Scaling Gradient Boosted Trees for CTR Prediction - Part II

-
Niloy Gupta, Software Engineer - Machine Learning
- Jan 17, 2018
Growing Cache Friendly Trees
In case you missed it, Part I of this blog series outlines how we built a distributed machine learning platform to train gradient boosted tree (GBT) models on large datasets. While we were able to observe significant improvements in offline metrics, the resulting models are too large for standard XGBoost prediction libraries to meet our latency requirements. As result, we were unable to launch the models in production as we needed to serve ads within 50ms (p50) and evaluating these large models caused time-out exceptions.
This article will discuss how we compressed and reordered the trees to make online inference faster and announce that we have open sourced the GBT scoring library for the benefit of the machine learning community.
For a bit of background, Yelp’s ad delivery service predicts click-through rate (CTR) for tens of thousands of candidates per second. Evaluating a GBT model has a time complexity of O(Td) and a space complexity of O(T2d), where T is the number of trees and d is the depth of each tree. A typical model contains millions of nodes and on the order of a thousand trees, making online model inference in real-time a challenge.
One basic implementation of a binary decision tree involves connecting the nodes with pointers, however nodes are not necessarily stored consecutively in memory with this implementation. However, since space complexity dominates time complexity, most of the model evaluation time is spent in memory lookups. To reduce this effect, a popular approach is to convert binary tree into an array, where the nodes are placed next to each other in contiguous memory blocks. This is often referred to as the “flattened tree” implementation in literature.
An important aspect of the ad click-prediction dataset is that it heavily skews towards non-clicks causing the split points to partition the samples at each node into highly skewed sub-samples during the model training. In other words, branches that lead to non-clicks would be traversed more frequently than paths that lead to higher click probability which we use to our advantage at inference time.
Using XGBoost’s model has the cover statistic associated with each node, which is loosely correlated with the number of data points seen by the node, we can reorder the tree in such a way that the child with the larger instance weight (or cover) is placed next to the parent in memory.( i.e. child nodes that are more frequently visited are placed adjacent to the parent in the array). The other child is located ahead in the array, making the trees more cache efficient. One can think of performing a pre-order traversal of the binary tree, but instead of biasing towards the left child, we bias towards the child with a higher cover.
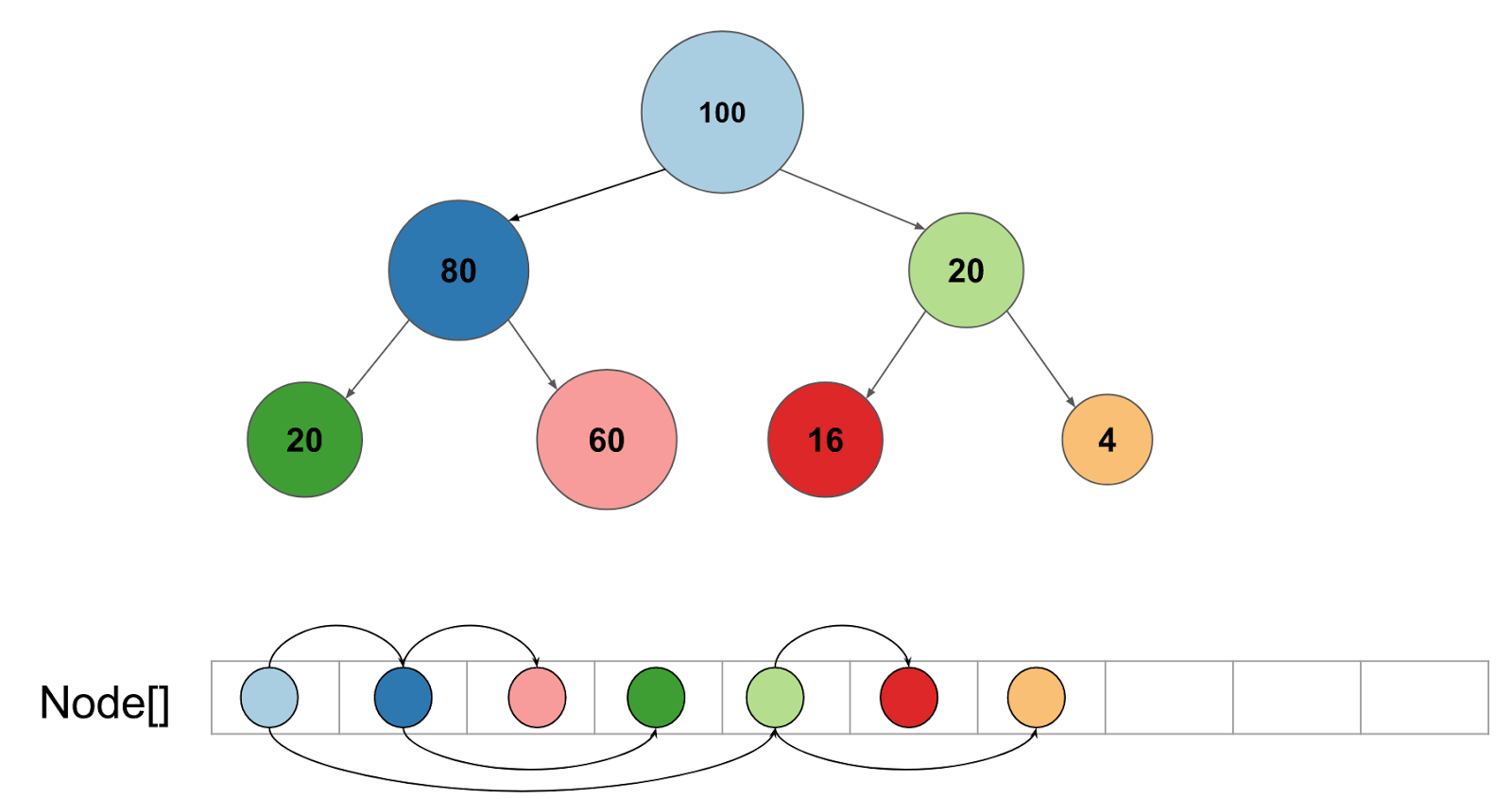
Figure 1. Each node is associated with a cover statistic that correlates with the number of instances at each node. Children with more instances are placed next to their parent in memory which makes the tree ordering cache friendly. The number in each node indicates the cover for that node.
There are also several optimizations that can reduce redundant data stored in the node to further increase cache locality. The attributes of a node can be represented by an integer array. In particular,
- It can be observed that the split condition at each non-leaf node and the weight at the leaf node are mutually exclusive attributes. Hence they can share the same 32-bit integer block. It’s worth mentioning that we store the IEEE 754 floating point representation of split condition and leaf weight using floatToIntBits.
- We always store one child node immediately adjacent to its parent node, so the parent only needs to store the address of the distant child. If that address is 0, we can implicitly infer that it is a leaf node.
- The feature index and default path flag (the path to take when the feature is missing from the feature vector) can share a single integer block.
We have compressed the contents of a node into an integer array of size 3 (12 bytes) rather than a basic implementation which would have taken 16 bytes just to store the left and right child pointers. Thus, if we traversed through the cache “hot” path we should get the children in the same cache line thereby making model inference faster.

Figure 2. Each node is represented as a block of 3 ints, which makes the decision trees both memory and cache efficient. If the feature value is missing, we use 1-bit to indicate which child to traverse (0 for adjacent, 1 for distant). Likewise we have 1-bit to decide which child to traverse when the split condition is true (0 for adjacent, 1 for distant)
To traverse the compressed array trees during inference time, we also use bit-wise operations and masks to make evaluation even faster.
- The limitations of this implementation include:
- The depth of the tree cannot exceed 31
- The number of features cannot exceed 231
- Samples in the offline dataset must skew towards one class, and the same distribution must hold online to take advantage of cache hot paths.
That said, it’s rare to train GBTs on more than 2 billion features or to build models with trees deeper than 31 levels so these limitations are not constraining in practice.
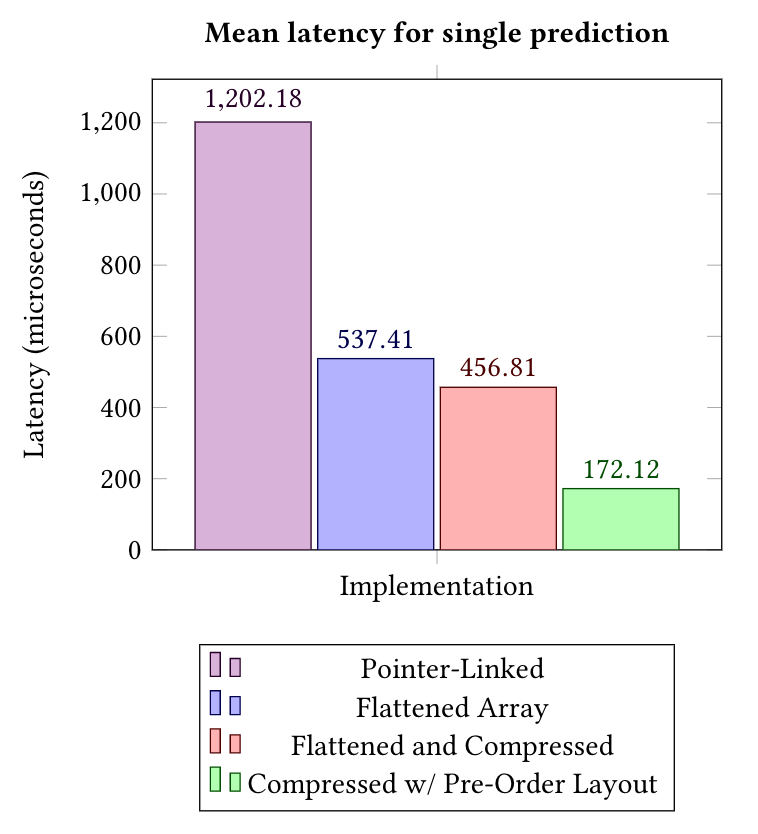
Figure 3. For the benchmark results, we measured prediction latency against a random sample of production data with and without our described optimizations. Our implementation using compressed nodes with a cover based pre-order layout offered a 3.1x speedup compared to a flat implementation and a 2.6x speedup compared to an implementation using a compressed representation alone.
This implementation gives us tremendous performance gains. We observed a phenomenal 120% improvement in our p50 latencies, exceeding the benchmarks on the xgboost-predictor library which we forked to implement the above model compression strategies.
We have open sourced the GBT prediction library for the benefit of the machine learning community. Check it out here.
If you are interested in building state of the art machine learning systems at Yelp check out our careers page!
Acknowledgements
This project had a number of key contributors we would like to acknowledge for their design, implementation, and rollout ideas: Ryan Drebin, Niloy Gupta, Adam Johnston, Eric Liu, Joseph Malicki and Hossein Rahimi.
References
- The Performance of Decision Tree Evaluation Strategies
- Evaluating boosted decision trees for billions of users
- Optimal Hierarchical Layouts for Cache-Oblivious Search Trees
- Fast Machine Learning Predictions
Build Machine Learning Systems at Yelp
Want to build state of the art machine learning systems at Yelp? Apply to become a Machine Learning Engineer today.
View Job