Introducing Yelp's Machine Learning Platform

-
Jason Sleight, ML Platform Group Tech Lead
- Jul 1, 2020
Understanding data is a vital part of Yelp’s success. To connect our consumers with great local businesses, we make millions of recommendations every day for a variety of tasks like:
- Finding you immediate quotes for a plumber to fix your leaky sink
- Helping you discover which restaurants are open for delivery right now
- Identifying the most popular dishes for you to try at those restaurants
- Inferring possible service offerings so business owners can confidently and accurately represent their business on Yelp
In the early days of Yelp circa 2004, engineers painstakingly designed heuristic rules to power recommendations like these, but turned to machine learning (ML) techniques as the product matured and our consumer base grew. Today there are hundreds of ML models powering Yelp in various forms, and ML adoption continues to accelerate.
As our ML adoption has grown, our ML infrastructure has grown with it. Today, we’re announcing our ML Platform, a robust, full feature collection of systems for training and serving ML models built upon open source software. In this initial blog post, we will be focusing on the motivations and high level design. We have a series of blog posts lined up to discuss the technical details of each component in greater depth, so check back regularly!
Yelp’s ML Journey
Yelp’s first ML models were concentrated within a few teams, each of whom created custom training and serving infrastructure. These systems were tailored towards the challenges of their own domains, and cross pollination of ideas was infrequent. Owning an ML model was a heavy investment both in terms of modeling, as well as infrastructure maintenance.
Over several years, each system was gradually extended by its team’s engineers to address increasingly complex scope and tighter service level objectives (SLOs). The operational burden of maintaining these systems took a heavy toll, and drew ML engineers’ focus away from modeling iterations or product applications.
A few years ago, Yelp created a Core ML team to consolidate our ML infrastructure under centrally supported tooling and best practices. The benefits being:
- Centrally managed systems for ML workflows would enable ML developers to focus on the product and ML aspects of their project without getting bogged down by infrastructure.
- By staffing our Core ML team with infrastructure engineers, we could provide new cutting edge capabilities that ML engineers might lack expertise to create or maintain.
- By consolidating systems we could increase system efficiency to provide a more robust platform, with tighter SLOs and lower costs.
Consolidating systems for a topic as broad as ML is daunting, so we began by deconstructing ML systems into three main themes and developed solutions within each: interactive computing, data ETL, and model training/serving. The approach has worked well, and allowed teams to migrate portions of their workflows on to Core ML tooling while leaving other specialized aspects of their domain on legacy systems as needed.
In this blogpost, I’ll discuss how we architected our model training and serving systems into a single, unified model platform.
Yelp’s ML Platform Goals
At a high level, we have a few primary goals for our ML Platform:
- Opinionated APIs with pre-built implementations for the common cases.
- Correctness and robustness by default.
- Leverage open source software.
Opinionated APIs
Many of Yelp’s ML challenges fall into a limited set of common cases, and for these we want our ML Platform to enforce Yelp’s collective best practices. Considerations like meta data logging, model versioning, reproducibility, etc. are easy to overlook but invaluable for long term model maintenance. Instead of requiring developers to slog through all of these details, we want our ML Platform to abstract and apply best practices by default.
Beyond canonizing our ML workflows, opinionated APIs also enable us to streamline model deployment systems. By focusing developers into narrower approaches, we can support automated model serving systems that allow developers to productionize their model via a couple clicks on a web UI.
Correctness and robustness by default
One of the most common pain points of Yelp’s historical ML workflows was system verification. Ideally, the same exact code used to train a model should be used to make predictions with the model. Unfortunately, this is often easier said than done – especially in a diverse, large-scale, distributed production environment like Yelp’s. We usually train our models in Python but might deploy the models via Java, Scala, Python, inside databases, etc.
Even the tiniest inconsistencies can make huge differences for production models. E.g., we encountered an issue where 64-bit floats were unintentionally used by a XGBoost booster for predictions (XGBoost only uses 32-bit floats). The slight floating point differences when numerically encoding an important categorical variable resulted in the model giving approximately random predictions for 35% of instances!
Tolerating sparse vector representations, missing values, nulls, and NaNs also requires special consideration. Especially when different libraries and languages have differing expectations for client side pre-processing on these issues. E.g., some libraries treat zero as missing whereas others have a special designation. It is extremely complicated for developers to think through these implementation details let alone even recognize if a mistake has occurred.
When designing our ML Platform, we’ve adopted a test-driven development mindset. All of our code has a full suite of end-to-end integration tests, and we run actual Yelp production models and datasets through our tests to ensure the models give exactly the same results across our entire ecosystem. Beyond ensuring correctness, this also ensures our ML Platform is robust enough to handle messy production data.
Leverage Open Source Solutions
ML is currently experiencing a renaissance of open source technology. Libraries like Scikit-learn, XGBboost, Tensorflow, and Spark have existed for years and continue to provide the foundational ML capabilities. But newer additions like Kubeflow, MLeap, MLflow, TensorFlow Extended, etc. have reinvented what an ML system should entail and provide ML systems with much needed software engineering best practices.
For Yelp’s ML Platform, we recognized that any in-house solution we might construct would be quickly surpassed by the ever-increasing capabilities of these open source projects. Instead we selected the open source libraries best aligned with our needs and constructed thin wrappers around them to allow easier integrations with our legacy code. In cases where open source tools lack capabilities we need, we’re contributing solutions back upstream.
ML Platform Technological Overview
In future blog posts, we’ll be discussing these systems in greater detail, so check back soon. For now, I’ll just give a brief overview of the key tech choices and a model’s life cycle within these systems.
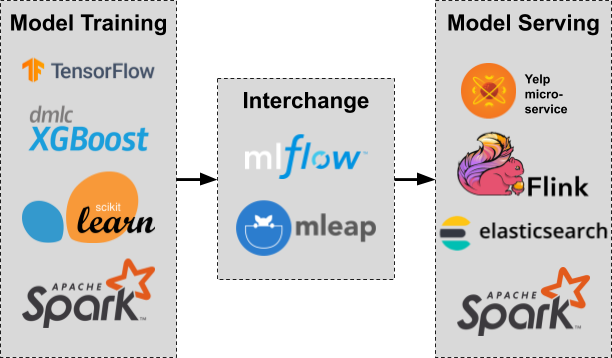
MLflow and MLeap
After evaluating a variety of options, we decided on MLflow and MLeap as the skeleton of our platform.
MLflow’s goal is to make managing ML lifecycles simpler, and contains various subcomponents each aimed at different aspects of ML workflows. For our ML Platform, we especially focused on the MLflow Tracking capabilities. We automatically log parameters and metrics to our tracking server, and then developers use MLflow’s web UI to inspect their models’ performance, compare different model versions, etc.
MLeap is a serialization format and execution engine, and provides two advantages for our ML Platform. Firstly, MLeap comes out of the box with support for Yelp’s most commonly used ML libraries: Spark, XGBoost, Scikit-learn, and Tensorflow – and additionally can be extended for custom transformers to support edge cases. Secondly, MLeap is fully portable, and can run inside any JVM-based system including Spark, Flink, ElasticSearch, or microservices. Taken together, MLeap provides a single solution for our model serving needs like robustness/correctness guarantees and push-button deployment.
Typical Code Flow in our ML Platform
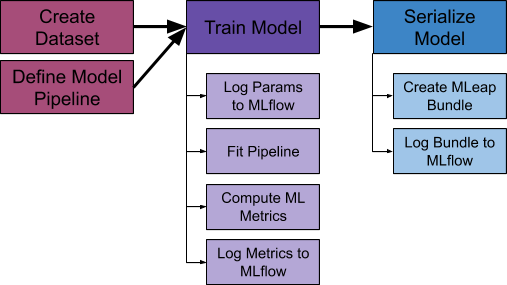
Offline Code Flow for Training a Model in our ML Platform
Developers begin by constructing a training dataset, and then define a pipeline for encoding and modeling their data. Since Yelp models typically utilize large datasets, Spark is our preferred computational engine. Developers specify a Spark ML Pipeline for preprocessing, encoding, modeling, and postprocessing their data. Developers then use our provided APIs to fit and serialize their pipeline. Behind the scenes, these functions automatically interact with the appropriate MLflow and MLeap APIs to log and bundle the pipeline and its metadata.
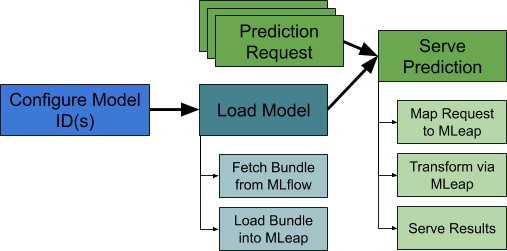
Online Code Flow for Serving a Model in our ML Platform
To serve models, we constructed a thin wrapper around MLeap that is responsible for fetching bundles from MLflow, loading the bundle into MLeap, and mapping requests into MLeap’s APIs. We created several deployment options for this wrapper, which allows developers to execute their model as a REST microservice, Flink stream processing application, or hosted directly inside Elasticsearch for ranking applications. In each deployment option, developers simply configure the MLflow id for the models they want to host, and then can start sending requests!
What’s Next?
We’ve been rolling out our ML Platform incrementally, and observing enthusiastic adoption by our ML practitioners. The ML Platform is full featured, but there are some improvements we have on our roadmap.
First up is expanding the set of pre-built models and transformers. Both MLflow and MLeap are general purpose and allow full customization, but doing so is sometimes an involved process. Rather than requiring developers to learn the internals of MLflow and MLeap, we’re planning to extend our pre-built implementations to cover more of Yelp’s specialized use cases.
We’d also like to integrate our model serving systems with Yelp’s A/B experimentation tools. Hosting multiple model versions on a single server is available now, but currently relies on clients to specify which version they want to use in each request. However, we could further abstract this detail and have the serving infrastructure connect directly to the experimentation cohorting logic.
Building on the above, we would like to have the actual observed events feed back into the system via Yelp’s real-time streaming infrastructure. By joining the observed events with the predicted events, we can monitor ML performance (for different experiment cohorts) in real-time. This enables several exciting properties like automated alerts for model degradation, real-time model selection via reinforcement learning techniques, etc.