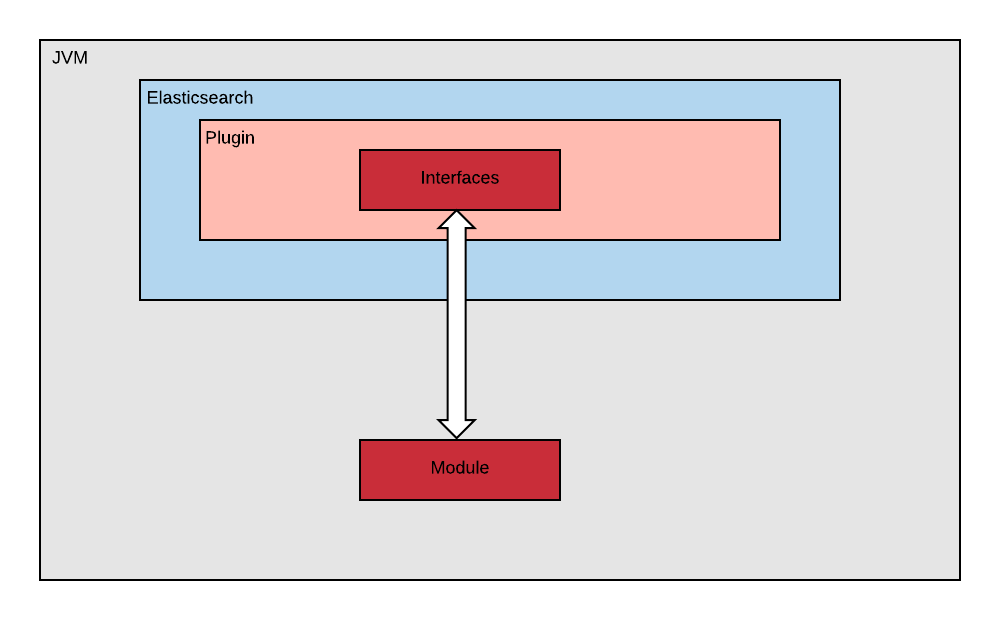
Decoupling plugin from scoring jar
Interfaces
We have two primary definitions that allow us to decouple the ranking code from relying on the underlying Elasticsearch libraries directly. Thus none of our ranking code has a hard dependency on Elasticsearch (or Lucene), giving us the flexibility to run this ranking code on any other backend.
- The Document interface is used by the module/ranking code to lookup business attributes. However the ranking code does not know about its implementation. The concrete implementation for Document is injected by the Elasticsearch plugin.
- The Scorer interface is implemented by the module. Again, it has no dependencies on Elasticsearch. This Scorer is loaded by a private classloader inside the elasticsearch plugin.
Module
The module is the ranking code where the heart of the search relevance logic lives. This is the code that is pushed to production potentially multiple times a day. This jar is deployed on our Elasticsearch cluster and is then loaded inside the Elasticsearch plugin.
Plugin
The Elasticsearch plugin houses the ranking code. This is mostly Elasticsearch-related wiring code that loads the module code and delegates to it for ranking documents.
Faster pushes
As stated earlier, we push code multiple times a day but restarting Elasticsearch for each push was not an option for us. Since we built our relevance module to be decoupled from Elasticsearch itself, we were able to reload it without restarting the entire Elasticsearch cluster.
We start by uploading our ranking jar to S3. We added an Elasticsearch REST endpoint that is invoked during the deploy process so that the Elasticsearch plugin can reload the specified jar.
Once this endpoint is invoked it triggers the loading of the module.jar through a private class loader that loads the entry point top level class from the module.jar itself
- Download the module jar to a Path
- Create private classloader based off the Path
- Use the URL of the module.jar to create URLClassloader
- Create the instance which implements ScorerFactory. Note the use of asSubclass and passing argument Environment. Environment is another interface which provides some resources needed by the module code.
- ScorerFactory has a createScorer method that returns the Scorer instance
Then we have the Elasticsearch plugin code that invokes the reloaded Scorer
- Create the elasticsearch Executable script and pass it our scorer instance which was “hot loaded” previously
- Elasticsearch executable script finally uses the scorer to score and pass the document itself. Note the “this” passed in. That is how the document attribute lookups aka doc value lookups in elasticsearch can actually happen inside elasticsearch plugin while the module code simply uses the interface.
Loading custom data
One of the original problems with the legacy system was that the memory footprint of a single search node was getting larger with time; the primary reason being that we loaded a lot of auxiliary data on the JVM heap. With Elasticsearch we were able to mostly offload these in-memory data structures to doc values. We had to ensure our hosts had enough RAM available so that Elasticsearch could make use of disk cache efficiently when retrieving these doc values.
ScriptDocValues worked well for most types of attributes like String, Long, Double, and Boolean, but we did need to support custom data formats as well. Some businesses have context-specific data stored that is computed separately from search. This signal allows our search to help boost the score of a business for things like “chance of business being associated with a search query given its most popular queries” based on past history. We represent this structure like so:
Custom data format
If we wanted to store this data per business as a doc value it would have to be serialized
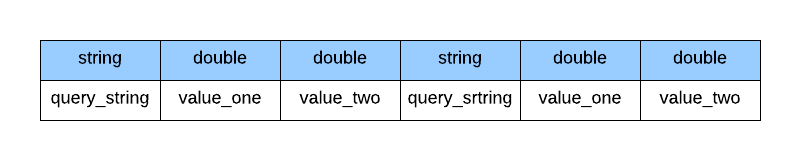
Serialized layout of custom data per business
Since query strings are of arbitrary lengths and take up more space we decided to represent them using positive integers. We identified a string with a monotonically increasing long value. This allowed us to save space by using long instead of string and keep the records to fixed sizes.
So, let’s say we have two strings, “restaurants” and “mexican restaurants”. Our plugin would identify “restaurants” as 1 and “mexican restaurants” as 2. The strings themselves would be replaced with the long value corresponding to the query so you would end up with “1” and “2”. Thereby allowing us to represent strings with fixed size of Long.Bytes. This made it easier for us to serialize and deserialize our query related data. This is a simplified example, in practice we need to store analyzed form of the string based on the language e.g. “restaurants” could be tokenized to “restaur” in english.
Now, we could change our data structure to store only longs and doubles as the strings got replaced by their references:

Serialized layout of fixed size length entries per business
The user query and its associated values per business can be represented as a list of objects.
With this we can index all the records for a business as binary data type in Elasticsearch using our custom serialization.
One issue that arose was looking up binary data using ScriptDocValues. We submitted a patch to Elasticsearch to support this, allowing you to do something like:
Once we read the ByteBuffer out of Elasticsearch we could search on the query_id we wanted, for example, the query_id the user issued, inside the serialized QueryContextInfo[]. A match on query_id allowed us to retrieve the corresponding data values; i.e. QueryContextInfo for the business.
Performance Learnings
As part of building our new system, we spent time making sure it would outperform our legacy search system. Here are some of the lessons we learned through this process.
Find Your Bottlenecks
The Elasticsearch Profile API is a useful way to find bottlenecks in your query.
Scoring is Linear and Scales Well With Sharding
In our case, scoring was the bottleneck since we rely on many features to rank the results. We realized that we could horizontally scale by adding more shards which meant we got more parallelism out of Elasticsearch at query time since each shard had fewer businesses to score. Be warned when doing this; there is no magic number since these depend on your recall size and your scoring logic, amongst other things. The performance growth with regard to the increase in number of shards is not unbounded. We had to find our sweet spot mostly through trial and error by increasing the shards and reindexing data.
Use Java Profiling Tools
Using Java tools like jstack, jmap, and jprofiler gave us insights into hotspots (computationally intensive components) in our code. As an example, our first implementation of binary data lookup involved deserializing the entire byte array into a list of Java objects, namely List
We reworked our algorithm by doing a binary search on the serialized data structure without deserializing it. This allowed us to quickly search for the query_id if it is inside the blob for this business. This also meant we do not need to incur costs of garbage collection for deserializing the entire blob into Java objects.
Conclusion
Moving Yelp’s core search to Elasticsearch was one of the more challenging projects undertaken by the Yelp search team in the recent past. Since this was a technically challenging project in regards to its feasibility, it was important we iterated on this project in fail-fast mode. In each short iteration we tackled the high risk items like hot code loading, ability to support custom data in Elasticsearch, and Elasticsearch performance, which allowed us to gain confidence in our approach while not committing for far too long to unknowns. Ultimately, the project was successful and now we are able to reindex data regularly and add new fields easily, allowing us to improve our ranking algorithm in ways we were unable to before. Our code pushes now take a few minutes instead of a few hours. Maybe most importantly, we do not need to maintain a legacy system which was hard to understand, making it is easier to find developers who know and want to learn Elasticsearch.