Server Side Rendering at Scale

-
Emma Worley and Kedar Vaidya, Software Engineers
- Feb 22, 2022
At Yelp, we use Server Side Rendering (SSR) to improve the performance of our React-based frontend pages. After a string of production incidents in early 2021, we realized our existing SSR system was failing to scale as we migrated more pages from Python-based templates to React. Throughout the rest of the year, we worked to re-architect our SSR system in a way that increased stability, reduced costs, and improved observability for feature teams.
Background
What Is SSR?
Server Side Rendering is a technique used to improve the performance of JavaScript templating systems (such as React). Rather than waiting for the client to download a JavaScript bundle and render the page based on its contents, we render the page’s HTML on the server side and attach dynamic hooks on the client side once it’s been downloaded. This approach trades increased transfer size for increased rendering speeds, as our servers are typically faster than a client machine. In practice, we find that it significantly improves our LCP timings.
Status Quo
We prepare components for SSR by bundling them with an entrypoint function and any other dependencies into a self-contained .js file. The entrypoint then uses ReactDOMServer, which accepts component props and produces rendered HTML. These SSR bundles are uploaded to S3 as part of our continuous integration process.
Our old SSR system would download and initialize the latest version of every SSR bundle at startup so that it’d be ready to render any page without waiting on S3 in the critical path. Then, depending on the incoming request, an appropriate entrypoint function would be selected and called. This approach posed a number of issues for us:
- Downloading and initializing every bundle significantly increased service startup time, which made it difficult to quickly react to scaling events.
- Having the service manage all bundles created a massive memory requirement. Every time we scaled horizontally and spun up a new service instance, we’d have to allocate memory equal to the sum of every bundle’s source code and runtime usage. Serving all bundles from the same instance also made it difficult to measure the performance characteristics of a single bundle.
- If a new version of a bundle was uploaded in between service restarts, the service wouldn’t have a copy of it. We solved this by dynamically downloading missing bundles as needed, and used an LRU cache to ensure we weren’t holding too many dynamic bundles in memory at the same time.
The old system was based on Airbnb’s Hypernova. Airbnb has written their own blog post about the issues with Hypernova, but the core issue is that rendering components blocks the event loop and can cause several Node APIs to break in unexpected ways. One key issue we encountered is that blocking the event loop will break Node’s HTTP request timeout functionality, which significantly exacerbated request latencies when the system was already overloaded. Any SSR system must be designed to minimize the impact of blocking the event loop due to rendering.
These issues came to a head in early 2021 as the number of SSR bundles at Yelp continued to increase:
- Startup times became so slow that Kubernetes began marking instances as unhealthy and automatically restarting them, preventing them from ever becoming healthy.
- The service’s massive heap size led to significant garbage collection issues. By the end of the old system’s lifetime, we were allocating nearly 12GB of old heap space for it. In one experiment, we determined that we were unable to serve >50 requests per second due to lost time spent in garbage collection.
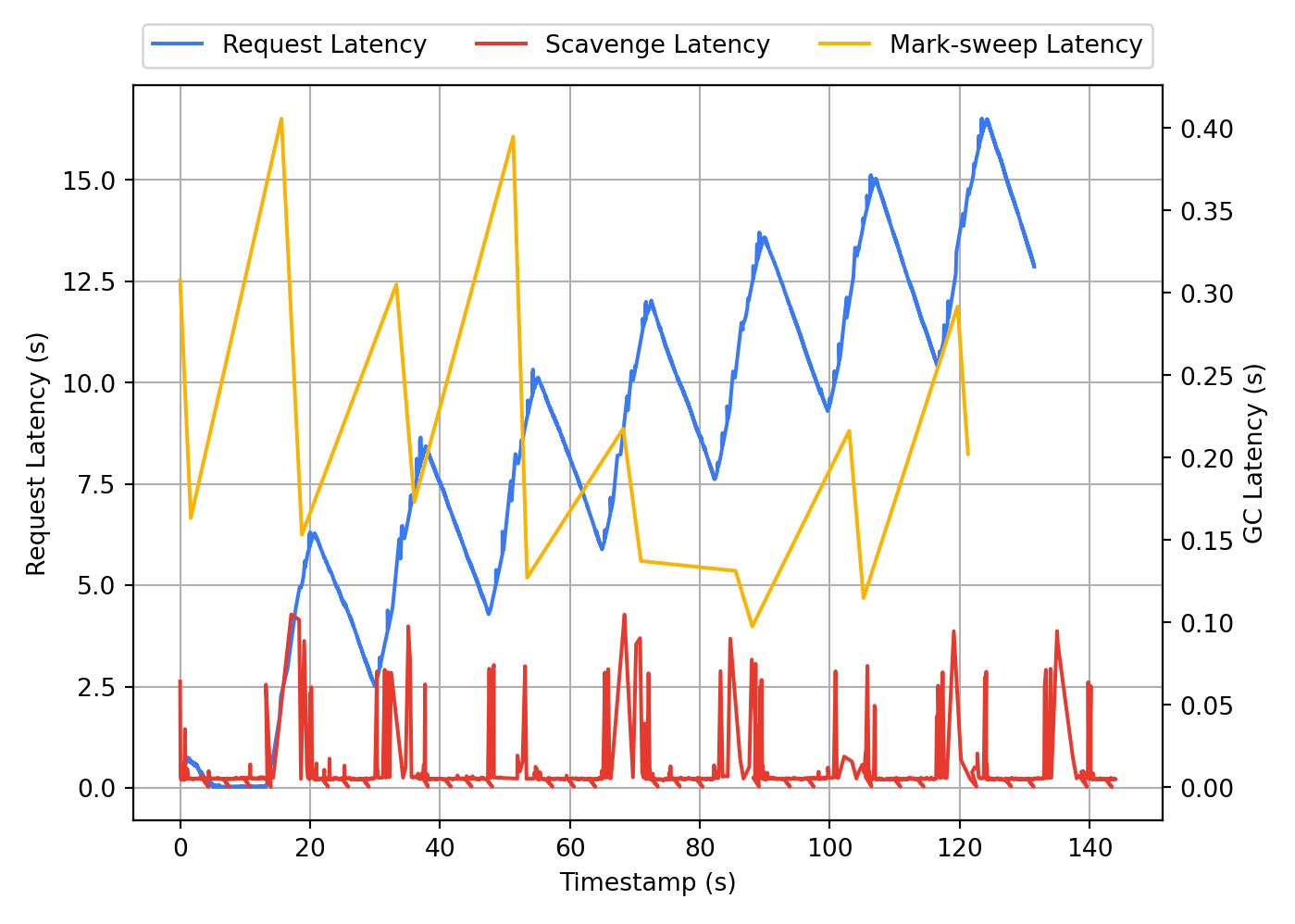
Request Latency
- Thrashing the dynamic bundle cache due to frequent bundle eviction and re-initialization created a large CPU burden that began affecting other services running on the same host.
All of these issues degraded Yelp’s frontend performance and led to several incidents.
Re-architecture Goals
After dealing with these incidents, we set out to re-architect our SSR system. We chose stability, observability, and simplicity as our design goals. The new system should function and scale without much manual intervention. It should be easy to observe not only for infra teams, but for bundle-owning feature teams as well. The design of the new system should be easy for future developers to understand.
We also chose a few specific, functional goals:
- Minimize the impact of blocking the event loop so that features like request timeouts work correctly.
- Shard service instances by bundle, so that each bundle has its own unique resource allocation. This reduces our overall resource footprint and makes bundle-specific performance easier to observe.
- Be able to fast-fail requests we don’t anticipate being able to serve quickly. If we know it’ll take a long time to render a request, the system should immediately fall back to client-side rendering rather than waiting for SSR to time out first. This provides the fastest possible UX to our end users.
Implementation
Language Choice
We evaluated several languages when it came time to implement the SSR Service (SSRS), including Python and Rust. It would have been ideal from an internal ecosystem perspective to use Python, however, we found that the state of V8 bindings for Python were not production ready, and would require a significant investment to use for SSR.
Next, we evaluated Rust, which has high quality V8 bindings that are already used in popular production-ready projects like Deno. However, all of our SSR bundles rely on the Node runtime API, which is not part of bare V8; thus, we’d have to reimplement significant portions of it to support SSR. This, in addition to a general lack of support for Rust in Yelp’s developer ecosystem, prevented us from using it.
In the end, we decided to rewrite SSRS in Node because Node provides a V8 VM API that allows developers to run JS in sandboxed V8 contexts, has high quality support in the Yelp developer ecosystem, and would allow us to reuse code from other internal Node services to reduce implementation work.
Algorithm
SSRS consists of a main thread and many worker threads. Node worker threads are different from OS threads in that each thread has its own event loop and memory cannot be trivially shared between threads.
When the main thread receives an HTTP request, it executes the following steps:
- Check if the request should be fast-failed based on a “timeout factor.” Currently, this factor includes the average rendering run time and current queue size, but could be expanded upon to incorporate more metrics, like CPU load and throughput.
- Push the request to the rendering worker pool queue.
When a worker thread receives a request, it executes the following steps:
- Performs server side rendering. This blocks the event loop, but is still allowable since the worker only handles one request at a time. Nothing else should be using the event loop while this CPU-bound work happens.
- Return the rendered HTML back to the main thread.
When the main thread receives a response from a worker thread, it returns the rendered HTML back to the client.
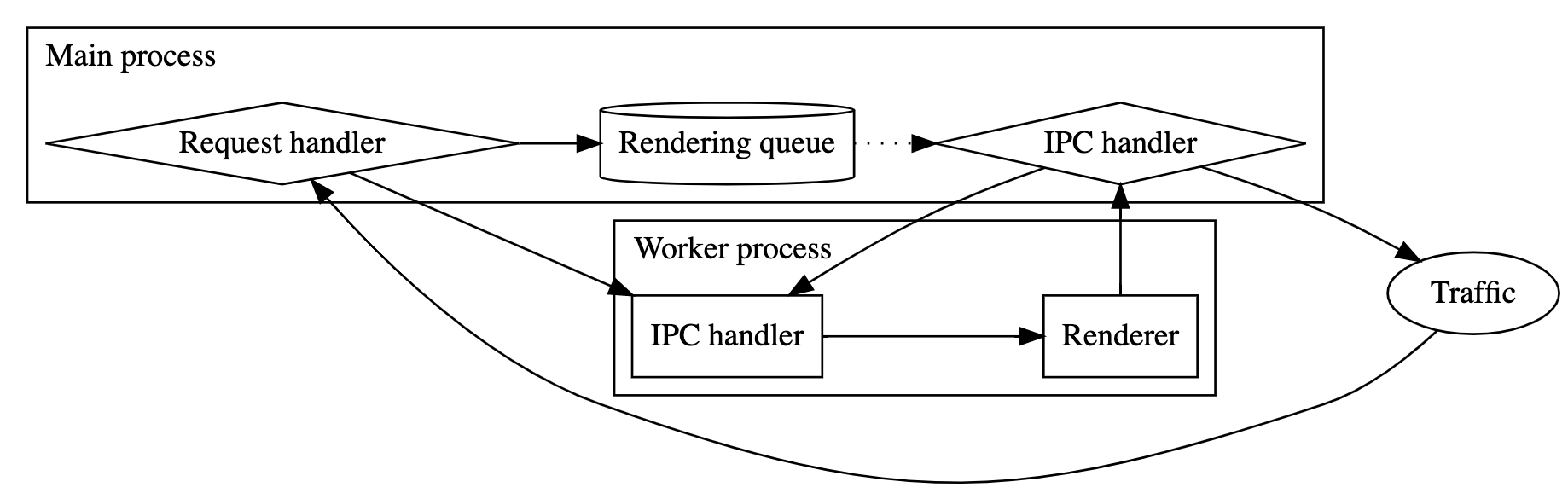
SSRS Architecture
This approach provides us with two important guarantees that help us meet our requirements:
- The event loop is never blocked in the main web server thread.
- The event loop is never needed while it’s blocked in a worker thread.
We used Piscina, a third-party library that provides the functionality described above. It manages thread pools with support for task queueing, task cancellation, and many other useful features. Fastify was chosen to power the main thread web server because it’s both highly performant and developer-friendly.
Fastify Server:
const workerPool = new Piscina({...});
app.post('/batch', opts, async (request, reply) => {
if (
Math.min(avgRunTime.movingAverage(), RENDER_TIMEOUT_MSECS) * (workerPool.queueSize + 1) >
RENDER_TIMEOUT_MSECS
) {
// Request is not expected to complete in time.
throw app.httpErrors.tooManyRequests();
}
try {
const start = performance.now();
currentPendingTasks += 1;
const resp = await workerPool.run(...);
const stop = performance.now();
const runTime = resp.duration;
const waitTime = stop - start - runTime;
avgRunTime.push(Date.now(), runTime);
reply.send({
results: resp,
});
} catch (e) {
// Error handling code
} finally {
currentPendingTasks -= 1;
}
});
Scaling
Autoscaling for Horizontal Scaling
SSRS is built on PaaSTA, which provides autoscaling mechanisms out of the box. We decided to build a custom autoscaling signal that ingests the utilization of the worker pool:
Math.min(currentPendingTasks, WORKER_COUNT) / WORKER_COUNT;
This value is compared against our target utilization (setpoint) over a moving time window to make horizontal scaling adjustments. We found that this signal helps us keep per-worker load in a healthier, more accurately provisioned state than basic container CPU usage scaling does, ensuring that all requests are served in a reasonable amount of time without overloading workers or overscaling the service.
Autotuning for Vertical Scaling
Yelp is composed of many pages with different traffic loads; as such, the SSRS shards that support these pages have vastly different resource requirements. Rather than statically defining resources for each SSRS shard, we took advantage of dynamic resource autotuning to automatically adjust container resources like CPUs and memory of shards over time.
These two scaling mechanisms ensure each shard has the instances and resources it needs, regardless of how little or how much traffic it receives. The biggest benefit is running SSRS efficiently across a diverse set of pages while remaining cost effective.
Wins
Rewriting SSRS with Piscina and Fastify allowed us to avoid the blocking event loop issue that our previous implementation suffered from. Combined with a sharded approach and better scaling signals allowed us to squeeze more performance, while reducing cloud compute costs. Some of the highlights include:
- An average reduction of 125ms p99 when server side rendering a bundle.
- Improved service startup times from minutes in the old system to seconds by reducing the number of bundles initialized on boot.
- Reduced cloud compute costs to one-third of the previous system by using a custom scaling factor and tuning resources more efficiently per-shard.
- Increased observability since each shard is now responsible for rendering one bundle only, allowing teams to more quickly understand where things are going wrong.
- Created a more extensible system allowing for future improvements like CPU profiling and bundle source map support.
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job