Fine-tuning AWS ASGs with Attribute Based Instance Selection

-
Ajay Pratap Singh, Site Reliability Engineer
- May 1, 2024
This is the next installment of our blog series on improving our autoscaling infrastructure. In the previous blog posts (Open-sourcing Clusterman, Recycling kubernetes nodes) we explained the architecture and inner-working of Clusterman. This time we are discussing how attribute based instance selection in the autoscaling group has helped us make our infrastructure more reliable and cost effective, while also decreasing the operation overhead. This will also cover how these changes enabled us to migrate from Clusterman to Karpenter. (Spoiler alert: Karpenter blog post is coming soon!)
Motivation
At Yelp we run most of our workload on AWS spot instances, and to manage the scaling capacity of these instances, we use AWS autoscaling groups (ASGs). ASGs are the collection of EC2 instance-types commonly grouped together for dynamic scaling and fleet management. These instance-types can be of a variety of characteristics.
We used AWS multiple instance selection for maintaining the list of instance-types that an ASG can use to launch instances. This AWS feature gave us flexibility to add mixed instance-types to fulfill the capacity required. These ASGs were dynamically maintained by Clusterman based on workload requirements. Clusterman scales-in or scales-out the workloads just by adjusting desired capacity in AWS autoscaling groups, which in-turn would launch or terminate instances. If AWS reclaims the spot instance (spot interruption) the instances would automatically get replaced by the ASG with similar EC2 instance capacity. In general, this Clusterman-ASG setup removed our overhead for launching and terminating EC2 instances.
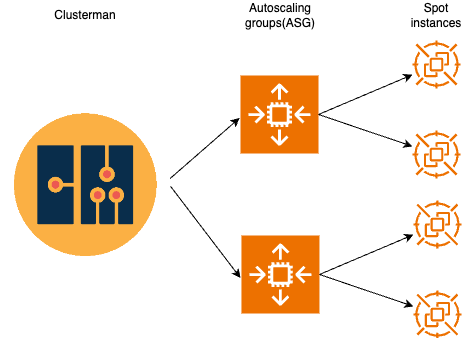
Clusterman and ASG
The main drawback of this setup was updating the list of EC2 instances as it was an operational overhead. Numerous times we found ourselves updating this list because of a change of requirements from the workload, reconfiguring the list for better cost balance, or even launching new EC2 instance-types. For addition or removal of each instance-type we had to update this in various places like ASGs through IaC (terraform), our kubernetes autoscaler (Clusterman), and some internal tools such as scripts for bootstrapping Kubernetes or scripts responsible for adjusting node ephemeral storage which had to be aware of instance-types.
The other motivation for switching to attribute based instance selection was having more instance-types eligible for selection by an AWS ASG. Often the AWS spot market runs out of capacity for certain instance-types, and if it happens to all of the instance-types in configured instance-requirements, the ASG would not be able to launch any instances.
Attribute Based Instance Selection
The secret weapon for fine-tuning our ASGs has been attribute based instance selection (ABS).This is an ASG feature which simplifies the instance-types selection. With ABS, instead of providing a list of instance-types, we have to specify the instance requirements in the form of attributes. For instance, the number of min/max CPUs or memory, instance generations, CPU manufacturer, etc. We can even allow or disallow whole instance-type families. Based on these requirements AWS will determine the list of eligible instances. The next time AWS has to launch an instance, it would look at the spot allocation strategy (described shortly) and this list to launch the instance.
Another big advantage of using ABS is how simple it is to use. Just by specifying instance attributes (requirements), ASGs will simplify instance-types selection when configuring a mixed instances group. By adding this abstraction layer in our scaling infrastructure it powered our workload owners to not worry again about finding the right instance-types for their workloads.
Using ABS is also future-proof, as it allows ASGs to automatically adopt newer and potentially more cost-effective or performant instance-types as they become available. Whenever AWS launches a newer generation instance-types, ASGs will start launching them if it matches the requirements.
A notable limitation we have observed in ABS usage is the inability to set the priority among different EC2 instance-types. While defining the list of mixed instance-types in an ASG with multiple instance selection(old method), we used to sort them in order of preference based on cost, type of workload it would run, and various other factors. When an ASG needs to launch an instance it would try to respect this preference. Some workloads necessitate a preferred EC2 instance-type, although it would be acceptable to run it in lesser preferred EC2 instance-types. Currently, there isn’t a way to define this hierarchy of preferences with ABS.
Spot allocation strategy
AWS picks which instance-type to launch by looking at the preferred strategy and capacity in the spot pool. There are multiple ways we can define our spot allocation strategy. While picking the strategy we have to balance the tradeoffs between cost and spot interruptions. The most common way to measure cost is cost-per-cpu. It gives the average cost of running a CPU across all instances. While using Spot Instances, AWS can reclaim them with 2 minutes of spot instance interruption notice. This can occur across any EC2 instance-types. The main reasons for these spot interruptions are when AWS runs out of capacity of a particular instance-type or the price of the spot exceeds the maximum price that you had requested for the spot instance.
The lowest-price strategy always picks the cheapest available instance-type, while the capacity-optimized strategy picks the instances which have the most spot capacity which lowers chances of spot interruption. The newest allocation strategy by AWS, price-capacity-optimized, brings the best of both worlds, it always tries to find the lowest cost instance-types which have high spot capacity.
To decide which strategy to pick, we ran an internal experiment where we configured these different strategies for the same duration in the same availability zone and compared the average spot interruption and cost-per-cpu. The capacity-optimized seemed to be the most expensive with 3.5% more cost than the lowest-cost. Whereas lowest-cost was slightly cheaper than price-capacity-optimized. In terms of spot interruptions, lowest-price had nearly 5 times more interruption rate than price-capacity-optimized. The above results were similar to what AWS got in this example. We end up picking the price-capacity-optimized strategy for most of our ASGs, to balance the cost and spot interruptions.
How ABS helped us
There were significant changes we had to make even before we could start using ABS. As mentioned earlier, we had quite a few scripts that had to be aware of instance-types-specific configurations. One such script was being used for expanding the ephemeral storage based on the instance size and number of CPUs the instance has. Earlier this was just a hardcoded configuration for each instance-type, we have now modified it to fetch this configuration on the runtime through AWS command line interface.
After enabling ABS, we have reduced the operation overhead significantly: now we don’t have to maintain the list of instance-types for our workloads. We just define the instance requirement of the workloads and the ASG will translate it to the list of eligible instances. After adding these requirements, we realized there were many instance-types that we could have been using. They were not necessarily better because spot market price and spot pool capacity varies very frequently, but it definitely helps to have them in the eligible list.
Another area where we anticipated seeing improvement was cost. In several clusters we saw a drop in the total cost. In one such cluster we were able to reduce the total cost of running the same set of workload up to 37%.
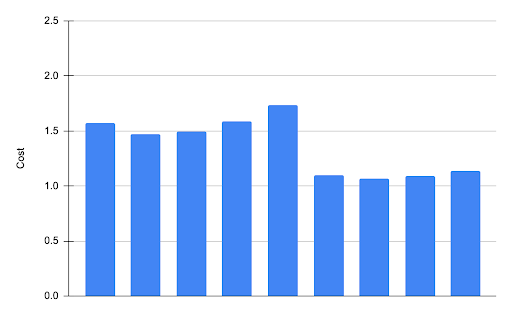
EC2 cost before and after migration
Upon investigating, we concluded that the cost reduction resulted from having more instance types available, and AWS was able to find cheaper spot instances for our workloads to run. Rolling out this change to other clusters also had a positive impact on costs, resulting in at least a 2-3% reduction.
One of the underrated benefits of this feature is how easy it has made configuring ASGs for selecting instance-types. All we have to know is the instance requirement of our workload, which helps a lot when you have hundreds of different instance-types to choose from. Having these easy to understand configurations helped us in our cluster autoscaler migration from our in-house Clusterman to Karpenter. Karpenter has a native way of accepting these instance requirements similar to what ASGs has. As we already had these configurations in-place, it made our Karpenter migration smoother.
Conclusion
Attribute-based instance selection in AWS Auto Scaling Groups is a game-changer, providing a dynamic and efficient way to optimize performance and reduce costs. This approach allowed us to select instances based on specific attributes and tailor resources to meet diverse workloads. The elimination of manual management of a fixed list of mixed instance-types streamlines operations has enhanced infrastructure adaptability. In essence, attribute-based instance selection in AWS ASGs empowered us to achieve a cost-efficient, agile, and responsive environment perfectly aligned with the evolving demands of our applications.
Making our instance requirements more generic also facilitated a smooth node autoscaler migration from Clusterman to Karpenter. The node autoscaler needs to be aware of the instance capacities and what instance it should launch to fulfill the requirements. This project eliminated any hardcoded instance-types specification from our infrastructure. Karpenter natively understands the instance requirements attributes similar to the ABS in autoscaling groups, which made instance selection rather easy. We shall explore more on our Karpenter journey in an upcoming blog.
Acknowledgments
I extend my heartfelt appreciation to all those who have contributed to the creation of this engineering blog post. Many thanks to Ilkin Mammadzada for insightful inputs and providing historical context during this project. Additionally, thanks to Matthew Mead-Briggs for their managerial support. I am grateful for the exchange of knowledge and the vibrant discussions that have enriched the content. This work reflects the collective efforts of a dynamic and inspiring engineering community.
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp, if you're interested apply!
View Job