Supporting Spark as a First-Class Citizen in Yelp’s Computing Platform

-
Jason Sleight, ML Platform Group Tech Lead; Huadong Liu, Software Engineer; and Stuart Elston, Software Engineer
- Mar 2, 2020
Yelp extensively utilizes distributed batch processing for a diverse set of problems and workflows. Some examples include:
- Computation over Yelp’s review corpus to identify restaurants that have great views
- Training ML models to predict personalized business collections for individual users
- Analytics to extract the most in-demand service offerings for Request a Quote projects
- On-demand workloads to investigate surges in bot traffic so we can quickly react to keep Yelp safe
Over the past two years, Yelp engineering has undertaken a series of projects to consolidate our batch processing technologies and standardize on Apache Spark. These projects aimed to simultaneously accelerate individual developer workflows by providing easier access to powerful APIs for distributed computing, while also making our systems more robust, performant, and cost efficient on a macro scale.
Background
Throughout Yelp’s history, our batch processing framework of choice was MapReduce, executed via Amazon Elastic MapReduce (AWS EMR). We even constructed our own open source framework, mrjob, which abstracts the details of the underlying MapReduce execution infrastructure away from developers. This way they could focus on the application-specific portions of their workflow instead, like defining their Map and Reduce steps. This framework has served us well over the years, and every day our production environment executes hundreds of mrjobs.
Over time though, Yelp developers were increasingly drawn towards Apache Spark. The foremost advantage of Spark is in-memory computing, but additional advantages include a more expressive API and large library of open source extensions for specialized workloads. This API flexibility makes it easier for developers to write their distributed processing workloads and results in higher-quality code that is both more performant and easier to maintain. However, without a well-supported backend, provisioning Spark resources was an intensive process that made deploying Spark jobs to production a challenge and all but eliminated Spark from contention for ad hoc workflows en masse.
Better support for Spark seemed like a promising direction, so our first step was to add Spark support into Yelp’s mrjob package (seen in mrjob v0.5.7). This enabled developers to write Spark code using the familiar mrjob framework and execute their Spark jobs on AWS EMR. Results from early adopters were encouraging, with one Yelp engineering team going so far as to convert over 30 of their legacy MapReduce mrjob batches into Spark mrjob batches, resulting in an aggregated 80% runtime speedup and 50% cost savings! Clearly, Spark was a direction that could add substantial value to Yelp’s distributed computing platform.
Running Spark mrjob batches on AWS EMR was viable for many production batch use cases, but also demonstrated a few problems. Firstly, it was painful to connect to the rest of Yelp’s infrastructure, and consequently workloads had to operate in isolation (e.g., they couldn’t make requests to other Yelp services). Secondly, it was painful to use for ad hoc workloads since it required launching an AWS EMR cluster on demand, which could take up to 30 minutes between provisioning and bootstrapping.
Integrating Spark as a first-class citizen in Yelp’s computing platform as a service, PaaSTA, enabled us to ease these pain points while also inheriting all of PaaSTA’s capabilities.
Spark on PaaSTA
PaaSTA is Yelp’s defacto platform for running services and containerized batches. At its core it’s (currently) built on Apache Mesos. Spark has native support for Mesos, but was a new framework for PaaSTA, which had previously only executed Marathon for long-running services, and Yelp’s in-house batch scheduling system, Tron, for containerized batches. To set up Spark as a framework in PaaSTA, we needed to select several configuration settings and design the interfaces Spark on PaaSTA would expose to Yelp developers.
We elected to run the Spark driver as a Mesos framework in a Docker container using the Spark client deploy mode. Since losing the driver is catastrophic for Spark clusters, we constrained Spark drivers to only run on a dedicated Auto Scaling Group of on-demand EC2 instances. On the other hand, Spark’s resilient data model provides automatic recovery from executor loss, allowing us to run Spark executors in Docker containers on a cluster of EC2 spot instances. For simplicity, we configured Spark on PaaSTA such that the Spark driver and executors used the same Docker image pulled from our internal Docker registries.
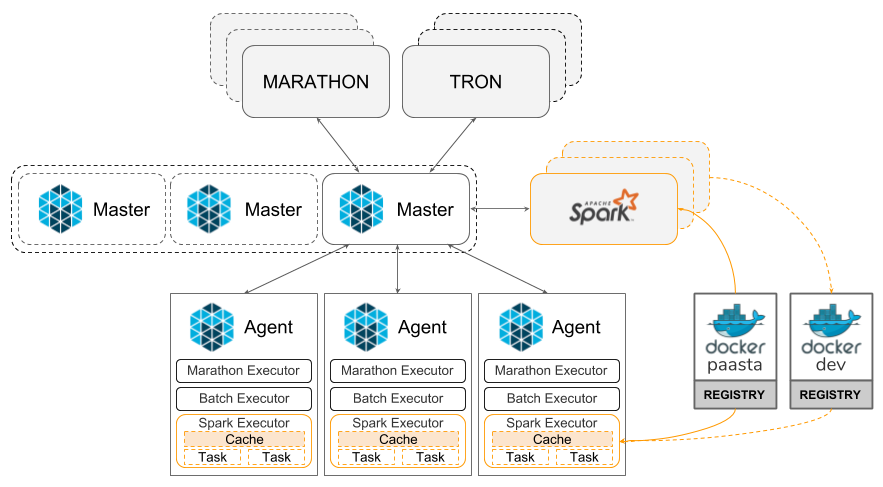
Yelp has two primary use cases for Spark: offline batches and ad hoc interactive computing. To serve these needs, we created two APIs for Spark on PaaSTA:
- A command line interface that developers use to schedule Spark batches. Behind the scenes, this interface injects the necessary Spark configuration constraints to connect to PaaSTA’s Mesos masters, provision executors on PaaSTA’s Mesos Agents, pull images from the appropriate Docker registry, and create a SparkSession object.
- A Python package that developers invoke from arbitrary Python code (e.g., Jupyter notebooks). Much like our command line interface, this package injects the necessary Spark configuration constraints and then returns the resulting SparkSession object.
Both of these APIs allow developers to have full control over how to configure their Spark cluster and can provide overrides for any of Spark’s configuration settings (e.g., executor memory, max cores, driver results size, etc.). PaaSTA will then use those values to provision and configure a Spark cluster as requested.
Beyond Spark configuration settings, Yelp developers also have the ability to specify the Docker image that Spark uses. This enables developers to easily include custom code (e.g., from their production service) in their Spark workflows. To reduce developer overhead, we’ve constructed an internal debian package that developers can install into their Docker image to automatically include many Spark extensions that are valuable for Yelp workflows, like hadoop-aws, spark-avro, etc.
Isolating Spark Jobs with a Dedicated Mesos Pool
Initially, we provisioned Spark frameworks on the same Mesos pools as Yelp’s other Mesos frameworks. However, we quickly recognized that Spark workloads have drastically different characteristics than the long-running Marathon services our Mesos pools were configured to support. Two differences in particular convinced us to create a dedicated Mesos pool for Spark jobs.
Firstly, Spark workflows are stateful. Yelp heavily uses AWS EC2 spot instances to drive cost savings for our computing platforms, which means an instance can be reclaimed by AWS at any time. Moreover, the PaaSTA cluster autoscaler dynamically scales the Mesos cluster to maintain a desired utilization, and can kill service instances on underutilized Mesos agents without warning. Since Yelp’s Marathon services are stateless and frequently have multiple concurrent instances, these abrupt disruptions are mostly inconsequential. While Spark can recover from losing an executor, losses can result in cached RDDs to be recomputed, thereby increasing load on upstream datastores and degrading developer experience. With a dedicated pool, we can use AWS instance types with lower reclamation rates, and a specially tailored Spark autoscaler (discussed in the next section) can minimize the probability of executor loss caused by PaaSTA.
Secondly, Spark workflows are more memory-intensive than service workloads. While one of Spark’s primary advantages over MapReduce is in-memory computing, that advantage is only realized if the Spark cluster has sufficient memory to hold the necessary data. At Yelp, it’s common for our developers to request terabytes of memory in aggregate for a single Spark cluster alongside several hundred CPUs. That memory-to-CPU ratio is substantially different from stateless Marathon services, which are typically CPU-bound with low memory footprints. With a dedicated pool, we’re able to populate Spark frameworks’ Mesos agents with AWS instances that have higher memory capacity and SSD drives in order to deliver a more cost effective system with higher resource utilization.
Autoscaling Spark
Yelp has been autoscaling our PaaSTA clusters for several years, reducing infrastructure costs by only running as many servers as necessary. We generally use a fairly standard reactive autoscaling algorithm which attempts to keep the most utilized resource (e.g., CPUs or memory) at a desired level (around 80%). For example, if 90 out of 100 CPUs in the cluster were in use, it would add another ~12 CPUs to the cluster to bring CPU utilization back to 80%. If, later on, only 80 of the now 112 CPUs are utilized, it will downscale the cluster back to 100 CPUs. This approach works well for most workloads we run at Yelp, the majority of which are long-running services whose load varies gradually throughout the day in proportion to web traffic.
Spark workloads, however, do not have gradually varying needs. Instead, the typical workload makes a large, sudden request for hundreds or thousands of CPUs, abruptly returning these resources a few hours (or even minutes) later when the workload completes. This causes sudden load spikes on the cluster, which is problematic for a reactive autoscaling approach for two reasons.
Firstly, a reactive autoscaling approach can only trigger scaling actions when the cluster is already over or under utilized. This is not problematic for gradually shifting workloads since the extra load usually fits into the cluster headroom (i.e., the 20% of CPUs the autoscaler keeps unallocated) while additional capacity is added. However, large Spark jobs can easily exceed the cluster headroom, preventing the workload and anything else on the cluster from obtaining additional resources until more machines are provisioned.
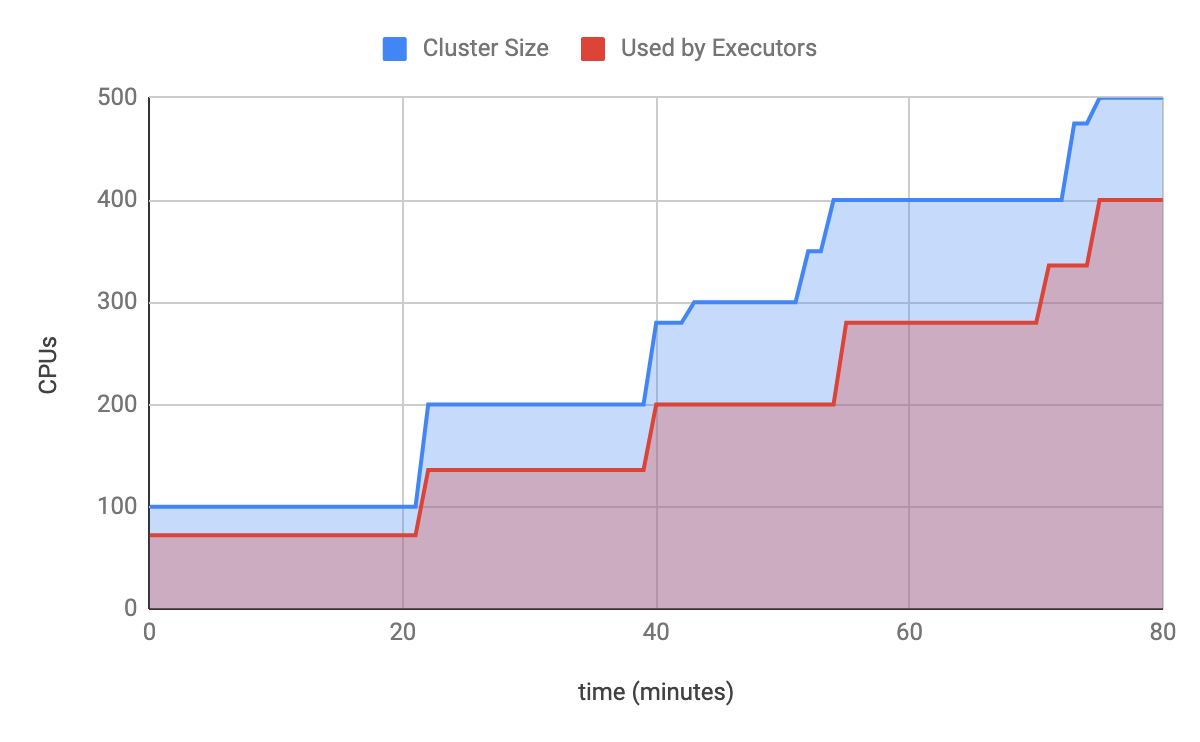
Secondly, relying on resource utilization obscures the true quantity of resources needed. If a cluster with 100 CPUs is at 100% utilization and our desired utilization is 80%, then the aforementioned reactive autoscaling strategy will provision 25 additional CPUs regardless of how many CPUs are needed. While it’s possible that 25 CPUs will be sufficient, if the Spark workload requested a thousand CPUs then it will take 11 autoscaling cycles (!) to reach the desired capacity, impeding workloads and causing developer frustration. By relying only on current utilization, we have no way to distinguish between these two cases. See below for an example in which it took our reactive algorithm four cycles and almost one and a half hours to scale the cluster from 100 to 500 CPUs for a Spark job.
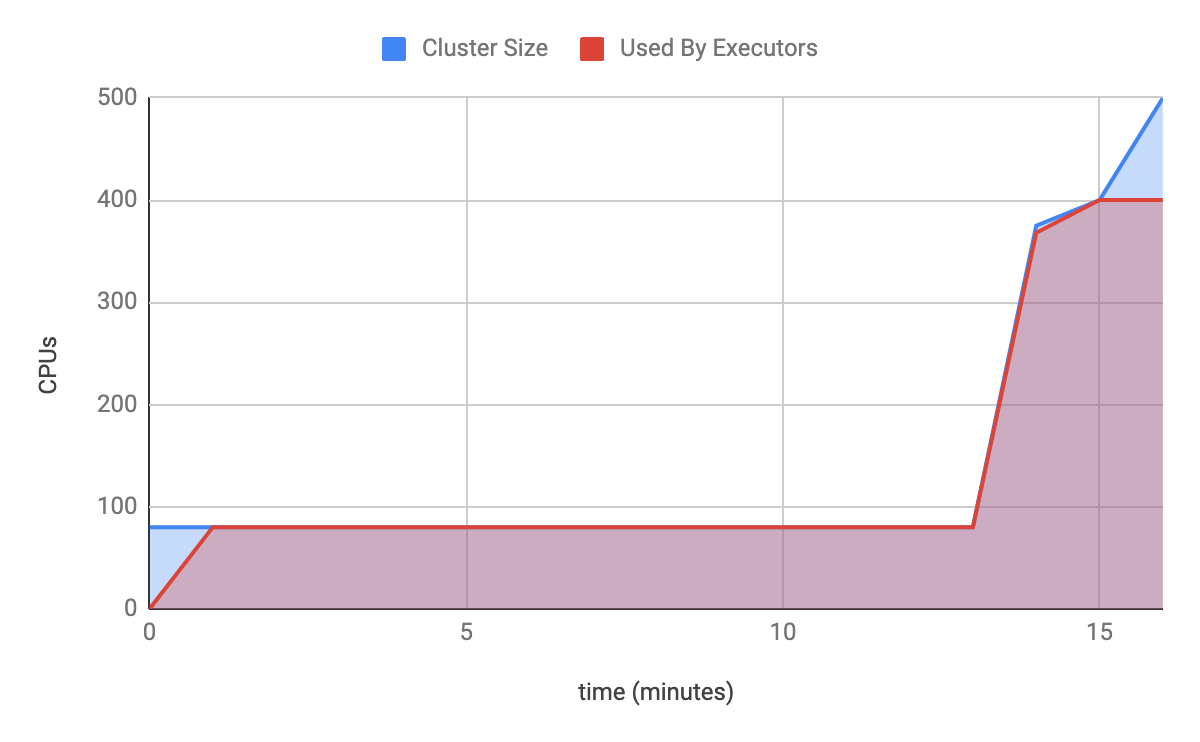
To solve these problems, we turned to Clusterman, our modular cluster autoscaler, which makes it simple to write custom autoscaling code for specific pools of machines. (You can check out our blogpost to learn more about it!) First, we extended the APIs that developers use to start Spark on PaaSTA jobs to send the Spark workflow’s resource needs to Clusterman. We then created a custom Clusterman signal for Spark that looks at these reported resource needs and compares them to the list of Spark frameworks currently registered with our Mesos clusters. If the framework associated with a given resource request is still running or we’re within a several minute grace period, that resource request is included in Clusterman’s allocation target. Because Clusterman knows the full resource requirements of each job as soon as it starts, we can make sure that Spark on PaaSTA jobs wait as little as possible for resources, regardless of quantity. The graph below shows our new approach performing the same task as the previous one in 15 minutes instead of one and a half hours!
Spark on PaaSTA Results
Over the past two years, we’ve seen accelerating adoption of Spark on PaaSTA among Yelp developers. Roughly 80% (and climbing) of all scheduled batches are now running Spark on PaaSTA instead of legacy mrjob on AWS EMR! In addition, Yelp developers create hundreds of Spark clusters every day for their ad hoc workloads.
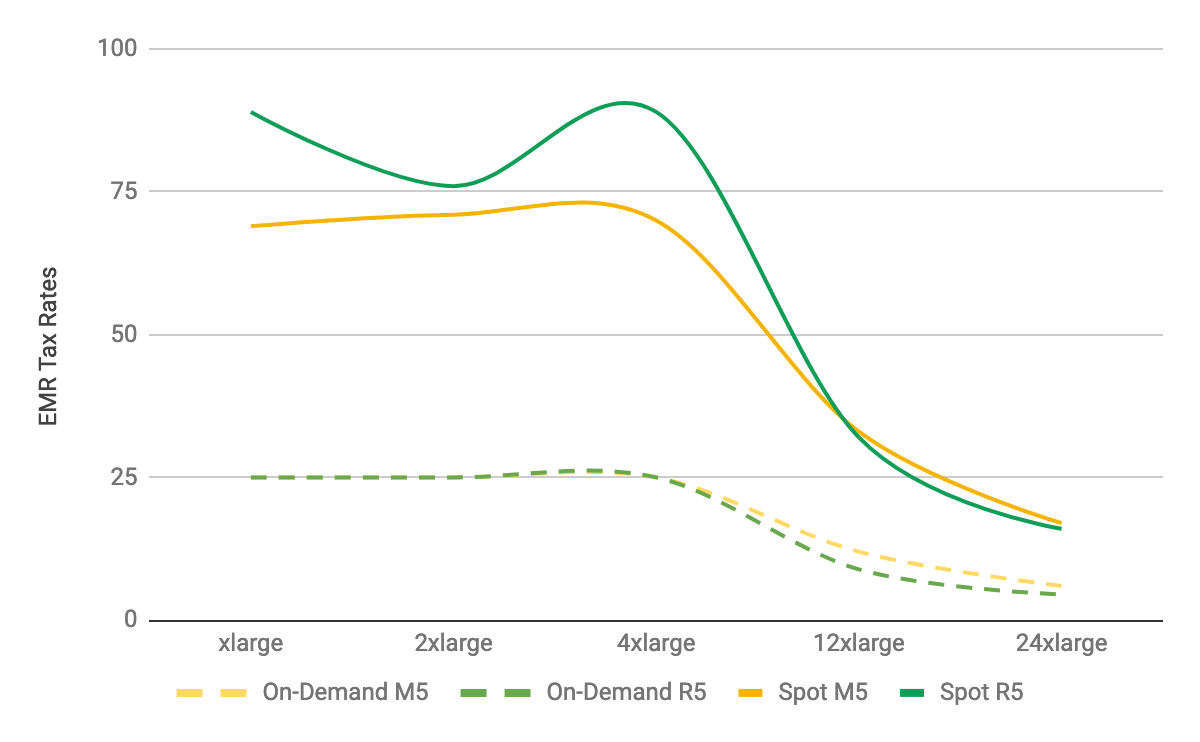
Aside from improving job performance and developer experience, moving to Spark on PaaSTA has also resulted in meaningful cost savings. As mentioned earlier, our legacy mrjob package runs on AWS EMR. Since EMR is a managed platform on top of EC2, AWS bills for EMR by taking the underlying EC2 cost and adding a premium. In essence, you can think of EMR as having a usage tax, with the EMR tax rate equal to the EMR premium divided by the EC2 cost. Figure 2 shows the EMR tax rate for different configurations of M5 and R5 instances. In many cases, the EMR tax is a substantial portion of overall EMR costs, and since Yelp uses spot instances heavily, our aggregate savings by moving Spark jobs from EMR to PaaSTA is over 30%.
Given the success of early Spark adoption, an organizational goal for Yelp in 2019 was to migrate all batch processing workloads to Spark on PaaSTA. As you might expect, migrating hundreds of legacy batches (many of which have been running without intervention for years) was a daunting endeavor. Rather than going through batches one by one, we instead migrated legacy MapReduce mrjobs en masse via a mrjob extension that wraps MapReduce code and executes it via Spark on PaaSTA. While rewriting MapReduce jobs to fully utilize Spark capabilities results in peak performance, we’ve observed significant wins just from running the existing Map and Reduce steps in Spark instead of MapReduce.
Conclusions
Looking back on our journey, adding Spark support to our computing platform has gone fairly smoothly. Nevertheless, there are still a few things we want to improve.
The first is system efficiency. By default, Mesos uses round robin task placement, which spreads the Spark executors to many Mesos agents and results in most agents containing executors for many Spark frameworks. This causes problems for cluster downsizing and can yield low cluster utilization. Instead, we would prefer to pack executors onto fewer Mesos Agents. We are currently experimenting with a patch to Spark’s Mesos scheduler that instead greedily packs executors onto hosts. We also plan to investigate Spark’s Dynamic Resource Allocation mode as a further improvement to cluster efficiency.
The second is stability. We’ve made a deliberate decision to run Spark on spot EC2 instances to benefit from their lower cost, but this choice also means that executor loss is possible. While Spark can recover from this, these events can lead to substantial recomputations that disrupt developer workflows—in worst cases getting stuck in a perpetual crash-recomputation loop that has to be manually terminated. These issues are magnified as the size of our Spark clusters continue to grow; and clusters with thousands of CPUs and TBs of memory are likely to experience at least one executor loss. Some solutions we plan to explore include aggressive checkpointing and/or selectively utilizing on-demand EC2 instances.
Finally, we’re in the process of converting our Spark deployment from Mesos to Kubernetes, with the primary advantage being that Kubernetes provides additional control layers for us to tune cluster stability, responsiveness, and efficiency. These changes are being made as part of PaaSTA itself, meaning that we can change the backend infrastructure without developers needing to alter their Spark usage!
We’re continuing to invest in Spark as a premier computing engine at Yelp, so stay tuned for further updates!
Acknowledgments
Special thanks to everyone on the Core ML and Compute Infrastructure teams for their tireless contributions to bring Spark to all of Yelp!
Become a Distributed Systems Engineer at Yelp
Interested in designing, building, and deploying core infrastructure systems? Apply to become a Distributed Systems Engineer today.
View Job