Introducing Folium: Enabling Reproducible Notebooks at Yelp

-
Lydian Lee, ML Platform Tech Lead; Ryan Irwin, Engineering Manager
- Oct 21, 2020
Jupyter notebooks are a key tool that powers Yelp data. It allows us to do ad hoc development interactively and analyze data with visualization support. As a result, we rely on Jupyter to build models, create features, run Spark jobs for big data analysis, etc. Since notebooks play a crucial role in our business processes, it is really important for us to ensure the notebook output is reproducible. In this blog post, we’ll introduce our notebook archive and sharing service called Folium and its key integrations with our Jupyterhub that enable notebook reproducibility and improve ML engineering developer velocity.
Folium for Notebook Archiving & Sharing
There are a few ways to archive and share notebooks (i.e., exporting to html, saving .ipnb files in Github, shared network drives). There are also some other higher-level frameworks for notebook archiving, but these frameworks lacked integration with Jupyterhub, searchability, and additional customizations presented in this post.

Figure 1. Folium and Jupyterhub
Folium is a basic front-end service that also has APIs that interact with our Jupyterhub. These APIs enable uploading after developing a notebook. While uploading a notebook, the user is prompted for tags (i.e., project name, ticket) and a potential description fetched from the notebook automatically. The front-end service part provides the ability to search for notebooks by user, tag, or documentation of the notebooks. It also renders the notebooks in the webpage including the different notebook versions (more on this later!) and extracts a table of contents by extracting markdown in the notebook.
The functionality described above laid the basic foundation of notebook archiving and sharing, but we built several additional features that we want to share on helping with reproducibility of notebooks:
- The notebook running environment is logged so that we can easily reproduce the output.
- Versions of the same notebooks are grouped together to easily compare their differences.
- The shared notebooks can be directly imported into Jupyter server so that people can easily reproduce or improve on the existing notebooks.
- Adjust variables and rerun existing notebooks directly from Folium without going to Jupyterhub.
- Tags system allows searching and grouping related notebooks.
We will talk about each function in more detail in the following sections.
Logged Notebook Running Environment
We have a Jupyterlab extension installed on our Jupyterhub that takes care of import/export functionality to Folium. When exporting to Folium, the extension gathers the running environment from the current notebook servers, so that the key information is also logged into the notebook’s metadata. Currently we log which docker image and kernel are being used so that when re-running this notebook, we will be able to choose the correct working environment. We also log the memory and CPU/GPUs used so that users can pick the correct amount of resources in order to re-run the notebook. For different tasks, some might need more computation powers, versus some of the tasks may need to have higher memory. Without knowing how the resources are being used by current notebooks, we would likely get out-of-memory issues when rerunning the notebooks.
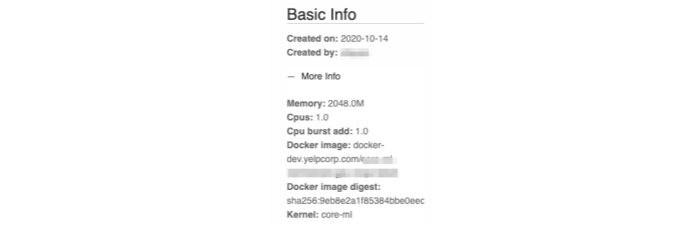
Figure 2. Basic Notebook Information
Import Notebook from Folium to Jupyterhub
The same Jupyterlab extension mentioned above also allows us to import notebooks directly from Folium via its APIs. People can search and preview all the available Folium notebooks, and directly import them into Jupyterhub. We regularly use this function for collaboration and for improving on old models.
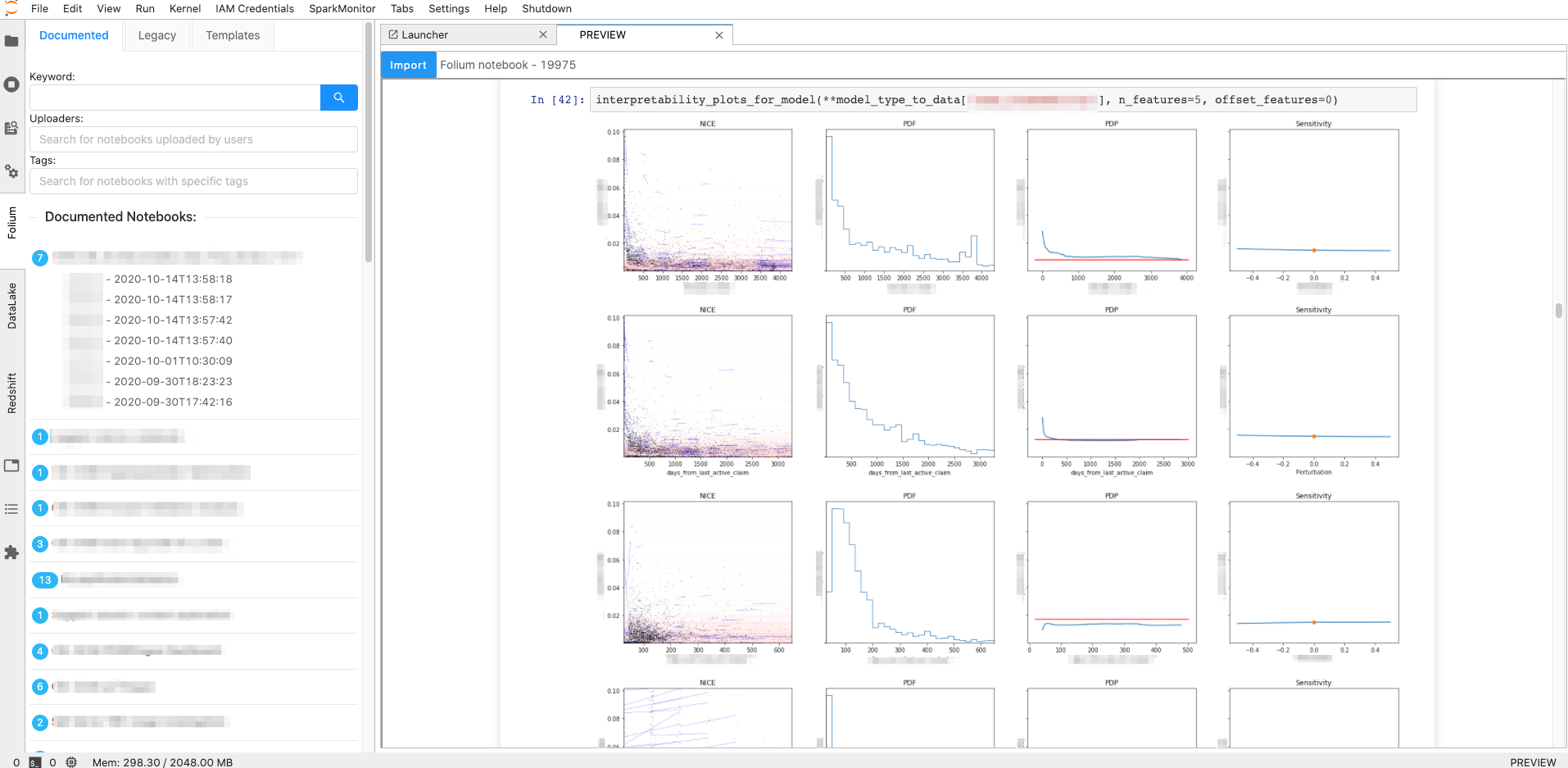
Figure 3. Search Folium’s notebook archive and import within Jupyterhub
Grouping of Different Versions of Notebooks
Often an analysis is valuable enough that it needs to be repeated. This means a user will upload multiple similar notebooks. When a user does this, we group these similar notebooks together on the same page. Therefore we can directly compare the result of different versions of notebooks. We also use this feature to provide tutorials as well, where you can put the question and answer on the same page for people to learn by themselves. In addition to that, we also link the related code review on this notebook in the Folium, so that people can easily refer to the feedback for the notebooks.
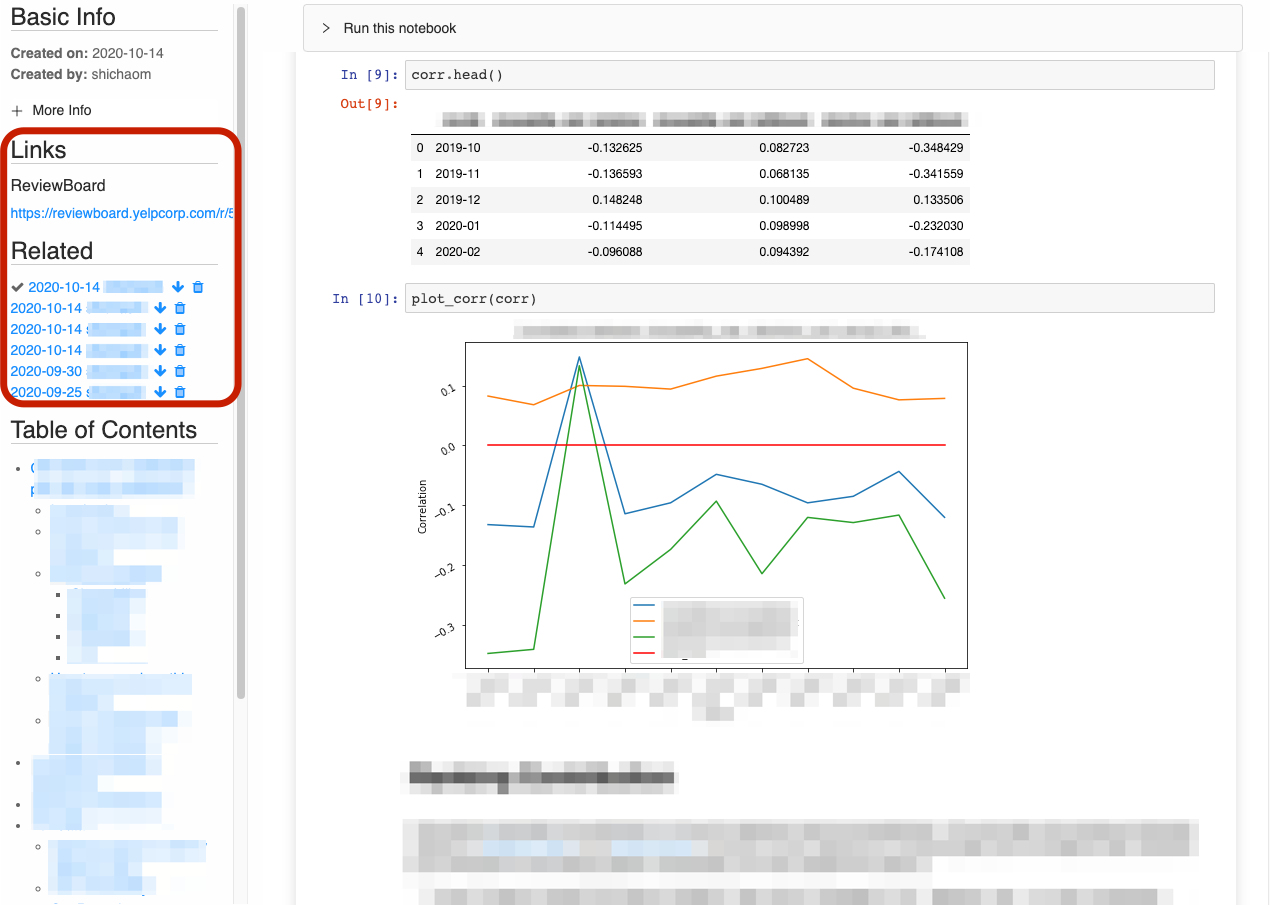
Figure 4. Different versions of notebooks linked together and related links are also highlighted.
Parametrized Notebooks
Besides importing a notebook to Jupyterhub, we also have the feature that allows users to directly rerun the notebook with different parameters in Folium. This helps us reuse the notebooks and quickly get us the result for similar analyses.
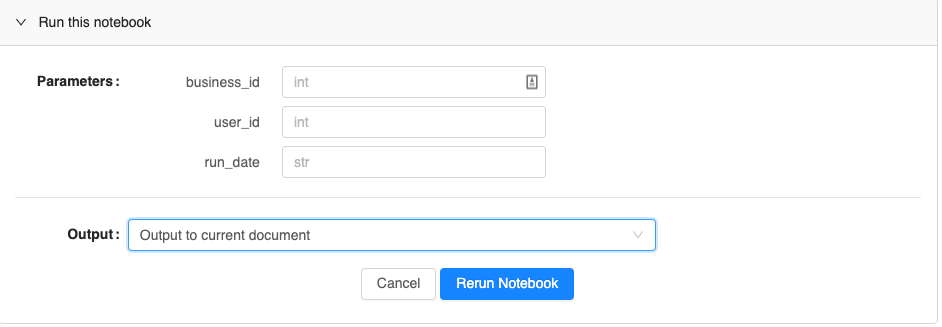
Figure 5. Substitute variables and rerun notebooks from Folium
Tagging and Search System
Searching is also a key thing in reusing the notebook. Without search integration, we will end up having lots of similar notebooks being recreated. This is exactly the issue we’re seeing before improving the tagging and search system on Folium. People have to constantly recreate the same notebooks, because they are not aware there are similar notebooks that can be easily imported and reused. As a result, we fixed the issue by automatically fetching the markdown from notebooks to generate required descriptions that helps users to search for specific notebooks. Free form tagging is also supported and being used widely for teams to tag the notebooks they owned or grouping the notebooks related to specific projects.
The Folium web service has a simple search results page (SERP) with filtering by tag and user. Also, the search API supporting the SERP is also leveraged for searching in the sidebar from Jupyter as shown in Figure 2.
Future Work
Folium is a tool that not only helps us share the code, but also helps us reuse the built notebooks to accelerate our daily work! On the roadmap, we are looking to continuously improve it by providing the ability to review notebooks, including a view of diffs and commenting. We are also adding more ways to get re-run notebooks delivered, including the option of emailed reports.
Acknowledgements
Thanks to the Core ML team for building and continuously improving our Jupyter and Folium infrastructure, and thanks to Blake Larkin, Ayush Sharma, Shuting Xi, Jason Sleight for editing the blog post.
Become an ML Platform Engineer at Yelp
Interested in designing, building, and deploying ML infrastructure systems? Apply to become an ML Platform Engineer today.
View Job