Generating Web Pages in Parallel with Pagelets, the Building Blocks of Yelp.com

-
Arnaud Brousseau, Software Engineer
- Jul 6, 2017
At Yelp, pagelets are a server-side optimization to parallelize the rendering of web pages across multiple web workers (loosely inspired by Facebook’s Big Pipe). We’ve implemented this and have been running it successfully in production for a while now. This blog post is about our journey implementing and rolling out pagelets, including what we’ve learned since the initial rollout.
Pagelets at Yelp: an overview
Main and pagelet workers
Usually a request made to Yelp is fulfilled by a single web worker. This worker is in charge of generating a response (in the form of an HTTP packet, with headers and body) from start to finish.
Pagelets parallelize server-side processing by issuing multiple asynchronous HTTP requests to render sections of a page. When pagelets are active, several processes are working in parallel to compute the response:
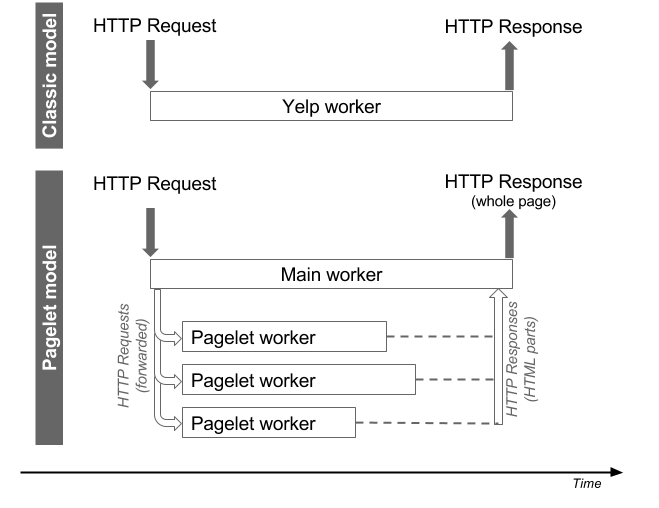
Pagelets: MVCs within an HMVC
Each pagelet is a small MVC (Model-View-Controller), responsible for rendering a portion of the final page. Since the main worker is also its own MVC, the main worker and pagelet workers taken together are often referred to as HMVC (Hierarchical Model-View-Controller). The rendering of a page looks like the diagram below – which only includes two pagelets for the sake of simplicity:
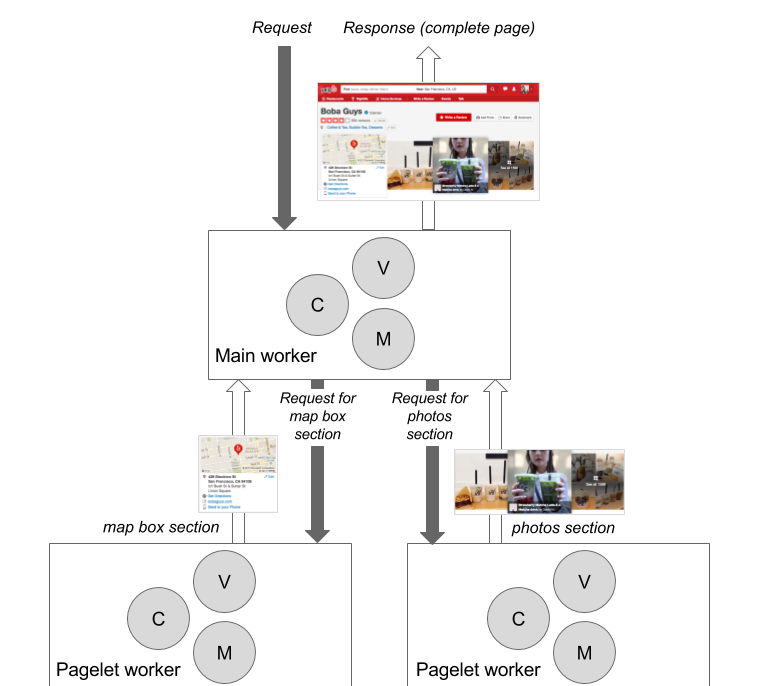
The main worker, in charge of the rendering of the overall page, forwards the request to enable parallel processing in pagelets. In this case, mapbox and photos sections are rendered in parallel.
Each pagelet is implemented as an HTTP endpoint that returns a blob of HTML and takes care of data loading, marshalling, and templating. Pagelets can be thought of as a mini-webapp, using vanilla HTTP. They have their own URI, just like every service in our infrastructure.
This design has a few happy consequences:
- Full-stack developers, used to working with HTTP, find it easy to debug pagelets
- Pagelets are understood by product managers since they are defined by high-level, natural UI boundaries (sidebar, navigation, map box, review highlights, etc)
- The design guarantees no coupling between pagelets, which makes their code easy to change without worrying about the rest of the page
- Pagelets are self-contained, and portable: their content can be moved around easily
The main trade-offs we are making with this design are overhead (due to issuing and handling separate requests) and lack of shared context (the self-contained nature of pagelets prevents this, which makes things like logging a bit more challenging).
Show me the code!
Here’s a concrete example using the pagelet generating the map box section of our business details page.
Controller (we use Pyramid)
@pagelet_view_config(
route_name='biz_details_map_box',
renderer='templates/lib/biz_details/map_box#render.tmpl',
)
def map_box(request):
map_box_presenter = get_map_box_presenter_for_request(request)
return {
'mapbox': map_box_presenter,
'tld_country': request.tld_country,
}
config.add_route('biz_details_map_box', '/biz_details/map_box')View (we use Cheetah)
#def render(mapbox, tld_country)
## Given a MapBoxPresenter, display its contact and map info
<div class="mapbox" data-lightbox-page-title="$mapbox.directions_presenter.title" data-map-library="$mapbox.library">
$render_map($mapbox)
$render_biz_contact_info($mapbox, tld_country)
</div>
#end defModel (we use SQLAlchemy for data loading)
def get_map_box_presenter_for_request(request):
"""Builds a map box presenter from a request.
More specifically, this returns a map box presenter built from things
that can be derived from a request
:param request: A request object
:return: A MapBoxPresenter for the given request
:rtype: MapBoxPresenter
"""
# "logic" is a reference to our collection of SQLAlchemy models
logic = auto_logic_from_request(request).logic
business_dict = business_dict_from_biz_details_request(request, logic)
business_id = business_dict['id']
business_attribute_dict = logic.BusinessAttribute.load_attributes(business_id)
# [snip, you get the idea -- we load data and format it]
return MapBoxPresenter(...)So, a call to /biz_details/map_box returns the markup representing the map box
on the page. Below we show how the main worker loads pagelets.
Main controller
# Generates a configuration which enumerates all pagelets on the current page
pagelet_config = get_pagelet_config(self.request, site='www', pagelet_namespace='biz_details')
# Creates a loader object capable of loading/rendering pagelets
pagelet_loader = create_loader(self.request, pagelet_config)
# Kick-off the asynchronous request to fetch content for all pagelets in the loader
pagelet_loader.load()
# do work....
env['rendered_call_to_action'] = pagelet_loader.render('/biz_details/call_to_action')
env['rendered_map_box'] = pagelet_loader.render('/biz_details/map_box') # renders our pagelet from above
# more renders (for all pagelets)
return self.render_template('biz_details', env=env)Main template
<!DOCTYPE html>
<html>
<!-- [snip] -->
<div class="biz-page-subheader">
<div class="mapbox-container">
$rendered_map_box # that's it!
</div>
<div class="showcase-container">
<!-- [snip] -->
</html>Pagelet loading and rendering
Pagelet requests are performed through Fido, an open-source HTTP library built on top of crochet/twisted. In practice, the processing of a pagelet-enabled page happens in 3 steps as seen from the main pagelet worker:
def handle_request(request):
# 1. Load: as early as possible, instantiate HTTP futures to send requests
# out for rendering.
future1 = fido.fetch('/pagelet/path1') # this is non-blocking
future2 = fido.fetch('/pagelet/path2')
# etc
# 2. Work: fetch and transform data, orchestrate other things while pagelet
# workers are busy doing their job.
page_data = do_synchronous_work()
# 3. Render: read the value of all pagelet HTTP futures and assemble the
# final response.
pagelet1 = future.wait(timeout_in_seconds) # this blocks
pagelet2 = future.wait(timeout_in_seconds)
# pagelet1/pagelet2 contain the fully rendered HTML of a portion of the page!
return assemble_response(page_data, pagelet1, pagelet2)Note that conceptually the same HTTP request is used as input to both the main and pagelet worker. This is important since it makes asynchronous and synchronous rendering modes transparent to pagelet code. To make this play well with routing, we modify a couple of HTTP headers:
- An asynchronous pagelet request is differentiated with a special header:
X-Yelp-Pagelet: true - The original request path (say,
/biz/foo) is moved toX-Original-Pathbefore being forwarded downstream. The request path is replaced with the path corresponding to the part of the page which we want to render e.g./pagelet/map_box
Once an HTTP request is received, the pagelet worker reconstitutes the original request object so that the application code is unaware of the context it’s rendered in (the pagelet worker when pagelet requests are made asynchronously, the main worker when we fallback to synchronous rendering in the main worker).
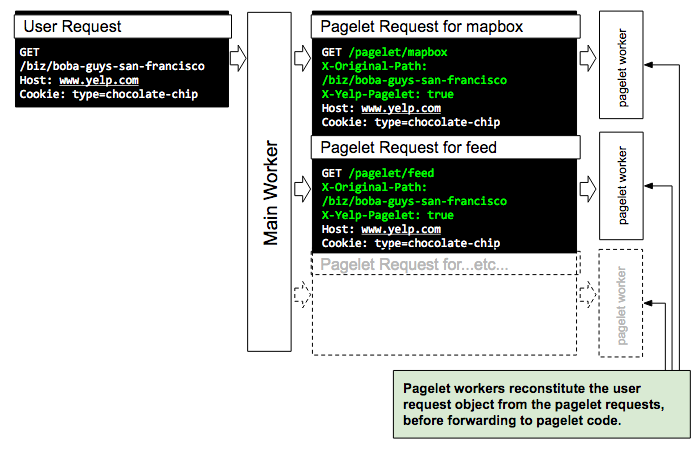
User requests are forwarded to pagelet workers with a few headers tweaks to enable routing to work correctly.
Failure mode: synchronous fallback
We made the decision early on to avoid partial failures: we’d rather deliver an error page than a partially rendered, broken page. This decision was made with users in mind both directly (it’s not cool to get a half-rendered page!) and indirectly (crawlers should not index incomplete content). This dictated our failure mode strategy: try as hard as possible to complete the rendering, otherwise error out. That’s why we introduced synchronous rendering. When a pagelet fails to render asynchronously, the main worker tries to render the failed pagelet synchronously (in the same Python process). If this fails still, a user-facing error is returned (500 error page).
Results
Here are internal performance graphs of our server-side timings for business details pages: Our pagelet system is disabled at the start of these graphs and gets enabled at 2:25pm (each graph is for one datacenter):
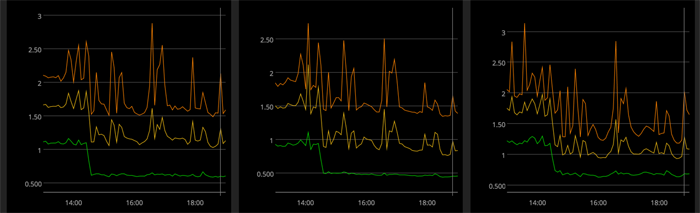
Timings when pagelets went from disabled to enabled across our datacenters.
The dropoff in server-side timings (which happens a little after the 2pm mark mark) is substantial in all the datacenters graphed here, for all percentiles (50th, 75th, 99th).
Rolling out pagelets over time: improvements & lessons learned
Over the past few years, we have gradually rolled out pagelets to a number of pages. Along the way, we have hit some issues and made a number of improvements.
Enhanced configuration
In order to improve stability, we’ve made pagelets more configurable. For example:
- Overall kill-switch to let our SRE team turn off this system altogether as fast as possible if it causes operational problems.
- Tighter configuration around timeouts. More specifically, the ability to tune timeout values per pagelet instead of a global value.
- Integration with our experiment systems to release pagelets gradually (to 1% of traffic, 5%, etc). This has proven very valuable when implementing new pagelets or rolling out existing pagelets to new pages.
Operational problem #1: self-DoS
The main and pagelet workers share the same codebase and originally ran on the same host. Essentially, pagelet requests were routed back to localhost. This was done to ensure that the pagelet workers use the same code version than the main worker even when deployments are ongoing (Yelp ships changes several times a day).
It turns out that fanning out to localhost is a good way to overload our own systems. As we rolled out more and more pagelets, a user facing request turned into 3, 4, 5, 10 pagelet requests. This requires each host to have enough free workers at any given time to handle the original request and all subrequests. Otherwise it blocks on responses it cannot afford to compute. After some rough times when our traffic was at its peak, we quickly implemented a capacity check to make sure a host has enough free workers to fulfill the pagelet requests. If that’s not the case we fallback to rendering pagelets synchronously.
Operational trouble #2: resource utilization
We’ve seen from the previous point that capacity planning with pagelets gets tricky since it requires accounting for local fanout (e.g. 1 request turning into 10). That means a web server has to constantly reserve spare capacity to enable pagelets to render asynchronously. Since most of our requests are not pagelet-enabled (e.g. mobile APIs responses do not use pagelets, but are served from the same web servers), we end up needing a lot of extra capacity even for requests that don’t need it. Put bluntly: pagelets make resource utilization tank. For this reason we decided to make a change to treat pagelets as just another user-facing request and let these requests be distributed across our fleet of servers1
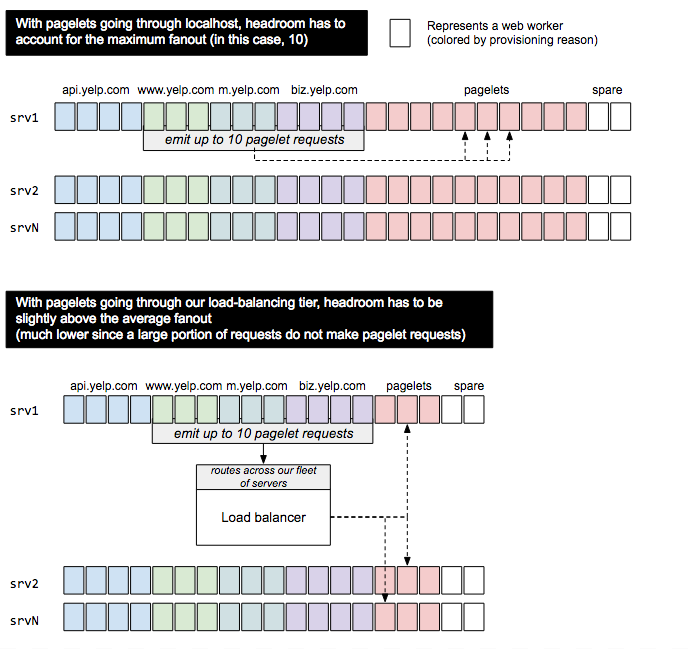
Resource utilization with pagelets, and how using a load balancer made things better
In practice, this seemingly small change led to much better resource utilization in our PaaSTA production cluster. This translated to considerable cost savings because we were able to significantly downsize the size (CPU, memory) of the Docker container used to run our main app:
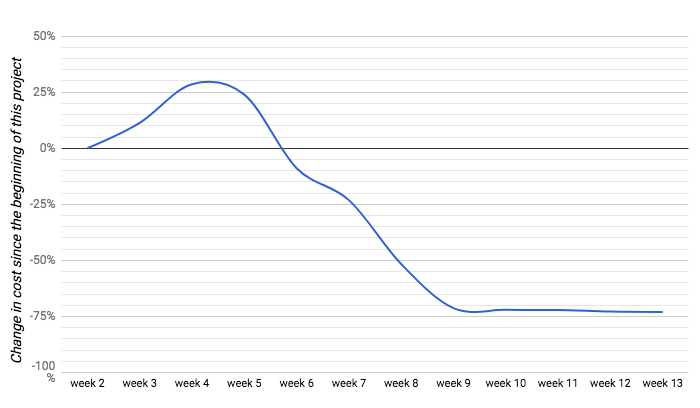
Relative change in cost in our production infrastructure
While the improved resource utilization contributed directly to the cost savings, the smaller container size also enabled other infrastructure improvements that reduced cost even more. For example, we were able to optimize our Amazon Spot Fleet usage and auto-scaling strategy to reduce cost further.
No such thing as a free lunch
Performance optimizations like this one (taking advantage of parallelism) aren’t free. They do have overhead! For each pagelet, we’re issuing an HTTP request and receiving a response from across the wire. We’ve measured the overhead of rendering a page through asynchronous pagelets compared to inline (by rendering pagelets in the same process) and found that rendering pagelets asynchronously adds a 20% CPU overhead. That’s expected since issuing HTTP calls, parsing responses, and re-entering the request context is extra work that doesn’t have to be done when working within the same Python process.
In other words, pagelets trade off CPU capacity for better response time for Yelp users. Well worth it!
1: The astute reader will note that this optimization means that we cannot guarantee version matching during deploys. To work around this problem we’re now carrying the version information through pagelet requests with a new header and dropping requests that don’t match. Our synchronous fallback catches this and renders the requests hitting the wrong version in the main worker.
Want to become one of our performance engineers?
Yelp engineering is looking for engineers passionate about solving performance problems. Sounds interesting? Apply below!
View Job