Scaling Gradient Boosted Trees for CTR Prediction - Part I

-
Niloy Gupta, Software Engineer - Machine Learning
- Jan 9, 2018
Building a Distributed Machine Learning Pipeline
As a part of Yelp’s mission to connect people with great local businesses, we help businesses reach potential customers through advertising and organic search results. The goal of Yelp’s advertising platform is to show relevant businesses to users without compromising their experience with the product.
In order to do so, we’ve built a click-through-rate (CTR) prediction model that determines whether or not to serve ads from a particular advertiser. The predicted CTR determines how relevant the business is to the user’s intention and how much would need to be bid to beat a competitor in the auction. It is crucial to predict the most accurate CTR as possible to ensure consumers have the best experience.
Previously, we used Spark MLlib to train a logistic regression model for CTR prediction. However, logistic regression is a linear classifier and cannot model complex interactions between covariates unless explicitly specified or engineered.
Consequently, we decided to use Gradient Boosted Trees (GBTs), a nonlinear classifier and a powerful machine learning technique that uses an ensemble of weak learners (decision trees, in this case) to train on the residuals of the previous classifiers and form a more accurate ensemble.
The time complexity of serially constructing a GBT model with T trees each of depth D is O(TDFnlogn), where F is the number of features and n is the number of training samples. Thus, training these GBTs on hundreds of millions of training samples with thousands of features is a computationally expensive task. It took almost two days to train a GBT model on 1/10th the number of available training samples using a single large machine. This makes it challenging to iterate on the model for feature engineering and hyperparameter tuning purposes. As a result, we needed to adopt a distributed approach for training.
Our machine learning training pipeline is comprised of four stages: Sampling, Feature Extraction, Model Training, and Model Evaluation.
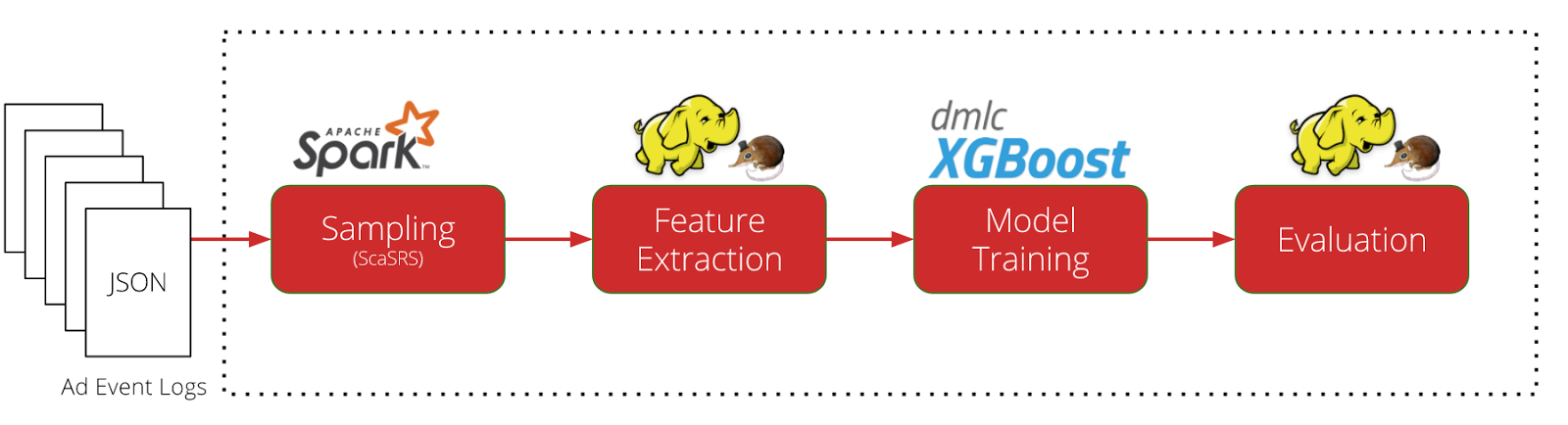
Figure 1. CTR model training pipeline is comprised of four stages: sampling, feature extraction, training, and evaluation. Each phase is run on AWS EMR in order to scale to our large datasets. We use a variety of open source tools including mrjob, Apache Spark, Zeppelin, and DMLC XGBoost to scale machine learning.
In the sampling phase, we implemented the ScalableSRS algorithm to generate a train-and-test set from our web logs. ScalableSRS has better theoretical guarantees than Bernoulli Sampling and scales well to large datasets. We then convert the sampled logs into a sparse feature matrix for the feature extraction phase. After the model is trained, we evaluate it against the test set, generating offline metrics for analysis. For these data wrangling tasks, we rely on tools like mrjob, Apache Spark, and Apache Zeppelin.
For model training, we use XGBoost, a popular library for training gradient boosted trees. Since our datasets are large, we used data parallelism techniques to train our models.
Some of the optimizations incorporated to speed up training include:
1. Algorithmic Optimizations
We use XGBoost’s “approx” method for determining the split at each node, which transforms continuous features into discrete bins for faster training. Although fast at training, XGBoost’s “hist” and LightGBM’s voting parallel algorithm did not converge to the same accuracy as “approx.” As we re-engineer our feature space, we intend to investigate this further.
To prevent unnecessary corrective training iterations, we tuned our hyperparameter search space for our dataset. For example, since ad clicks are much less common than non-clicks, we tuned the max_delta_step parameter to prevent gradient explosions or large step sizes. We also developed our own early-stopping logic for our dataset, balancing the demand of training highly accurate models that don’t overfit (i.e. number of trees) and the cost of computing them in real-time (scoring more trees adds to service side latency).
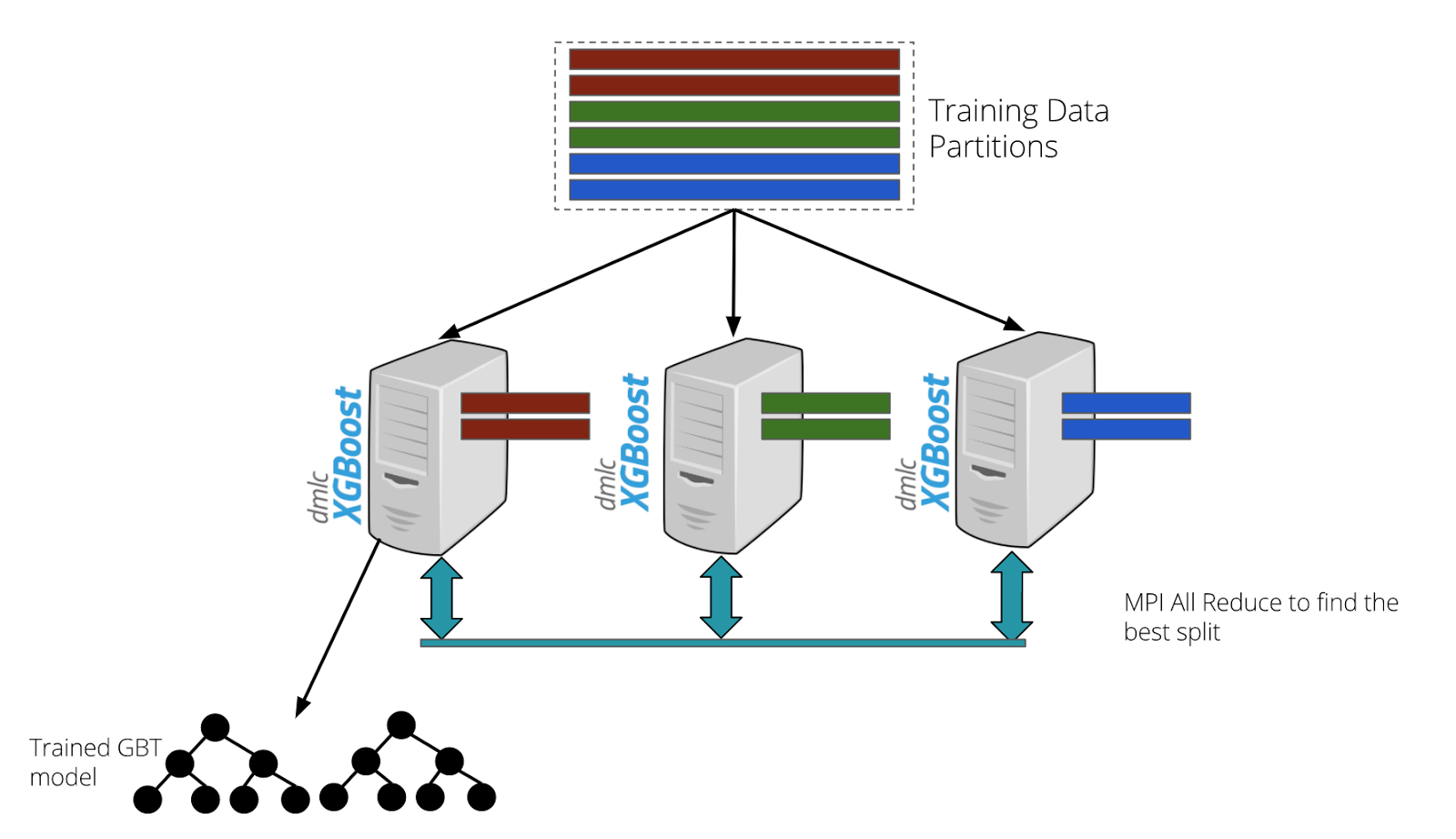
Figure 2. The GBT models are trained using a data parallel approach using distributed xgboost. The training process is fault-tolerant and includes hyperparameter selection using k-fold cross validation.
2. Distributed System Optimizations
Optimizing the training time and cost also involves configuring the number of machines, type of machines, number of worker threads, and memory. Adding more machines to the cluster reduces training time before it is dominated by network latencies. Deeper trees require more memory for the workers to cache the information in the nodes. After model tuning and a period of experimentation, we were able to configure 5 workers per node, running on 50 machines (each machine has 36 cores and 60 GB of RAM). In addition, using YARN’s DominantResourceCalculator (which takes CPU and memory into account) instead of the DefaultResourceCalculator (which only takes memory into account) proved vital for us to maximize our resource utilization.
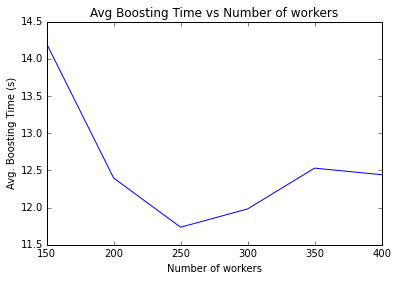
Figure 3. The average time for tree construction reduces with the increase in the number of workers before network latencies begin to dominate.
3. Ancillary Optimizations
We also integrated feature importance plot generation and feature summary statistics into the pipeline to make analysis and iteration easier. XGBoost’s “refresh” updater provided a cheap way to retraining our models on newer datasets. We also implemented model checkpointing and automated retries and recoveries to make the training pipeline robust to intermittent failures.
Conclusion
With an automated distributed training pipeline in place, we were able to train and launch a GBT model in production. We observed a whopping 4% improvement in mean cross entropy (MXE) on our offline test set and a significant increase in online CTRs. Moreover, we were able to reduce training time to less than 3 hours at a third of the original cost.
Much like training GBTs on large datasets, evaluating these large models with millions of nodes online is also a challenge. In the next part of this two part blog series, we will discuss how we scaled online prediction using gradient boosted tree models to meet our latency requirements.
We have open sourced our Scalable SRS Spark implementation and the PySpark XGBoost wrapper.
If you are interested in building state of the art machine learning systems at Yelp check out our careers page!
Acknowledgements
This project had a number of key contributors we would like to acknowledge for their design, implementation, and rollout ideas: Ryan Drebin, Niloy Gupta, Adam Johnston, Woojin Kim, Eric Liu, Joseph Malicki, Inaz Alaei Novin and Jeffrey Shen.
References
- Practical Lessons from Predicting Clicks on Ads at Facebook
- XGBoost: A Scalable Tree Boosting System
- Ad Click Prediction: a View from the Trenches
- Scalable Simple Random Sampling and Stratified Sampling
- Optimization in Parallel Learning for Gradient Boosted Trees
Build Machine Learning Systems at Yelp
Want to build state of the art machine learning systems at Yelp? Apply to become a Machine Learning Engineer today.
View Job