Minimizing read-write MySQL downtime

-
Nick Del Nano, Database Reliability Engineer
- Nov 9, 2020
The relational database of choice at Yelp is MySQL and it powers much of the Yelp app and yelp.com. MySQL does not include a native high-availability solution for the replacement of a primary server, which is a single point of failure. This is a tradeoff of its dedication to ensuring consistency. Replacing a primary server is sometimes necessary due to planned or unplanned events, like an operating system upgrade, a database crash or hardware failure. This requires pausing data modifications to the database while the server is restarted or replaced and can mean minutes of downtime. Pausing data modifications means that our users can’t perform actions like writing reviews or messaging a home service professional, and this amount of downtime must be minimized to the shortest amount possible. This post details how Yelp has integrated open-source tools to provide advanced MySQL failure detection and execute automated recoveries to minimize the downtime of our read-write MySQL traffic.
Characteristics of MySQL infrastructure at Yelp
Our MySQL infrastructure is made up of:
- Hundreds of thousands of queries per second from HTTP services and batch workloads (lots of low latency, user facing web traffic!)
- Applications connect to MySQL servers through a layer 7 proxy, open-source ProxySQL
- MySQL clusters have a single primary and use semisynchronous replication. Most deployments span geographically sparse data centers (we love scaling with MySQL replicas!)
- ZooKeeper based service discovery system, used for applications to discover proxies and proxies to discover MySQL databases
- Open-source Orchestrator deployed to multiple datacenters in raft consensus mode for high availability and failure detection of MySQL servers
MySQL primary replacements are performed due to MySQL crashes, hardware failure and maintenance (hardware, operating system, MySQL upgrades). For unplanned failures, Orchestrator detects the failure and initiates the recovery procedure. For planned server upgrades, an on-call engineer can invoke Orchestrator’s primary replacement procedure.
We are able to minimize MySQL downtime when replacing a MySQL primary because:
- MySQL clients (applications) remain connected to a proxy tier
- Orchestrator detects failure within seconds, then initiates MySQL specific recoveries and elects a new primary server
- the new primary server indicates to the service discovery system that it is the primary for a set of databases
- the proxy tier watches for the update to the service discovery system and adds the identity of the new primary server to its configuration
When the proxy tier has discovered the new primary server, the replacement is complete and applications are again able to write data to the database.
This procedure is completed in seconds!
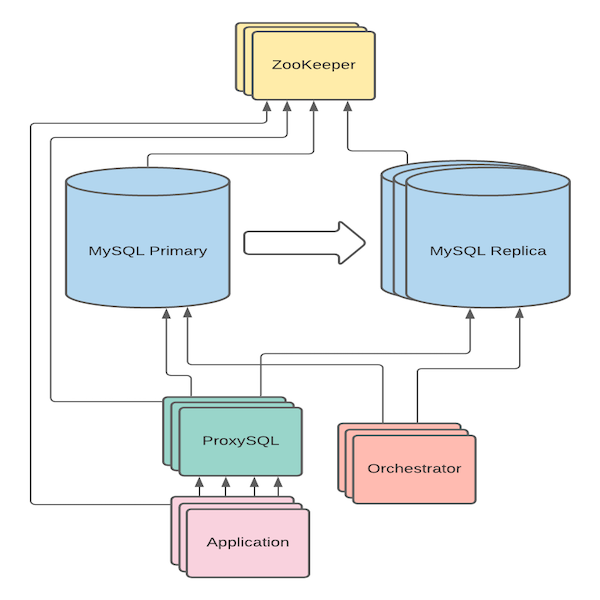
A closer look at how everything fits together:
- Individual components store and consume data in ZooKeeper, storing their own identities (IP addresses) and reading the identities of other components
- Applications establish connections to ProxySQL and issue queries
- ProxySQL maintains a connection pool to each MySQL server, and proxies client connections to connections in its pool
- Orchestrator maintains a connection pool to each MySQL server, constantly performing health checks and is ready to initiate a failure recovery when necessary
ProxySQL as a highly available proxy layer
ProxySQL is a high performance, high availability, protocol aware proxy for MySQL. We love ProxySQL because it limits the number of MySQL connections to our MySQL servers and it permits us to replace MySQL servers without requiring applications to re-establish their database connections.
Deployment
We deploy ProxySQL using AWS Auto-scaling groups and AWS EC2. We configure these servers to run ProxySQL after powering on, using Puppet, and since they are relatively stateless we are able to add or replace ProxySQL capacity very quickly, in less than 10 minutes.
Configuring ProxySQL to route to MySQL backends
We use ProxySQL’s hostgroup functionality to group MySQL servers into tuples of (MySQL schema, MySQL role), where MySQL schema is one of our vertical shards to isolate workloads and MySQL role is one of {primary, replica, reporting replica} to isolate read/write, read only, and non-user facing read traffic respectively. A single MySQL user maps uniquely to a hostgroup, which means that an application only needs to present a username and password to ProxySQL to be routed and load balanced to the proper database and database role.
Each ProxySQL server must be configured with the set of available MySQL servers and continue to stay up to date as MySQL capacity is added, replaced, or when hosts transition between MySQL roles and therefore hostgroups. On a several minute interval, a script runs on each ProxySQL server to read the available MySQL servers and their roles from our ZooKeeper based service discovery system and load them into ProxySQL’s configuration as hostgroups. This script is idempotent and also contains important verification functionality, such as preventing a mass-removal of MySQL servers if an outage of the service discovery system is detected or ensuring that only one server exists in the “primary” hostgroup for each cluster. The latter verification method is a key component of ensuring that our primary failover system is safe in the face of network partitions.
Applications connecting to ProxySQL
Just as MySQL servers register into service discovery so that they can be discovered by ProxySQL servers, ProxySQL servers register into the same system so that applications are able to discover and connect to them. Applications read the identity of ProxySQL servers from service discovery and supply a username and password deployed with the application to initiate their MySQL connections.
Service Discovery
At Yelp, the data plane of our service discovery system consists of a daemon on each server that performs HTTP or TCP healthchecks on a service, and if the service is healthy, stores information including the IP address and port of the service in ZooKeeper. If a service fails to respond successfully to its healthcheck, this daemon will remove the state of the failing service instance. A separate daemon is responsible for reading the state in ZooKeeper and proxying requests through the service mesh.
MySQL registration and healthcheck
MySQL servers are grouped by (MySQL schema, MySQL role) where MySQL role is a value in {primary, replica, reporting replica}. Both the MySQL schema and MySQL role values are represented as files on disk of each MySQL server. These files are understood by the process that performs health checks and are used to represent the (MySQL schema, MySQL role) groupings in ZooKeeper.
Our health check for the MySQL replica services is more thorough than only verifying that the MySQL port is open since these servers are running stateful workloads that require significant configuration. Before a MySQL replica is deemed to be healthy, it must pass all of the monitoring checks defined using our monitoring framework. To accommodate this, an HTTP service is deployed on each MySQL server to provide an HTTP health check endpoint which verifies that the server has passed all of its monitoring checks before the MySQL process is considered healthy. Some examples of these monitoring checks are:
- The server restored from backup successfully
- The server is replicating and is caught up to real time
- The server is “warmed” by streaming a MySQL buffer pool from another server in the cluster and loading it into its own buffer pool
ProxySQL healthcheck
Because ProxySQL servers are lightweight and almost completely stateless, a ProxySQL server is considered healthy as long as it is listening for TCP connections on the defined ProxySQL port. After the ProxySQL process is launched and begins listening for TCP connections, it passes its health check and is discoverable by applications.
Orchestrator driven Failure Recovery
Orchestrator is an open source MySQL high availability and replication management tool that provides failure detection and automated recovery of MySQL servers. We deploy Orchestrator using its distributed raft mode in order to have the service be highly available and to provide improved failure detection of MySQL servers. Orchestrator’s failure recovery features solve the single point of failure presented with a single primary MySQL configuration mentioned earlier in this post.
Upon detecting a failure of a MySQL server, the multiple orchestrator instances running in raft mode will seek consensus of the identified failure, and if a quorum of instances agree, a recovery will proceed.
If the failed server is a replica and is a replication source for other replicas, Orchestrator will ensure that these replicas are re-configured to replicate from a healthy replication source. If the failed server is a primary, Orchestrator will proceed to set the failed primary to read-only mode (MySQL variable @@read_only=1), identify a candidate to be promoted to primary, re-configure replicas of the former primary to replicate from the candidate primary, and set the candidate primary to read-write mode (@@read_only=0). Orchestrator handles the MySQL specific changes for replacing a primary server and allows definitions of “failover hooks” to run custom defined commands during different phases of the recovery process.
Primary Failover Hooks
Orchestrator performs the MySQL specific part of the failover but there are still other changes required, such as modifying the file on disk representing a server’s MySQL role to the service discovery system. An HTTP service exists on each MySQL server in order to support this, and failover hooks are configured to send an HTTP request to both the former and newly promoted primaries to update their MySQL role. After this hook executes, the service discovery daemon will notice that the MySQL role of the promoted primary has changed and will update the identity of the primary server in ZooKeeper.
Configuring ProxySQL with the updated Primary
As mentioned earlier, each ProxySQL server runs a script on a several minute interval which reads the MySQL service discovery state in ZooKeeper and ingests this data to ProxySQL’s configuration. In order to reduce the recovery time after a primary failover, a separate process runs on ProxySQL servers to watch the identities of MySQL primaries in ZooKeeper and to initiate the previous process immediately when a change is noticed.
Perspective of a MySQL client during a primary failover
After Orchestrator issues set @@read_only=1 on the former primary, clients will see INSERT/UPDATE/DELETE queries fail. These failures will remain until ProxySQL has updated its hostgroup configuration to replace the failed primary with the promoted one. Neither applications or ProxySQL need to create new TCP connections – clients remain connected to the same ProxySQL server and each ProxySQL server already has an existing pool of connections to the promoted primary because it was previously existing as a replica. After modifying its hostgroup configuration, a ProxySQL server is able to route MySQL traffic to the new primary.
Special cases: network partitioning and avoiding split-brain
This failure recovery system is carefully designed to make the right decision in failure scenarios caused by a network partition. A partial or incorrect failure recovery due to a network partition has the potential to leave the system with multiple primary hosts, each believing they are the primary, resulting in a divergence of the dataset known as “split-brain”. It is very difficult to repair a split-brain scenario, so we have several components in this system to help prevent this.
One mechanism to prevent the possibility of split-brain is validation in the logic which transforms the service discovery data in ZooKeeper into ProxySQL’s hostgroup configurations. If there is more than 1 primary registered in ZooKeeper, the script will refuse to make changes to the hostgroup configurations and emit an alert to page an on-call responder who can inspect and appropriately remediate this situation.
We also set Orchestrator’s PreventCrossDataCenterMasterFailover value to true so that Orchestrator would not ever elect a new MySQL primary in a separate datacenter. We use this setting because we would not want to change the datacenter of a MySQL cluster’s primary without considerable planning and because it reduces the surface area of potential network partition scenarios that could result in split-brain.
Conclusions
Thanks to these systems, we are able to quickly recover from MySQL failures and maximize the availability of Yelp for our users, ensuring a smooth user experience.
Become a Database Reliability Engineer at Yelp
Want to help make our databases even more reliable?
View Job