Yelp's Secret Detector: Preventing Secrets in Source Code

-
Aaron Loo, Engineering Manager
- Jun 11, 2018
We are always looking for new ways to bolster our security posture to keep our users and businesses safe.
Today, we’re happy to announce that we will be open-sourcing our detect-secrets framework to prevent secrets from being committed to our codebase. This aligns well with our value to always Protect the Source and adds to our growing collection of secure-by-default frameworks which bolster web security without compromising employee productivity.
The Problem
Secrets in source code are points of weakness in an otherwise secure system because they are available to any and all repository contributors, cloned, copied and distributed. And each one of those copies provides authorized access into your system. Can you imagine if your keys to the kingdom are one data leak or one mis-configuration away?
It’s easy to chalk this up to “better developer education”, but here at Yelp, we know that accidents happen. The question is how can we put safeguards in place so that:
-
It’s harder to accidentally commit a secret, and
-
If something does happen, we become be quickly aware of it, and can patch it before it is exploited.
Build vs Buy
This is not a new problem and we hate to reinvent the wheel so we spent time researching what solutions were already available. In our investigations of existing related work (truffleHog, git-rob, git-secrets, Repo Supervisor), we discovered they didn’t quite meet our needs. Specifically, we were looking for a solution that:
-
Supports a whitelisted baseline of secrets
We acknowledge that there may be existing secrets in our codebase or git history, however, we didn’t want this fact to block the deployment of this service. We would rather assert that all commits after a certain point of time are free from secrets. At a later time, we could review all secrets before this service was deployed, and retroactively roll and improve their storage.
-
Integrates with the Software Development Lifecycle (SDLC)
An optimal solution needs to work well with developers’ workflow because secret management is an ongoing process, rather than enforced through periodic audits. To enable this, we needed to make sure our solution was fast and didn’t scan files unnecessarily.
-
Is compatible with the pre-commit framework we use
We heavily leverage our pre-commit framework to run a suite of static code assertions before committing to the codebase. Therefore, an optimal solution would build off this framework, and maintain backwards compatibility with our existing hook installations.
-
Is lightweight and modular
We need a system that is easy to customize to our needs and fits within the larger ecosystem.
-
Is language agnostic
The solution should perform equally on all repositories, regardless of primary language, to support different clients (eg. python, puppet, javascript, php, java, etc.)
With these requirements in mind, we set out to build our own secret detection and prevention engine.
The Solution
Our solution leverages a client-side preventative method and a server-side detection method to make sure no secrets are accidentally shared. Both methods run through the same secret detection engine so that updates to the engine would conveniently affect both methods.
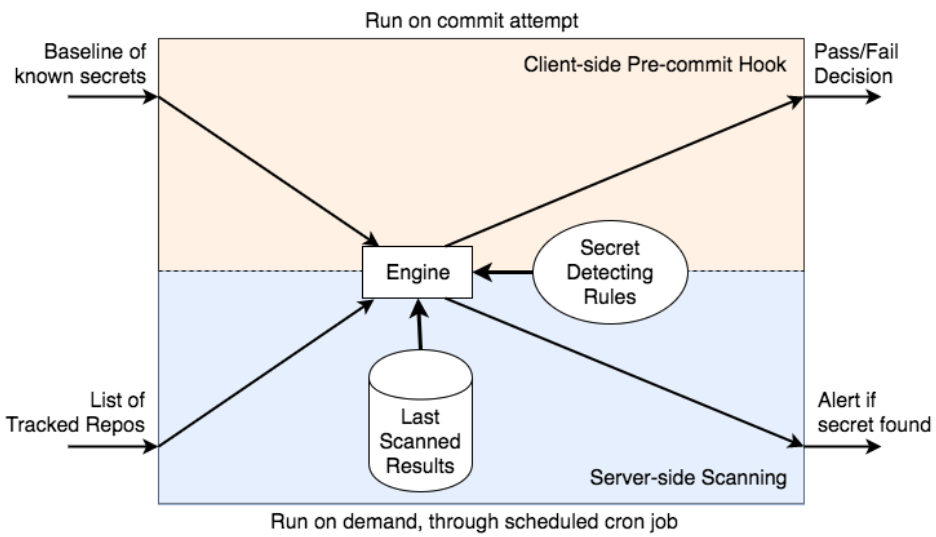
To prevent committed secrets, we leverage our existing pre-commit framework to scan through the commit diff for any “secret looking” strings (determined by the engine’s rules). For users who may not have the pre-commit hook installed, this also integrates into our continuous integration (CI) pipeline as a precautionary measure.
What about those secrets outside the CI pipeline, and in projects that don’t have the pre-commit hook installed? For these cases, we use the same engine to detect committed secrets by periodically scanning tracked code bases for updates, and secrets within those diffs. Through string analysis (rather than examining the Abstract Syntax Tree), we’re able to have a faster, more flexible solution while also being language agnostic. This ultimately allows us to scan all repositories frequently, increasing our response time without using much computing power.
How We Identify “Secrets”
We use regex rules to scan, and help identify the following types of secrets:
- API Keys
- AWS Keys
- OAuth Client Secrets
- SSH Private Keys
…and other high entropy strings, calculated using Shannon Entropy.
Naturally, this may cause false negatives with inherently bad passwords, as Shannon Entropy assumes that there is a component of randomness to the secrets detected. However, with proper employee education, the prevalence of these scenarios will be reduced.
Takeaways
It should be noted that this is not a fix-all solution. This is a heuristical attempt at enforcing stronger security practices.
However, paired with good employee education, this framework equips a growing company with tools to more easily enforce better secret management practices. We are excited to share this with the wider community, so that we can collectively make our systems a little safer.