Discovering Popular Dishes with Deep Learning

-
Anna F. and Parthasarathy Gopavarapu, Machine Learning Engineers
- Oct 8, 2019
Introduction
Yelp is home to nearly 200 million user-submitted reviews and even more photos. This data is rich with information about businesses and user opinions. Through the application of cutting-edge machine learning techniques, we’re able to extract and share insights from this data. In particular, the Popular Dishes feature leverages Yelp’s deep data to take the guesswork out of what to order. For more details on the product itself, check out our product launch blog post.
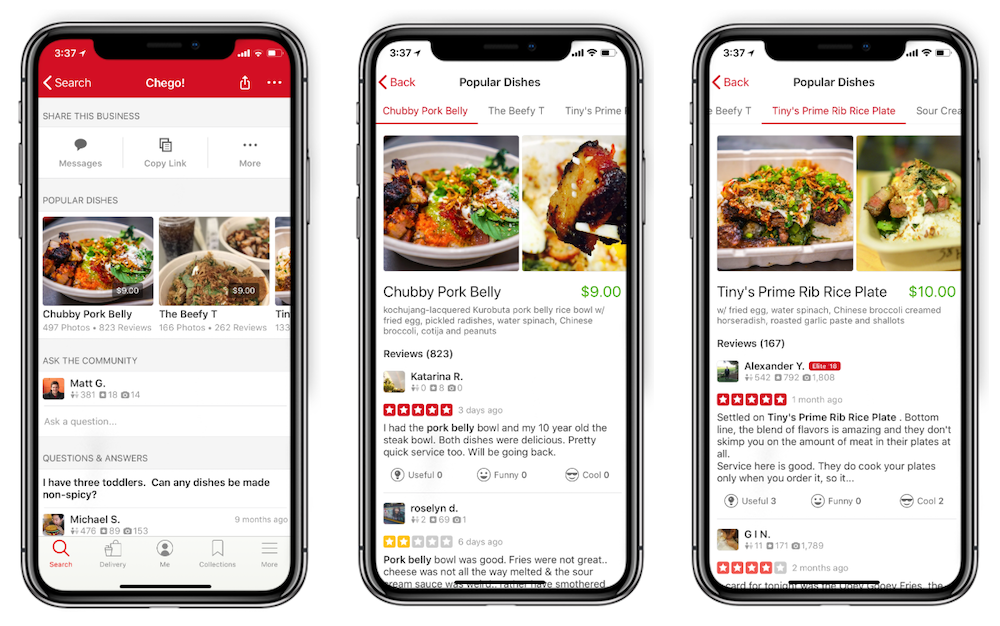
The Popular Dishes feature highlights the most talked about and photographed dishes at a restaurant, gathering user opinions and images in one convenient place. In this post we’ll explain how we used machine learning to make this possible.
Problem Definition
Given everything we know about a business, the data for the Popular Dishes feature boils down to the following output:
- A ranked list of popular menu items
- Reviews mentioning each item
- Photos associated with each item
Sometimes Yelp already knows a business’s menu. It may have been uploaded by the business itself or provided by partners. In such cases, the problem is simple: match items from the menu to reviews and photo captions and rank by the number of matches. This matching can be as simple as Python’s string.find method, or can incorporate fuzzy matching and more complex NLP techniques.
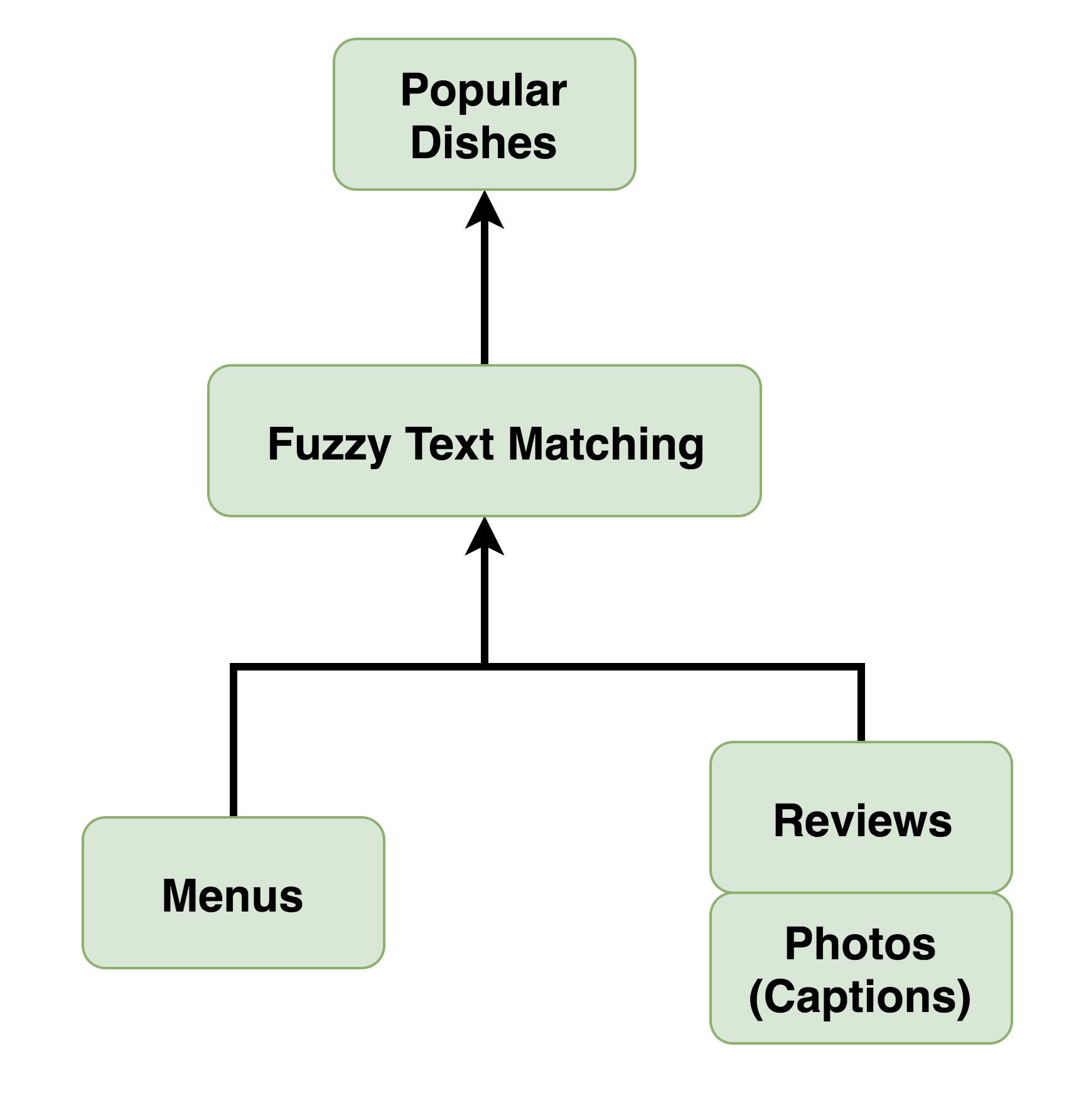
The basic pipeline
However, there are many businesses without menus. In order to provide a better and more consistent experience to users, we wanted to be able to display Popular Dishes even at businesses whose menus we didn’t have. So, we used machine learning to predict them.
The Inferred Menu Model
We wanted to use the vast review content from Yelp’s businesses to create menus we didn’t have. Since going straight from a list of reviews to a menu is hard, we split this into two steps: information extraction and aggregation. First, we extracted all mentions of potential menu items from a business’s reviews, and second, we aggregated these mentions to obtain an Inferred Menu for the business.
Machine Learning Problem
Recognizing menu items in unstructured text is very similar to the Named Entity Recognition (NER) process. NER is usually solved by classifying each token in the text by whether or not it belongs to a named entity. In our case, we classified each token in a review by whether or not it belonged to a menu item.
For this, we used the BIESO labelling scheme (introduced as BILOU in Ratinov & Roth 2009), where:
- All irrelevant (i.e., not part of a menu-item) tokens received the label ‘O’ (Outside)
- All single-word menu items received the label ‘S’ (Single)
- All multi-word menu items started with the label ‘B’ (Begin) and ended with the label ‘E’ (End), and any tokens in between got the label ‘I’ (Inside)

Example formatted review (with legend)
Once we classified each token as one of these five classes, we could extract menu items by gathering token spans with the following labels:
- S (Single token items)
- BI*E (Regular expression for multi token items)
Data
To train such a sequence classification model, we needed a dataset of reviews where each token in each review was tagged with one of the five classes (BIESO). Manually labelling reviews for this task would’ve been quite costly since training text models requires a significant amount of data.
To solve this problem, we took advantage of the menu data that Yelp already has. Since an ideal Inferred Menu for a business would be similar to its Yelp menu (when available), we inverted the problem to create our “Gold Data.”
We performed a variant of fuzzy matching to tag the reviews of businesses where we already had a menu (provided by partners/business owners) to create our Gold Dataset.
| Menu | Tagged Reviews |
|---|---|
|
The Chicken Burrito The Vegetarian Burrito Nachos |
|
Matching Heuristics
While generating our training data, we applied some heuristics to account for the variety of ways reviewers talk about menu items. For example, a business that offers a “tofu and vegetable momo” on its menu may have reviews that mention:
- Misspellings like “tofu and vegtable momo”
- Different inflections with the same lemmas, like “tofu and vegetables momo”
- Partial mentions like “tofu vegetable momo” or “tofu momo”
- Synonymous mentions like “tofu veggie momo”
The fuzzy matcher attempted to accommodate this diversity of speech.
Issues with the Gold Data
While the large number of reviews we have can provide a large enough dataset to train our model, the data does come with some caveats, even after using matching heuristics:
- Menus can be incomplete: This creates false negatives in the data when reviewers talk about an item that’s served at the restaurant but isn’t present on the menu.
- Users can be creative: As discussed above, reviewers can refer to the same item in different ways. This creates false negatives when the menu only has one representation of the item and users mention it in other ways.
- The leniency we introduce in matching heuristics can introduce false positives. For example, a mention of “New York” (the city) in a review can be tagged as a menu item since it’s close to “New York Cheesecake.”
These issues with the Gold Data can cause a few problems:
- Issues with training data can result in a sub-optimal model
- Issues with validation data can result in unreliable metrics
As a result, some post-processing was required; this is discussed later on in the Evaluation and Improvements section.
Model
We used a Hierarchical GRU model described in Yang et al.
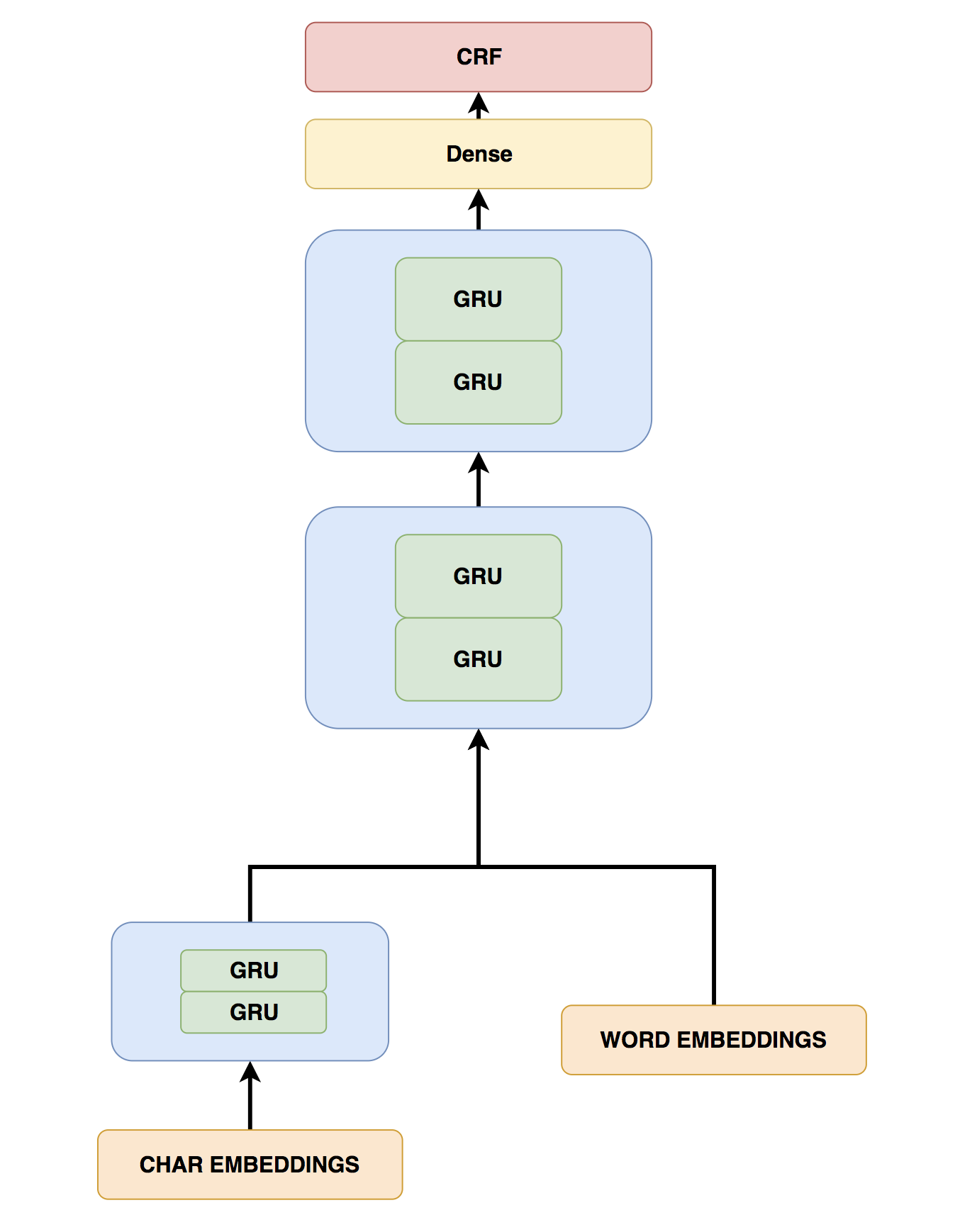
Model Components
Word Representation
We combined pre-trained word (trained on Yelp review data using gensim) and learned character embeddings to represent each word in the model.
The embeddings of each character in a word are passed through a bidirectional GRU to provide a learned character-based representation of the word. This representation is concatenated with pre-trained word embeddings to provide a single representation of each word in the review.
Multi Layer RNN
We used GRUs as our base RNN unit. The word representation from above (pre-trained word embeddings + learned character embeddings) is passed through two layers of bidirectional GRUs. Each bidirectional GRU has a forward and a backward GRU, which parses the tokens in the review in the forward and reverse order, respectively. The output of the forward and backward GRUs are concatenated to represent the output of the bidirectional GRU layer.
CRF Layer
One way to predict the class labels for each word in the review would be to use a dense (or linear classification) layer with softmax activation on top of the bidirectional GRU layers to predict one of the five classes.
This approach doesn’t account for dependencies between the labels assigned to a sequence of tokens. By the definition of BIESO tagging, there are some invalid sequences (e.g., OBSO, OBOEO, OIO, ...). If we use a dense layer that doesn’t have the context of class probabilities for other tokens in the review, we may end up predicting invalid sequences.
To avoid this, we used a Conditional Random Field (CRF) which can model dependencies between the labels assigned to each token in the review.
The output of this CRF layer is the final classification assigned to each token in the review.
Aggregation
The final step was to transform these classifications into an actual menu. We extracted all matching spans (BI*E and S) and counted their occurences. Based on language heuristics, some mentions were collapsed into each other. For example, mentions of “mac and cheese” were combined with those of “macaroni & cheese.” The final result was an Inferred Menu: a list of items that we’re confident appear on the menu.
Evaluation and Improvements
Motivation
Now that we had an Inferred Menu, we were able to plug it back into the same matching pipeline that we used with regular menus.
|
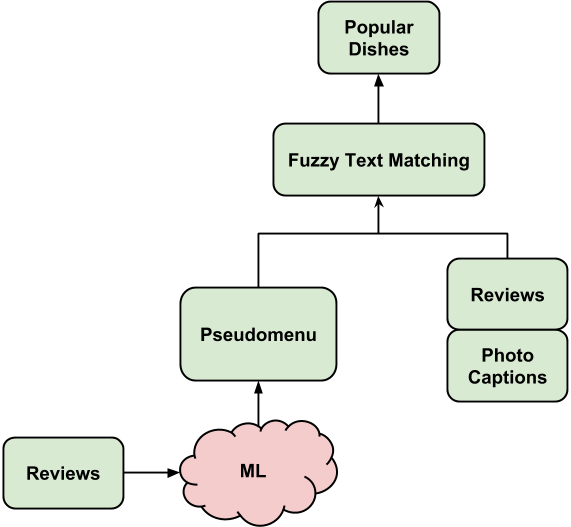 |
The pipeline for businesses with and without menus
Since ML is fuzzy and never perfect, we made sure to evaluate the performance of the model before shipping. We settled on a few evaluation criteria. Our focus was on achieving a high precision, as mistakes would look bad and hurt user trust. There are several questions we wanted to answer about our “Popular Dishes” before showing them to users:
- Are they actually dishes?
- Are they popular?
- Are we finding all their matches in photos and reviews? Are we matching anything we shouldn’t be?
For a textbook machine learning task, you assemble a set of labelled data for training and testing. The output of your model is compared with this golden data, and you can calculate metrics like precision, recall, and accuracy. Under this paradigm, we’d manually find the Popular Dishes and their mentions at a restaurant, then compare this gold data with the output of our models. However, collecting this data would’ve been prohibitively expensive, and potentially impossible given the domain knowledge required. Hiring a human to read a business’s reviews, come up with a menu, and find these matches was impractical.
Approach
Thankfully, our focus was on precision, which was much easier to calculate. Given a “Popular Dish” or a mention, it’s fairly simple to decide whether it’s good or not. As a result, we turned to human-in-the-loop machine learning to both evaluate and improve our model. Our process is summarized in this flowchart:
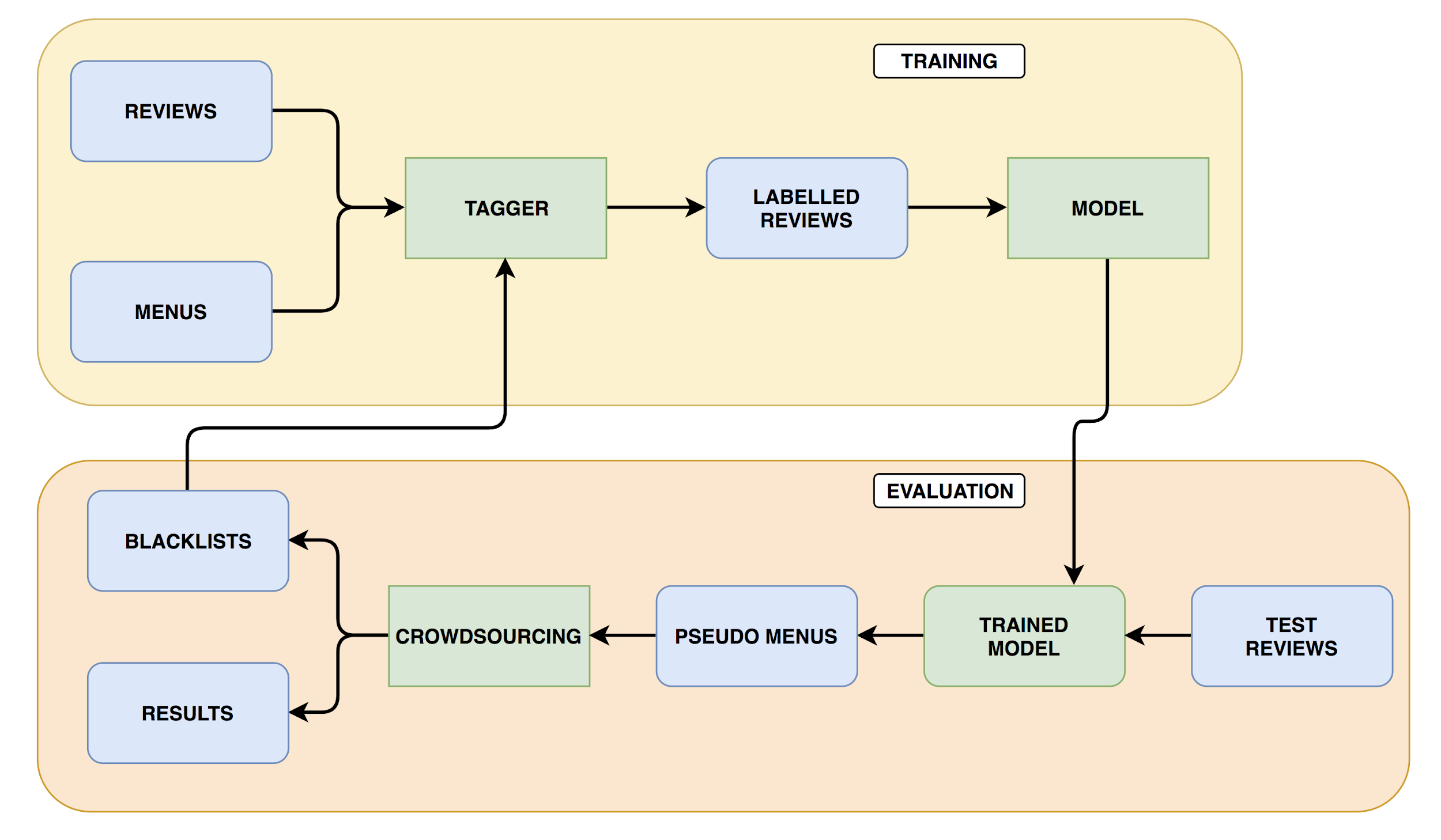
First, we generated Popular Dishes using the model. Then, we asked taskers from an online tasking service to answer the following questions about each item:

Next, we calculated precision metrics from the results of this task. If they were good enough, we declared the task done. If not, we incorporated data from these gold labels into improving the model. For example, examining false positives revealed problems with our matcher. We were also able to extract blacklists of common non-main-dish items by combining tasker judgements. The blacklists were incorporated into training data generation for the Inferred Menu model and used to post-process its predictions.
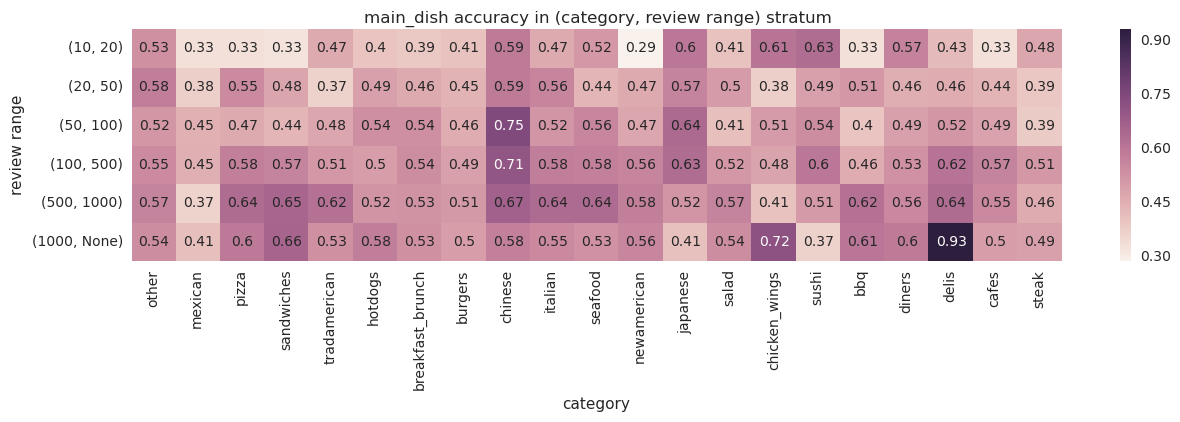
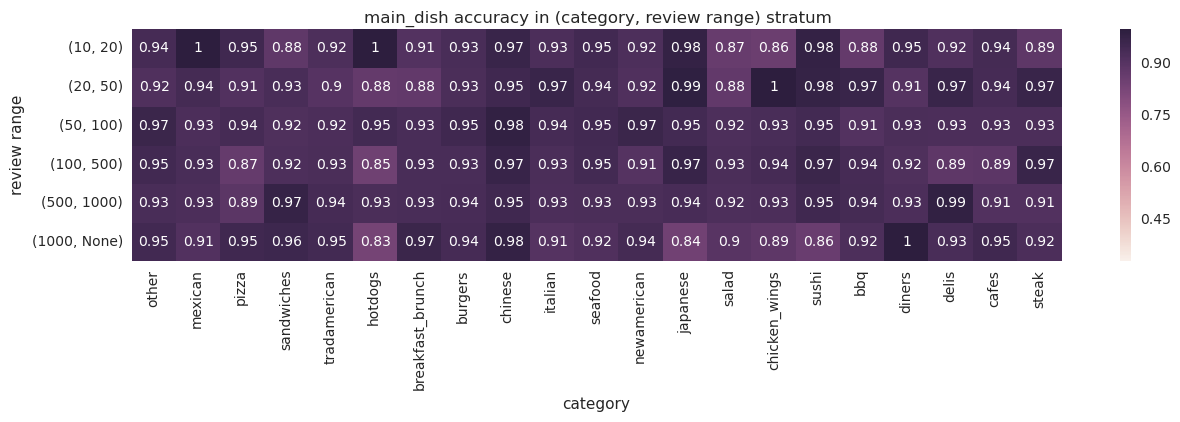
Through repeated iterations of evaluation and improvement, we significantly increased the model’s precision. The heatmap below displays our average precision for sample businesses in different (business review count, business category) strata before and after iteration. During the entire process, we kept an eye on coverage as a proxy for recall.
Deployment
The Popular Dishes backend is currently deployed as a handful of PySpark batches. Every day, all the data we have about our businesses is gathered and run through an NLP pipeline powered by the open source spaCy package. In this way, new mentions of dishes quickly become available for users to browse. Inferred Menus are regenerated periodically to pick up new dishes.
Become a Machine Learning Engineer at Yelp
Want to build state of the art machine learning systems at Yelp? Apply to become a Machine Learning Engineer today.
View Job