Automated IDOR Discovery through Stateful Swagger Fuzzing

-
Aaron Loo, Engineering Manager
- Jan 16, 2020
Scaling security coverage in a growing company is hard. The only way to do this effectively is to empower front-line developers to be able to easily discover, triage, and fix vulnerabilities before they make it to production servers.
Today, we’re excited to announce that we’ll be open-sourcing fuzz-lightyear: a testing framework we’ve developed to identify Insecure Direct Object Reference (IDOR) vulnerabilities through stateful Swagger fuzzing, tailored to support an enterprise, microservice architecture. This integrates with our Continuous Integration (CI) pipeline to provide consistent, automatic test coverage as web applications evolve.
The Problem
As a class of vulnerabilities, IDOR is arguably one of the most difficult to systematically defend against in an enterprise codebase. Its ease of exploitation, combined with its potential for impact, makes it a high-risk vulnerability that we want to minimize as much as possible.
In the security industry, there are two main approaches to defending against threats. First, try to prevent them from happening. If this isn’t possible, make sure you can detect them for fast remediation.
The problem with IDOR is that it’s difficult to do either one.
Hard to Prevent
The main problem with preventing IDOR vulnerabilities is that there’s no system that can be easily implemented to mitigate it. For Cross Site Scripting (XSS), attacks, you can leverage an effective templating system. For SQL Injection attacks, you can use parameterized queries. For IDOR, a common industry recommendation is to leverage a mapping (e.g., random string) to make it harder to enumerate values as an attacker. However, practically speaking, this is not as easy as it seems.
Maintaining a mapping leads to two categories of caveats:
-
Cache Management
Let’s assume you have an endpoint that’s currently vulnerable to IDOR attacks:
/resource/1. Now, you want to implement a mapping that masks this ID in the URL with a random string:/resource/abcdef, whereabcdefmaps to 1.In this contrived example, you may be tempted to deprecate the old endpoint and just use the new one. However, this may break browser caches, user bookmarks, and pages indexed by search engines. Imagine taking an unexpected SEO hit when trying to roll out your IDOR-prevention system!
The alternative is that you can redirect traffic from the old endpoint to the new one, and let it bake in production for an extended period of time. However, for the time the redirect is in place, you would still be susceptible to IDOR vulnerabilities. Furthermore, this mapping is publicly harvestable during this period, so there’s a chance that someone may store and use it at a later time to perform the same attacks – just with less enumerable values.
-
Handling Internal References
ID references are littered throughout many different internal systems: various logs, Kafka messages, and database entries to name a few. When you transition from one reference method to another, how do you make sure that none of these systems break?
One good approach is to only use the mapped string for public-facing assets and its numeric counterpart for internal references. However, how do you enforce this to be true? There will always be more data ingresses, and the problem space might be reduced to a whack-a-mole approach of either translating it at the new data ingress or handling both types of IDs downstream.
Another common industry recommendation is to merely perform access control checks before manipulating resources. While this is easier to do, it’s more suitable for spot-fixing, as it’s a painfully manual process to enforce via code audits. Furthermore, it requires all developers to know when and where to implement these access control checks. For example, if you put it at the ORM level, you may need to consider legitimate administrative cases for when you need to “bypass” these checks. If you put it at your view layer (assuming MVC layout), you may find yourself duplicating code everywhere.
How can you ensure all developers are actively thinking about this attack vector, and know how to mitigate it?
Slow to Detect
Detection strategies for this class of vulnerabilities are also somewhat lackluster. While manual code audits are effective, they don’t scale and are often expensive. Off-the-shelf static code analyzers prove more noisy than they’re worth, and a complicated taint analysis model would be required due to the various number of places that access control checks can be done.
Traditional API fuzzing may seem like another valid option, but this is not the case. The issue with traditional fuzzing is that it seeks to break an application with the assumption that failures allude to vulnerabilities. However, this is not necessarily true. As a security team, we care less about errors that attackers may or may not receive. Rather, we want to identify when a malicious action succeeds, which will be completely ignored by traditional fuzzing.
The Solution
In February 2019, Microsoft released a research paper that describes how stateful Swagger fuzzing was able to detect common vulnerabilities in REST APIs, including IDOR vulnerabilities. The premise of this strategy is as follows:
-
Have a user session execute a sequence of requests.
-
For the same sequence of requests, have an attacker’s session execute them. This is to ensure that the user and the attacker are able to reach the same state.
-
For the last request in the sequence, have the attacker’s session execute the user’s request. If this is successful, a potential vulnerability is found.
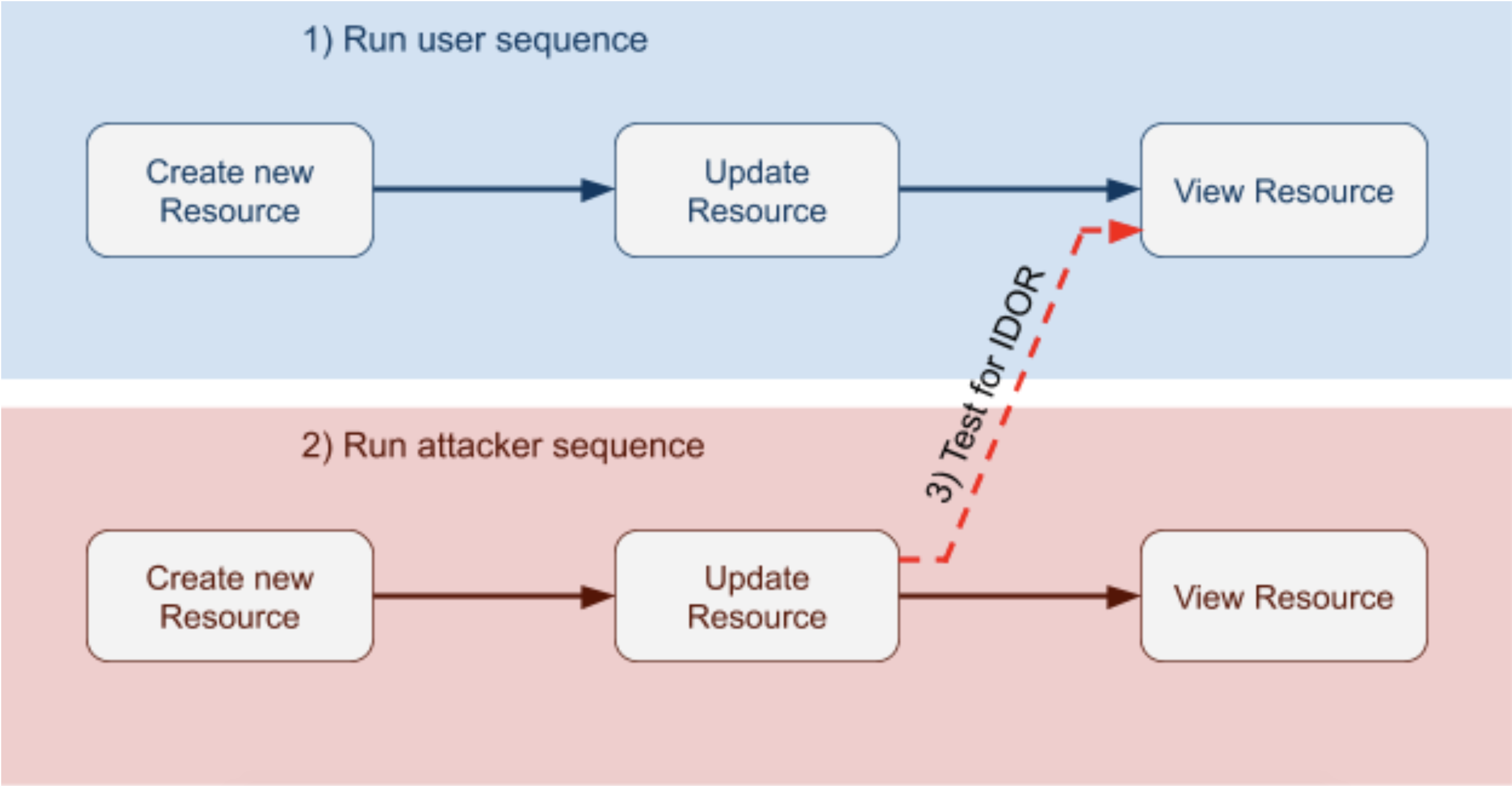
Detecting IDOR in a hypothetical sequence of requests
Stateful Fuzzing vs. Traditional Fuzzing
Generally speaking, the art of using fuzzing requests to find vulnerabilities relies on one core assumption: applications should be able to handle any input thrown at them. This means that when the application breaks due to “malformed” input, it’s indicative of a potential exploit and warrants further investigation.
The issue with this approach is that as a security team, we care less about whether an application breaks for a specific user and more about successful requests in situations where they should have failed.
Swagger, as a standardized API specification, is fantastic for programmatically defining the rules of engagement for the fuzzing engine. Furthermore, by making it stateful, we can simulate user behavior through proper API requests/responses which keep state between each response. This state can then be used to fuzz future request parameters so that a single request sequence is able to accurately simulate a user’s session, enabling chaos engineering testing.
Finally, user session testing allows for carefully crafted scenarios to assert various security properties of a given API. In this case, we leveraged this to check whether users are able to access private resources that don’t belong to them.
The simplicity of this concept was profound. It provided a means to scale IDOR detection in an automated fashion through integration with our CI pipeline. However, while our solution was inspired by Microsoft’s research, we encountered several issues when adapting it to our ecosystem.
Issues
Infrastructure Dependencies
With a microservice architecture, services often have dependencies on other services. This means that in order to fuzz a given service, we would need to spin up its dependent services along with any other nested dependent services. To address this, we leveraged Docker Compose to spin up a sandbox environment so we could perform acceptance testing with the service.
Acceptance testing is the practice of treating your service as a blackbox and testing whether the entire system as a whole behaves as expected. Through a microservice lens, this differs from integration tests (that mock out external dependencies), as acceptance tests spin up sandboxed instances for more realistic end-to-end testing. Since fuzz-lightyear identifies potential IDOR vulnerabilities by analyzing successful requests, it complements this framework nicely. Running tests in sandboxed instances also prevents leaving after-effects on staging or production databases so we don’t pollute our data with fuzzed, random input. Acceptance tests are typically integrated into CI/CD pipelines but can also be run locally by developers.
One popular tool we use at Yelp to facilitate running acceptance tests is Docker Compose. This allows developers to define service dependencies in one single YAML file and enables them to start/stop them easily. By leveraging this tooling, we gain two advantages. First, we empower developers by seamlessly integrating into their established development/testing workflow. Second, it integrates effortlessly with our existing CI pipeline to provide continuous coverage, and also tests for IDOR vulnerabilities in a generated sandboxed environment with all the new changes.
Incomplete Resource Lifecycle
A fundamental assumption in the original research paper is that the tested application supports all CRUD (Create, Retrieve, Update, Delete) methods. This allows for stateful fuzzing, as any resource can be created and manipulated within the application’s API.
However, this is not the case at Yelp. Often, services only provide interfaces to retrieve and update resources directly corresponding to that service, but rely on other services to create such resources. This means that stateful fuzzing would not be effective–since there’s no way to test the retrieval of a resource – if we didn’t create it within the request sequence.
For example, service A has an endpoint X which takes a business_id as an input,
but service A itself doesn’t have the ability to create businesses. By itself,
the stateful fuzzing algorithm would never be able to test endpoint X since we
have no way of generating a business!
We can’t just tack on another service’s API to the request sequence generation process, since this would expand the search space of the algorithm too much. Therefore, our solution is to provide developers the ability to define factory fixtures that can be used while fuzzing. This is what a fixture looks like:
This registers create_biz_user_id as a provider for the userID resource, so
that if fuzz_lightyear needs a userID resource in a request, it can use the
factory to generate it. This fixture system makes it easy for developers to
configure fuzz_lightyear to generate vulnerability-testing request sequences
by reducing the complexity of creating dependency resources.
Expected Direct Object Reference
Not all endpoints that allow a direct object reference need to be authenticated. They could simply be providing non-sensitive information about the object being queried. For example, consider our open-sourced Yelp Love app. This endpoint requires authentication, but the details which it returns are not sensitive in the context of the app. Thus, it doesn’t make any sense to check for IDOR vulnerabilities in this case.
To address this, we implemented an endpoint whitelisting system to configure
which endpoints should be excluded from a fuzz_lightyear scan. This allows
developers to configure the testing framework to only alert off high-signal
endpoints, therefore minimizing test flakiness.
Takeaways
Automated IDOR detection is a difficult task. Even with the Microsoft-inspired stateful fuzzing approach, there were still limitations to applying this concept in a microservice ecosystem. To address these issues, we designed a testing framework that allows developers to easily configure dynamic tests and integrate them smoothly into our CI pipeline. In doing so, we can achieve continuous, automated IDOR coverage, as well as empower developers to be able to address these issues independently.
Curious to check it out? View more details on fuzz-lightyear on our Github page.
Contributors
I would like to credit the following people (in alphabetical order) for their hard work in building this system and in continuing to bolster Yelp’s security.
Security Engineering at Yelp
Want to transform industry-leading ideas into actionable, scalable solutions to help keep the Yelps secure? Apply to join!
View Job