Flink on PaaSTA: Yelp’s new stream processing platform runs on Kubernetes

-
Antonio Verardi, Engineering Manager
- Oct 14, 2020
At Yelp we process terabytes of streaming data a day using Apache Flink to power a wide range of applications: ETL pipelines, push notifications, bot filtering, sessionization and more. We run hundreds and hundreds of Flink jobs, so routine operations like deployments, restarts, and savepoints don’t take thousands of hours of developers’ time, which would be the case without the right degree of automation. The latest addition to our toolshed is a new stream processing platform built on top of PaaSTA, Yelp’s Platform As A Service. Sitting at its core, a Kubernetes operator automatically watches over the deployment and the lifecycle of our fleet of Flink clusters.

Flink on PaaSTA on Kubernetes
Life before Kubernetes
Before the introduction of Kubernetes at Yelp, Flink workloads at Yelp were running on dedicated AWS ElasticMapReduce clusters which come with both Flink and YARN pre-installed. In order to make EMR instances work well with the rest of the Yelp ecosystem, our previous stream processing platform Cascade used to run a chunk of Yelp’s Puppet monolith in a Docker container to apply configurations and to start the common set of daemons running on almost all Yelp’s hosts.
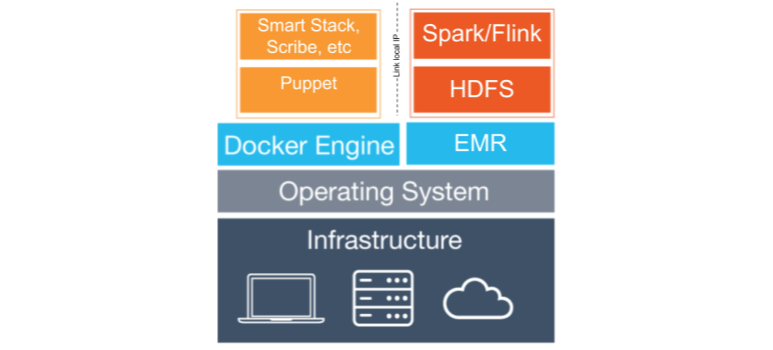
Architecture of Cascade
Cascade also introduced a per-cluster controller component in charge of the Flink jobs life cycle (starting, stopping, savepointing) and monitoring which we call Flink Supervisor.
While this system served us well for years, our developers were experiencing a handful of limitations:
- It previously took around 30 minutes to spin up a new Flink cluster
- We needed trained human operators to manually deploy new versions or scale up resources for each cluster
- We could not upgrade to newer versions of Flink until AWS supported them
- The complexity of running Puppet in Docker and of maintaining a very different infrastructure from the rest of Yelp was time consuming
When Kubernetes started to gain more and more momentum both outside and inside the company, we decided that it was time for a change.
Flink loves PaaSTA
PaaSTA is Yelp’s Platform As A Service and runs all Yelp’s web services and a few other stateless workloads like batch jobs. Originally developed on top of Apache Mesos, we are now migrating it to Kubernetes. This opened up the opportunity to support more complex workloads thanks to Kubernetes’ powerful primitives. Flink was the first in line and Cassandra is coming up in the very near future (be on the lookout for a new blog post!), both of them developed in tight collaboration with our Compute Infrastructure team.
Instead of “just” running Flink on top of Kubernetes using something off-the-shelf, we went down the road of developing a full-fledged platform that would make the experience of running Flink workloads as similar as possible to running any other service at Yelp. We did so to greatly reduce the knowledge necessary for a user to operate Flink clusters and to make our infrastructure very homogeneous with the rest of Yelp’s ecosystem.
With Flink on PaaSTA, provisioning a cluster is as easy as writing a YAML configuration file. New code deployments all happen automatically as soon as they are committed to git via Jenkins. The commands provided by PaaSTA for starting, stopping, reading logs or monitoring a web service work exactly the same for any Flink cluster.
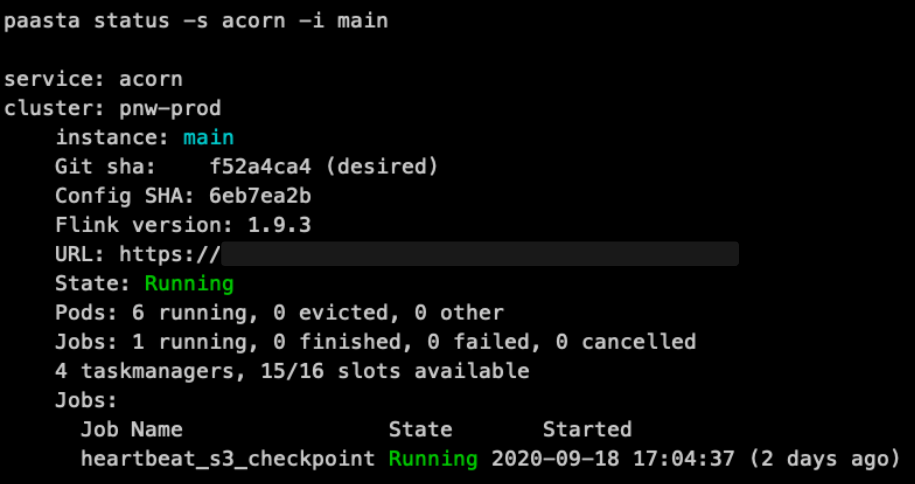
paasta status command output
In addition to UX improvements, we managed to reduce the average time to spin up a Flink cluster from 30 minutes to under 2 minutes and we are now free to hop on the latest version of Flink on our own schedule.
Peeking inside the hood
At the core of Flink on PaaSTA sits our custom Kubernetes operator, watching over the state of Flink clusters running on Kubernetes and making sure that they always match what is described in the configuration defined by the users.
Our PaaSTA glue translates this configuration into Kubernetes Custom Resources, which the operator reads and updates with information taken from the Flink clusters, like the jobs list and status. These resources are also used by the PaaSTA commands to fetch what to show to the users and to interact with the operator for operations like start and stop.
The operator knows how to map the high-level definition of a Flink cluster resource into the right Kubernetes primitives like Deployment for scheduling the TaskManagers, Service to make the JobManager discoverable by the other components in the cluster or Ingress to make the Flink web dashboard accessible by our users. The operator together with Jenkins schedules these components in Docker containers which allow us to customize the Flink installation and to select our Flink version of choice for each application.
You may find it surprising to see in the diagram below that our legacy Supervisor component still has a place in our new platform. At Yelp we like to approach all our projects with a practical spirit, infrastructure migrations included. While everything the Supervisor is doing could be worked into the operator, we decided to keep it around to reduce the development time by re-using existing features. Even more importantly, minimizing the scope of changes also helped to make the migration from Cascade to PaaSTA as easy as possible for our existing users.
For example, we deploy the Supervisor as a Kubernetes Job to leverage its logic for triggering savepoints of all the Flink jobs running on a cluster just before the operator shuts it down.
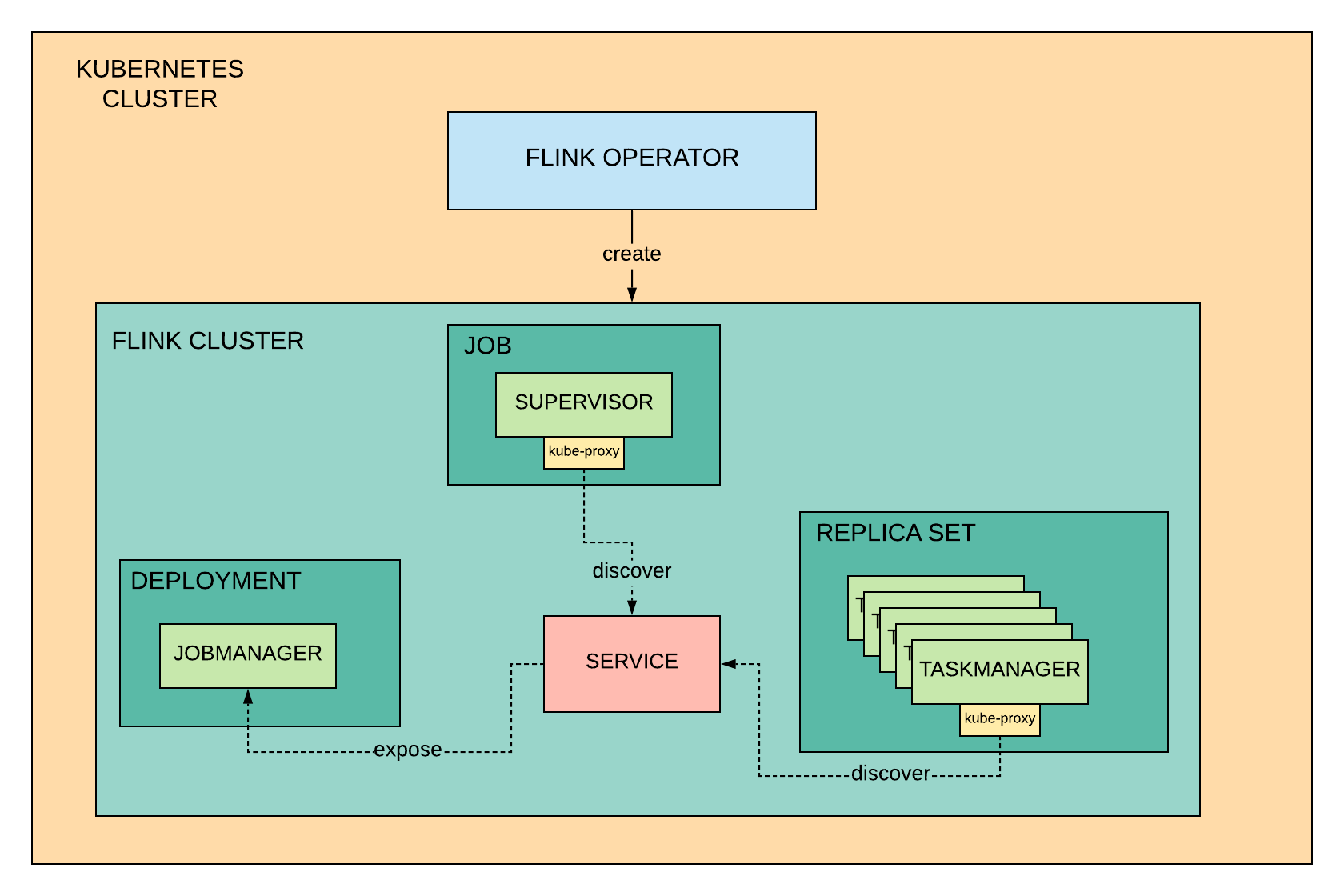
Components of a Flink PaaSTA cluster
If you’d love to hear more about the details, we encourage you to check out our talk at Flink Forward.
What now?
Freeing us from the need to manage hundreds of Flink clusters, Flink on PaaSTA unlocked a new world of possibilities for our users and our Stream Processing team.
On the infrastructure side, we are now close to adding Apache Beam support to Flink on PaaSTA in order to make Python stream processing a first-class citizen at Yelp. We are also working on implementing auto scaling and per-job cost reporting for Flink clusters.
On the UX side, we are developing tools to allow our users to define complex pipelines of streaming components with a single configuration file. We are also busy building features to shape our on-line machine learning platform.
Stay tuned if you want to hear about all the above and more!
Data Streams Platform Engineer at Yelp
Want to build next-generation streaming data infrastructure?
View Job