An Ever Evolving Company Requires an Ever Evolving Communication Plan

-
Kent Wills, Director of Engineering Effectiveness
- Mar 6, 2020
It’s 2014 and your teams are divided by platform, something like: Web, Mobile Web, Android, and iOS.
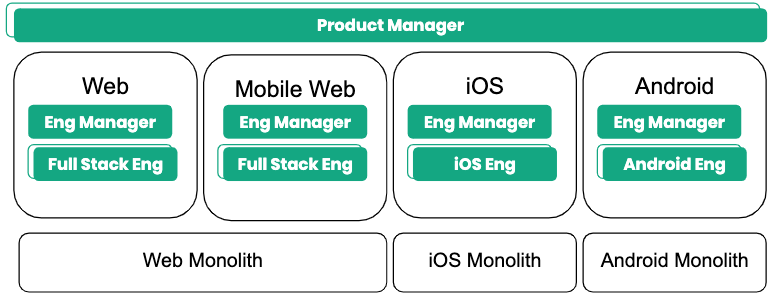
In order to launch features, product managers jump from platform to platform and teams move fast. Really fast. Lines of code in each repository increase to the point where you now name them “monoliths.” A few engineers maintain these monoliths when they need to, but no one is solely dedicated to the task. Engineers are distributed by platform; so communication on when to maintain the monoliths is easy, but presents another problem.
Can you continue to ship code efficiently if you depend entirely on these monoliths? It turns out that as you increase developers and the size of the code base, the number of rollbacks and unscheduled mobile point releases also increases. At first you notice only a few rollbacks, but as your team grows, you start to estimate when all pushes result in a rollback. This is not the typical “up and to the right graph” that companies look for.
Since rollbacks sound like a blocker, we’ve come up with an alternative: microservices. Then another: product teams.
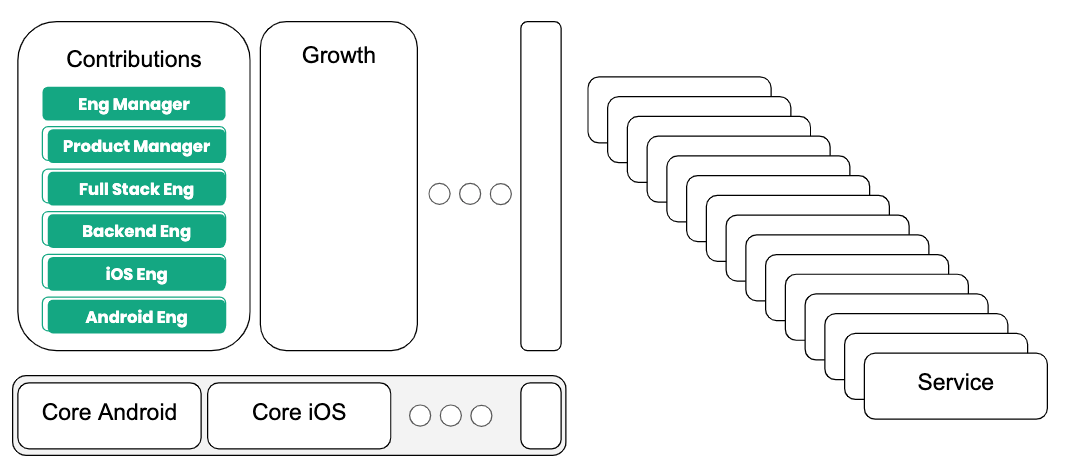
Now the company can scale both infrastructure and team organization. Product teams have a common set of infrastructure; the button used on the Growth team is the same button used on the Contributions team. Function-based (core) teams spin up. They work on the parts that individual maintainers worked on in the days of the monolith. They’re dedicated to making sure that, in the long term, we’re coding sustainably. Communication becomes harder. In fact, communication complexity continues to increase. Core teams used to do all the changes needed for maintenance/infrastructure upgrades, but the organization has gotten so large they need to rely on product teams to do the bulk of the work. Core teams generate a list of maintenance items that product teams need to work on, but product teams have to concentrate on adding new products.
How do we prioritize work? Before we prioritize work, we need to identify who’s responsible for what. To tackle this problem, Core teams create tooling. Ownership becomes more defined with added metadata to “entities,” an abstract term used to describe things like code and alerting. All this ownership becomes shareable via the ownership service, and, we can now track migrations across the engineering organization with a tool called “migration-status.” We start by defining migrations from a “core team” perspective, but also have migrations from other infrastructure teams. Now that product teams are multi-disciplinary, we start to bombard them with an increasing number of messages to upgrade/migrate their infrastructure. Communication complexity increases and efficiency decreases.
We start thinking of a way to tie together priorities from multiple teams. We need a solution that has a global view and seeks to control communication complexity. Just like how a notification platform for your users needs to figure out the right messages to send, we need a tool to surface the right reminders to the right teams. So, which messages are sent to which users?
Over the next few blog posts, we’ll walk you through what the Engineering Effectiveness Metrics (EE Metrics) Platform is and how we use it to reduce communication complexity. The first blog post will dive into our “Ownership” service. We’ll be talking about what it is, how we use it, and the value that it brings to our engineering organization. The second post will cover how we use the EE Metrics tool to increase awareness of developer velocity and code quality and to improve prioritization of critical migrations for product teams. We do all of these things while maintaining a safe space for teams and individuals.