Improving the performance of the Prometheus JMX Exporter

-
Flavien Raynaud, Software Engineer
- Oct 2, 2020
At Yelp, usage of Prometheus, the open-source monitoring system and time series database, is blossoming. Yelp is initially focusing on onboarding infrastructure services to be monitored via Prometheus, one such service being Apache Kafka. This blogpost discusses some of the performance issues we initially encountered while monitoring Kafka with Prometheus, and how we solved them by contributing back to the Prometheus community.
Kafka at Yelp primer
Kafka is an integral part of Yelp’s infrastructure, clusters are varied in size and often contain several thousand topics. By default, Kafka exposes a lot of metrics that can be collected, most of which are crucial to understand the state of a cluster/broker during incidents, or gauge the overall health of a cluster/broker. By default, Kafka reports metrics as JMX (Java Management Extensions) MBeans.
Prometheus metrics primer
One of the ways to export metrics in Prometheus is via exporters. Exporters expose metrics from services in a format that Prometheus understands. Prometheus shards are then able to collect metrics exposed by these exporters.
The Prometheus community officially maintains the JMX Exporter, an exporter that can be configured to expose JMX MBeans from virtually any JVM-based process as Prometheus metrics. As mentioned above, Kafka is one such process.
In order to make Kafka metrics available in Prometheus, we decided to deploy the JMX Exporter alongside Kafka.
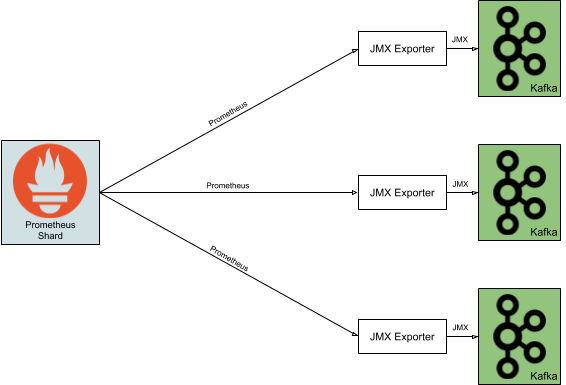
Figure: Architecture of Prometheus metric collection for a 3-broker Kafka cluster
When we initially deployed the JMX Exporter to some of the clusters, we noticed collection time could be as high as 70 seconds (from a broker’s perspective). We tried running the exporter as a Java agent and tweaking the configuration to collect only metrics that were interesting to us, but this did not improve the speed.
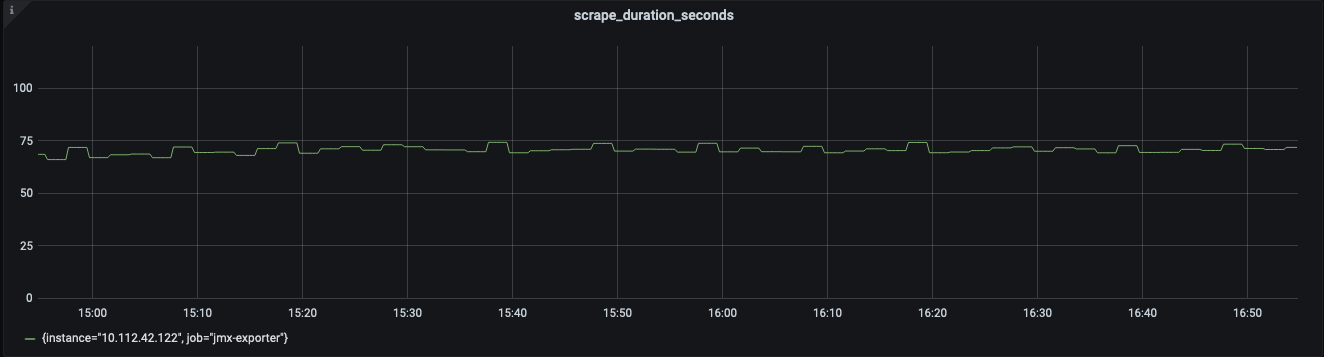
Figure: Collection time (in seconds) of a single Kafka broker with no prior code change.
This meant that metrics usable by automated alerting or engineers would have, at best, one datapoint per time series every 70 seconds. This would have made monitoring an infrastructure supporting real-time use cases difficult, e.g: noticing spikes in incoming traffic, garbage collection pauses, etc. would be more difficult to spot.
We dug into the JMX Exporter codebase and realised some operations were repeated at every collection. Sometimes hundreds of thousands of times per collection. For Kafka, some metrics are available with a topic-partition granularity; if a Kafka cluster contains thousands of topic-partitions, thousands of metrics are exposed. One of the operations that seemed the most costly was matching MBean names against a configured set of regular expressions, which then computes Prometheus sample name and labels.
The set of regular expressions is immutable over the lifespan of the exporter and between configuration reloads. This means that if an MBean name matches one of the regular expressions (or does not match any) during the first metric collection, it will match it for all collections until the configuration is changed or reloaded. The result of matching MBean names against the set of regular expressions can hence be cached and the time-consuming task of matching regular expressions (and computing sample name and labels) skipped during further collections.
After introducing this cache, heavy computations are made only once throughout the lifespan of the exporter. The initial collection does the heavy work of caching and takes a significant amount of time to complete, however subsequent collections take very little time. Collections that used to take 70 seconds, now take around 3 seconds. This allows us to have more fine-grained dashboards and alerting.
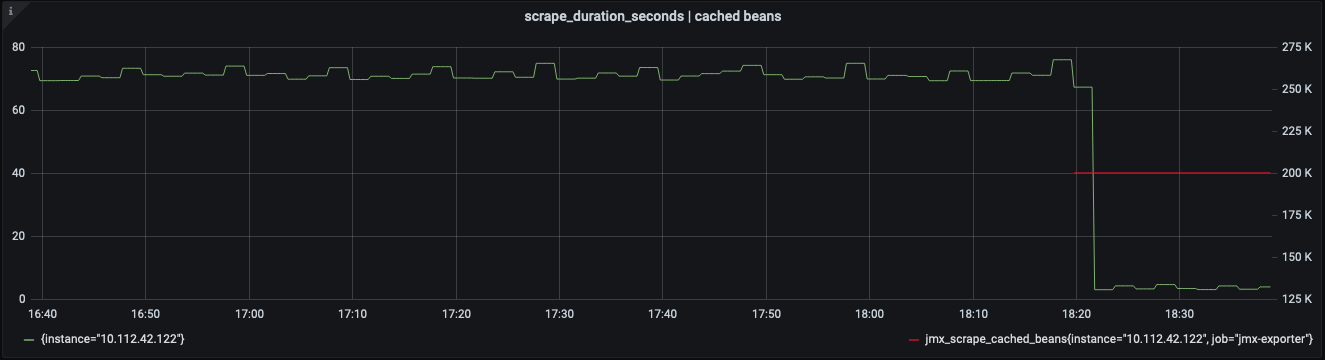
Figure: Collection time (in seconds) before and after enable rules caching. Red line shows the number of MBeans in the cache.
This change is now available in the upstream jmx_exporter, and can be toggled on/off depending on the use case.
Looking Further
As mentioned in the introduction, the usage of Prometheus at Yelp is growing and many systems and teams rely on it for monitoring, dashboards and automated alerting. The changes to the JMX exporter are only a small part of a large initiative driven by our Production Engineering team, watch this space for more insights into this journey!
Acknowledgements
Brian Brazil for code reviews and best practices
Site Reliability Engineering at Yelp
Want to build and manage scaleable, self-healing, globally-distributed systems?
View Job