Beyond Matrix Factorization: Using hybrid features for user-business recommendations

-
Srivathsan Rajagopalan, Machine Learning Engineer
- Apr 25, 2022
Yelp’s mission is to connect people with great local businesses. On the Recommendations & Discovery team, we sift through billions of users-business interactions to learn user preferences. Our solutions power several products across Yelp such as personalized push notifications, email engagement campaigns, the home feed, Collections and more. Here we discuss the generalized user to business recommendation model which is crucial to a lot of these applications.
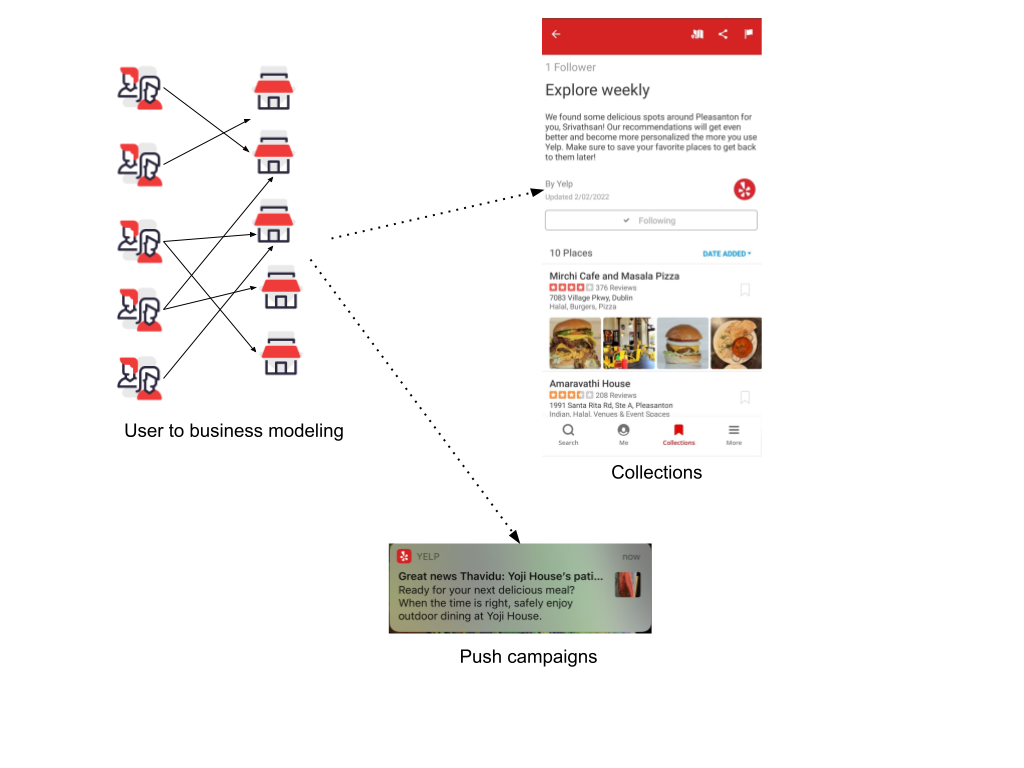
High level overview of our recommendation system.
Our previous approach for user to business recommendation was based on Spark’s Alternating Least Squares (ALS) algorithm which factorized the user-business interaction matrix to user-vectors and business-vectors. By performing a dot-product on top of these vectors we are able to come up with top-k recommendations for each user. We explained the approach in detail in a prior blog - “Scaling Collaborative Filtering with PySpark”.
In this blog, we discuss how we switched from a collaborative filtering approach to a hybrid approach - which can handle multiple features and be trained on different objectives. The new approach doubled the number of users we could recommend for while also vastly improving performance for all users. The main takeaway here is that we were able to achieve these results pretty quickly by having a clearly defined objective and following a cost-efficient design which saved huge development costs for our initial Proof of Concept.
We start with discussing drawbacks of matrix factorization followed by some guidelines that shaped our approach. We later present the solution along with challenges and the improvements gained
Drawbacks of matrix factorization
Matrix factorization learns ID-level vectors for each user and business and requires a good number of user/business level interactions. This leads to a couple of major drawbacks:
- Worse performance on tail users (users who have very few interactions).
- An inability to add content-based features such as business reviews, ratings, user segment, etc
Because of drawback #1, we identify two segments of users - head and tail.
- Head users have enough interactions with businesses to learn vector representations using the matrix factorization approach.
- Tail users have very few interactions and suffer from the cold-start problem. They were excluded from matrix factorization which resulted in better performance on head users and also made the approach more scalable.
The solution for drawbacks 1 and 2 is to use a hybrid approach which uses content-based features in addition to interaction features. In the evaluation section, we show how content and collaborative features could play different roles for these user types in a hybrid model which results in a better model performance.
First, some guidelines
In our initial exploration phase we considered approaches like Neural Collaborative Filtering, a Two tower model, a WideDeep model and GraphSage. Even though implementations for these approaches were readily available, we found them to be either hard to scale for our problem size or poorly performant when used off the shelf.
To be cost-efficient and gather early feedback, we took an iterative approach towards building a custom solution. We set the following guidelines to adhere to the iterative design:
- Model infrastructure first: Build a training, evaluation and prediction pipeline with a few clearly defined objectives.
- Reduce dev-effort when you can: Use a supervised technique like XGBoost (or Logistic Regression) which were better supported by our ML infrastructure team.
- Know your friend: Replacing matrix factorization seemed like a farther out goal as it is known to work pretty well. So instead of replacing it, we planned to build our hybrid model on top of it by taking its scores as one of the key features.
- Gain more friends: Enrich signals used by the recommender by deriving a good set of content-based features.
A Hybrid recommendation model
We used a supervised learning to rank technique to combine both the content and collaborative approaches. The entire approach is summarized in the diagram below:
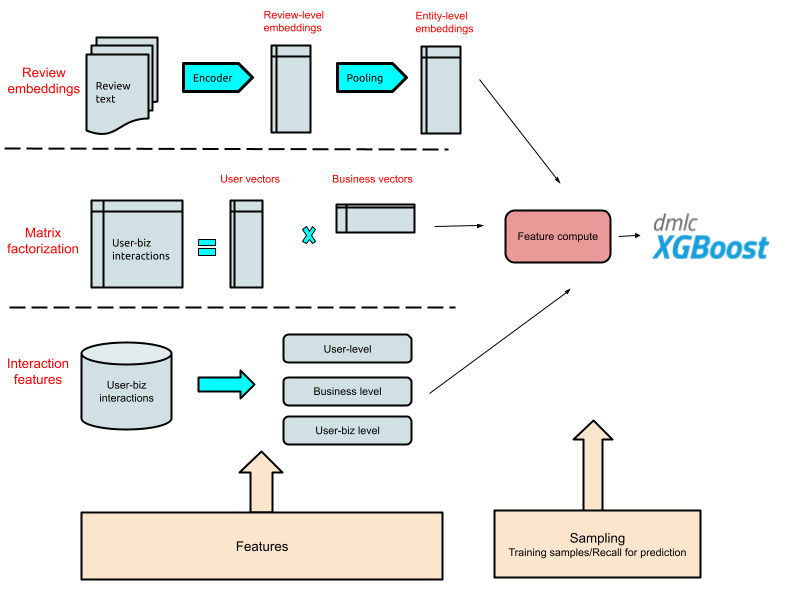
A diagram of our hybrid recommendation approach.
Defining Features
Similar to many other machine learning projects, we anticipated feature engineering to play a key role. Hence, most of our effort went into building a good set of features for the model to learn from. Features were extracted at the user-business level for a specific date which marks the end of the feature period.
The set of features can be categorized into two major buckets:
- Interaction features: Include output affinity scores from matrix factorization and aggregates for different interaction types at user, business and user ✕ business level.
- Content-based features: Include features like categories of a business, review rating, review count, user type, user metadata, etc. Apart from general content features, we also added a text-based similarity feature computed between a user and a business.
We derived the text-based similarity feature from Yelp’s business reviews. Reviews are encoded with a Universal Sentence encoder and later aggregated at the business-level by either a max or average pooling. The business-level embeddings were later aggregated at the user-level by associating a user with all the businesses they have interacted with. The text-based similarity is computed as a cosine similarity between the user-level and the business-level aggregate embeddings. This feature turned out to be the most important content-based feature as discussed in the evaluation section.
With all these features, we need an objective to optimize for which is discussed below.
Defining the Objective
As we aimed to come up with a personalized ranked order of businesses, we used Normalized Discounted Cumulative Gain (NDCG) as our primary metric. The relevance level for NDCG was defined based on the strength of interaction between a user and a business. For example, the gain from business views could be 1.0 as it’s a low-intent interaction whereas bookmarks could be 2.0 as it is a stronger-intent interaction. To ensure there isn’t any label leakage, we made sure there is a clear separation between the time-period where features and labels were generated from.
To optimize for NDCG, we relied on XGBoost’s rank:ndcg objective which internally uses the LambdaMART approach. One thing that’s worth mentioning here is how we defined “groups” for the ranking task. XGBoost uses the group information to construct a pairwise loss where two training rows from the same group are compared against each other. Since our objective was to get personalized recommendations based on where the user is located, we defined our group based on both user and location. We use the same definition of groups when evaluating our models.
Technical challenges
Negative sampling
Since we are using supervised learning, our model will be most effective if it has both positive and negative interaction examples to learn from. For the hybrid user-business model, we don’t have negatives as most of the implicit user-business interactions (e.g. get directions, visit the website, order food, etc.) are positive. Deriving an implicit negative interaction like a user viewing but not interacting with a business is tricky and can be heavily biased as it depends on what businesses were shown to them (sample bias), how it was shown to them (presentation bias), and so forth. Handling these biases are usually product specific (e.g. the presentation biases for search vs. recommendation could be very different) which makes it harder to build a generalized user to business model. A more generalized approach for negative sampling would be to consider all non-interacted businesses as negatives. In fact, some of the common techniques to fetch negatives involve subsampling the non-positive candidates either randomly or based on popularity (refer word2vec negative sampling).
We take a generalized approach to negative sampling but we also introduce a recall-step. Candidate businesses are recalled using a specific selection criteria like user preferences, location radius, etc., and only the recalled candidates are used to train the model. Candidates can be labeled as either positive or negative based on whether these had future interactions. This approach worked well for our use case for couple of reasons:
- A recall step that we can evaluate for only a few candidates per user is more efficient and allows us to scale predictions up to millions of users and businesses.
- A recall step ensures the relationship with the label is learned without any bias when a similar recall strategy is used during training and prediction time. Common techniques of negative sampling relies on resampling negatives multiple times during training (e.g. each training iteration) to reduce bias, but this approach can be difficult to implement with supervised training like XGBoost.
During training, we used a special type of recall that allowed the model to learn generic preferences instead of being very application specific. Users were associated with a sampled set of locations from their past history and a user’s top-k businesses for the locations were recalled using matrix factorization scores or business popularity. We downsampled the user, location pairs and businesses to make the training data size manageable.
Scaling predictions
Prediction is an intensive job where we need to identify top-k recommendations for tens of millions of users and businesses. When using the matrix factorization based approach we scaled the naive approach of evaluating all pairs of dot products using numpy BLAS optimizations and a file-based broadcast on Pyspark. We couldn’t use the same approach here as both feature computation and XGBoost model evaluation are more expensive than just doing a dot-product.
To speed up prediction we added a recall step based on the downstream product application. These applications restrict recommendation candidates based on the following criteria:
- User location: For localized recommendations we need to consider only businesses near the city or neighborhood where the user is located.
- Product level constraints: Candidate businesses are further restricted by category or attribute constraints based on the product application (e.g. new restaurants for the Hot & New business push-notification campaign, businesses with Popular Dishes for the Popular Dish push-notification campaign, etc.) These criteria let us narrow down the set of user-business pairs for which the model needs to be evaluated, thereby making the predictions more scalable.
Evaluation Results
To prove to ourselves the hybrid approach works better, we evaluated the models offline based on historical data. We also evaluated the model subjectively by running a survey among a few Yelp employees who were tasked to rate recommendation rankings from different approaches. Both these evaluations suggested that the new hybrid approach performs much better than the baseline approaches. Here, we share these metrics based results.
Since this is a ranking task, we chose Normalized Discounted Cumulative Gain (NDCG) and Mean average precision (MAP) as metrics. The hybrid approach was compared against a couple of baselines:
- Popular businesses in the user’s location - available for both head and tail users
- Matrix factorization - available only for head users
In order to mimic production settings using historical data, we created test sets which are in the future of the model’s training period (i.e. both feature generation period and label period were shifted into the future for the test set).
At first, we look at the relative improvement from the business popularity baseline at different values of rank (i.e. rank k=1, 3, 5, 10, 20, 30, .., 100). We find that the model more than doubles the NDCG and MAP metrics compared to a “locally popular” baseline at k=1!
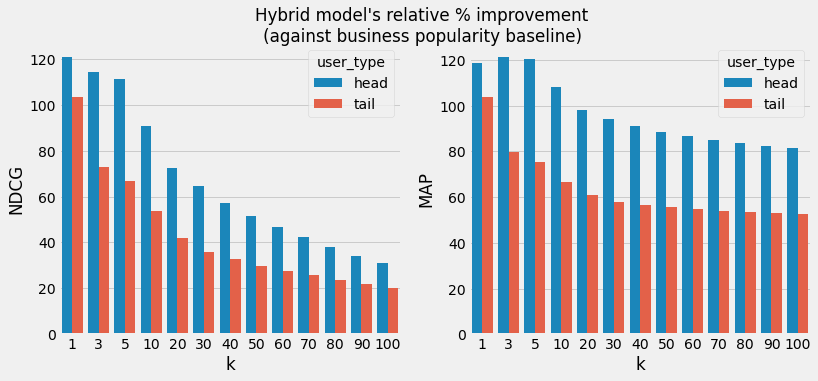
Relative percentage improvement of hybrid approach vs. the popularity baseline. We see positive improvements overall. At k=100 and user_type=head we see an improvement of 30% in the NDCG metric and 81% improvement in the MAP metric. At k=100 and user_type=tail we see a 20% improvement in NDCG metric and 52% improvement in the MAP metric.
When comparing with the matrix factorization baseline, the improvement at different ranks (k) roughly ranges between 5-14% for NDCG and 10-13% for MAP.
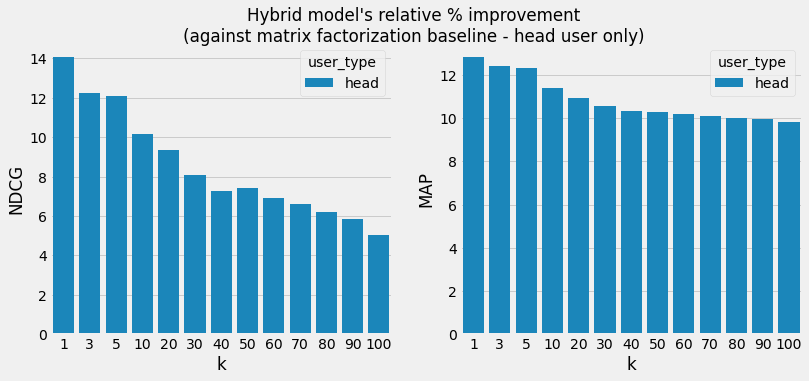
Relative percentage improvement of hybrid approach vs. the matrix factorization baseline. We see positive improvements overall. At k=100 and user_type=head we see an improvement of 5% in the NDCG metric and 9.8% improvement in the MAP metric.
Content vs Collaborative signals for head & tail users
For a hybrid model to work effectively, it should use both content and collaborative signals to achieve the best of both worlds. For head users with a good number of collaborative signals it should rely more on these signals whereas for tail users it should rely more on content-based features. We wanted to validate whether this was indeed happening in our hybrid model.
To perform this analysis, we picked representative features for content and collaborative signals. Review text based similarity and matrix factorization score were the top features in the model and it made sense to pick these as representative features. We use Partial Dependence plots (PDPs) against these features which shows the average prediction on the entire dataset when a feature is set to a particular value.
First, we plot PDP for head vs. tail users against feature percentiles of review text similarity. The plot below shows percentiles of the review text similarity feature (content similarity) on the x-axis and the average of prediction along with spread on y-axis. We see that tail users have a stronger relationship against this feature which indicates that the model relies more on the content-based feature for tail users.
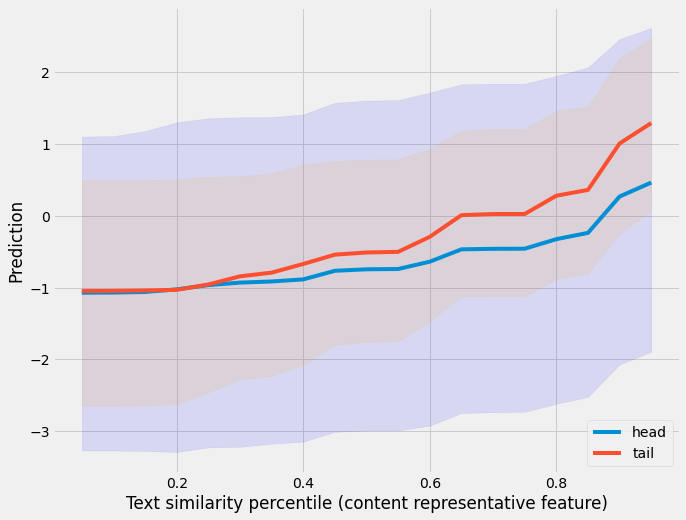
Partial dependence plot (PDPs) with content similarity percentile on x-axis and average prediction on the y-axis. We plot the PDPs for head vs. tail users separately. The plot shows a stronger relation for tail users.
Since matrix factorization scores are available only for head users, we plot PDP against collaborative vs. content for only head users. The plot below shows percentiles of content or collaborative features on the x-axis and average and spread of predictions on the y-axis.
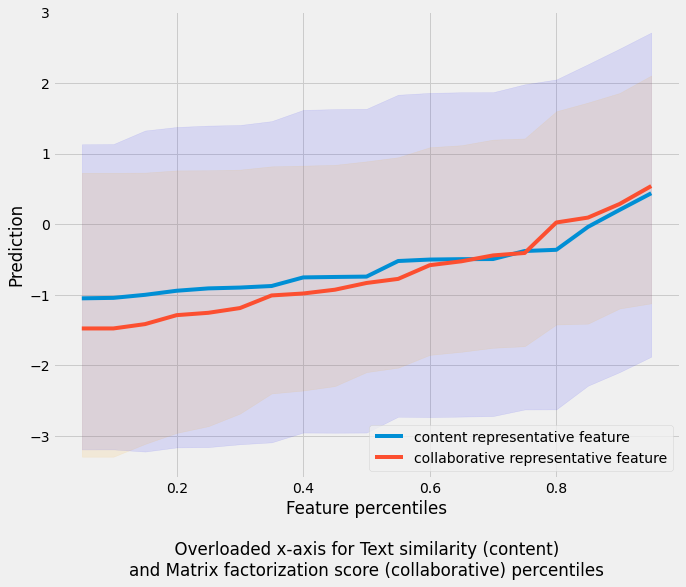
Partial dependence plot (PDPs) against feature percentiles. We overload the x-axis with percentiles from two features and plot two PDPs in the same plot - text similarity feature (content) and matrix factorization score (collaborative). The confidence spread shows a stronger relation for the collaborative feature as the spread narrows at higher percentiles.
We see that both the content and collaborative features are strongly related to the user business relevance prediction, which means that both features are used effectively in the hybrid model. The collaborative feature has a stronger relationship as the prediction spread narrows at higher percentiles. This suggests that head users have a detailed enough browsing history that lets us learn user specific preferences, for example that a user is vegetarian but doesn’t particularly like Thai food.
The above plots confirm our initial thoughts of how content and collaborative features can play different roles for different user types in the hybrid model.
Learnings
- Write down your objective: Recommendation is a vast space and there are a lot of approaches one could take to improve it. Our initial exploration phase had a lot of uncertainty. However, writing down our specific goals to “Provide model-based recommendations for tail users” and “Enable support for more content-based features” gave us the focus we needed to improve our models and made it easier to get buy-in from the product team.
- Setup model training infrastructure early: In the beginning, it was hard to debug and iterate with several copies of code on different ad hoc notebooks. Once we built out the first version of the training pipeline to include feature ETLs, sampling and label strategies, it was easy to iterate on each of these components separately.
- Think about evaluation earlier: We set up the baselines based on matrix factorization and business popularity very early in our model development. This made it easy to compare results against these baselines and iterate on the modeling and training phases until we beat the baseline.
- Use subjective evaluation in conjunction: In addition to objective metrics, it is important to look at individual recommendations, feature importances and PDPs to make a better judgment. At one point, we had an issue with negative sampling where all negative samples came from matrix factorization top-k which made the model learn a negative relationship with respect to this feature. It’s hard to debug these issues without the help of model debugging tools.
Future work
Switching to a hybrid approach was a major change in our user to business recommendation system. In this blog, we documented our journey in developing this new approach and are glad to see big improvements. We plan to run several additional A/B experiments for push notification and email notification campaigns to confirm that these improvements translate to better user experiences. Given the current infrastructure, we feel more confident to try more complex models based on neural networks.
If you are inspired by recommender systems, please check out the careers page!
Acknowledgements
This blog was a team effort. I would like to thank Blake Larkin, Megan Li, Kayla Lee, Ting Yang, Thavidu Ranatunga, Eric Hernandez, Jonathan Budning, Kyle Chua, Steven Chu and Sanket Sharma for their review and suggestions. Special thanks to Parthasarathy Gopavarapu for working on generating text-based embeddings.
Become an ML Engineer at Yelp
Want to build state of the art machine learning systems at Yelp? Apply to become a Machine Learning Engineer today.
View Job