dbt Generic Tests in Sessions Validation at Yelp

-
Tian, Yukang, Software Engineer
- Aug 14, 2024
Sessions, Where Everything Started
For the past few years, Yelp has been using dbt as one of the tools to develop data products that power data marts, which are one stop shops for high visibility dashboards pertaining to top level business metrics. One of the key data products that’s owned by my team, Clickstream Analytics, is the Sessions Data Mart. This product is our in-house solution to understand what consumers do during their session interaction with Yelp products and provide insights on top of it.
This blog post will walk you through how dbt is used as an important test and validation tool for helping enhance such an important data product at Yelp.
Using dbt For Sessions Data Validation
As the Sessions Data Mart grows and evolves, we often need to backfill the underlying tables following recent code changes. The newly backfilled data then must undergo tests and sanity checks using manual SQL queries to ensure data quality before proceeding with further iterations and announcing its availability to users.
Here are some of the challenges we encountered during the project before we adopted dbt as the data validation tool:
- It was difficult to keep track of various validation queries.
- Running similar queries in different data stores (e.g. Redshift, S3 + Athena) over and over again manually was tedious and prone to errors.
- Sharing query results from Athena/Redshift directly with the product and analyst community was difficult.
dbt generic tests is able to address all the above pain points by supporting:
- Persisting version-controlled test queries
- Customizable queries which allow users to pass different variables
- Running queries across different data stores (e.g., Redshift, S3 + Athena)
- Persisting and querying test results with minimal manual intervention
- Easily sharing queries and results with product and analyst community
Since we’ve already used dbt to build the Sessions Data Mart, incorporating it into our data validation is cost-effective and the knowledge can be easily shared across all teams that use dbt.
Sessions Data Development Cycle
We’ll be focusing on a key component of the Sessions Data Mart: the sessions_table, which sits in the center of the data mart. Each row of this table represents individual sessions, with columns storing metadata such as the session start time, as well as fields like geo location, platform name, etc.
This table has become a critical upstream data source at Yelp, with numerous dependencies. We will use it as an example to explain our Sessions data development dev cycle before diving into the details of the validation process.
In this example, we’re adding a new column, product_name, to the table to enable users to analyze whether a session on Yelp is related to a business or consumer product.
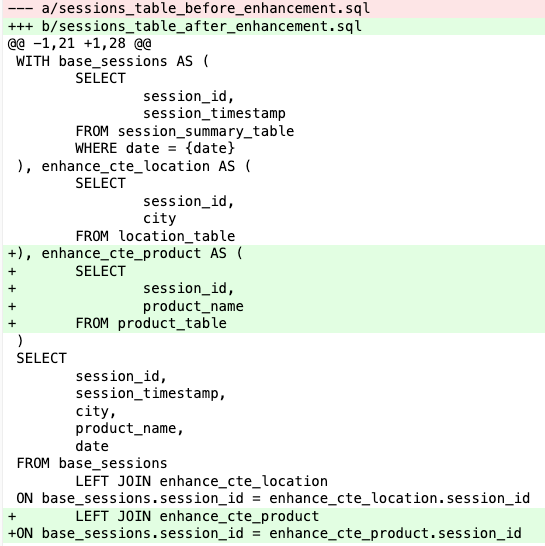
As shown in the above code change, the core development work for this table involves identifying the necessary new columns and updating the model definition to include them by joining with other tables that contain these columns. As development progresses, the query will expand to include an increasing number of CTEs (Common Table Expressions) and left joins, along with the essential processing logic for those CTEs.
In an ideal world:
- We have a crystal-clear vision of the final query.
- There is no need for historical data backfill.
- Our data is clean and explainable across all historical records and source tables.
- The dbt job runs without any human or program errors.
Under these conditions, development work should be quite easy, given that this whole model is built based on 16 left joins, in our case. The development workflow in such an ideal world would look like this:

Unfortunately, such an amazing world is nothing more than a developer’s fantasy in the data domain. Here’s what the actual development cycle looks like:
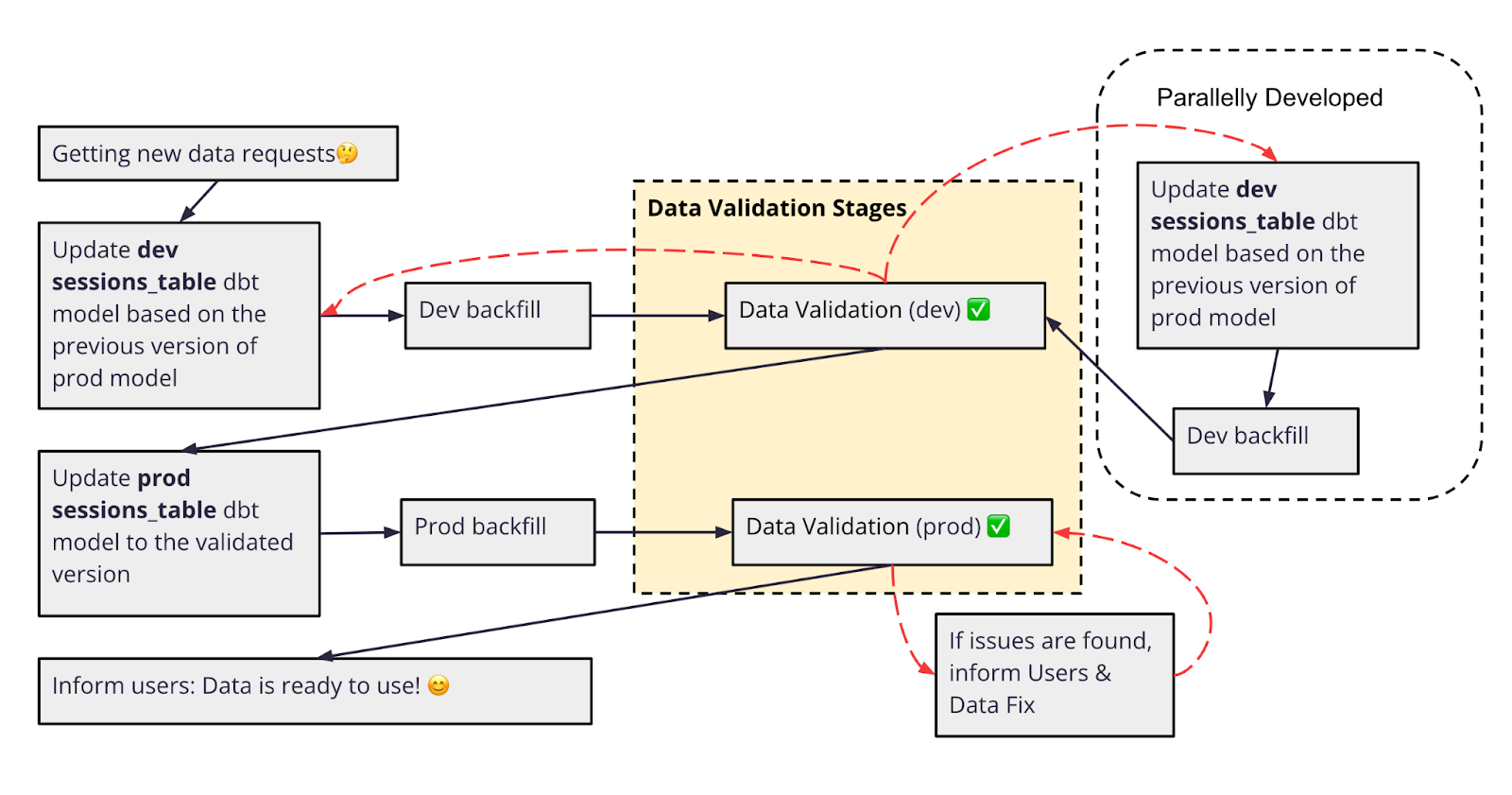
This development cycle allows us to:
- Start enhancing the table with new columns while other parts of the query are being worked on, so downstream users can start to use part of the new columns without waiting for all things to be done.
- Allow for parallel development and validation of additions or changes to the model.
- Receive fast feedback from the backfilled data without affecting the production data.
This approach enables us to divide and conquer, thereby increasing the speed of the iteration while ensuring data is delivered as soon as it is ready to use in production.
We grouped and categorized the tests, implementing them using dbt generic tests. We refer to the stages where these tests are executed as the Data Validation Stages.
An Example of Data Validation
dbt generic tests are predefined, reusable tests applied to data models to ensure data quality and integrity. They automate the validation process, making it easier to maintain high data standards across multiple models without extensive manual effort.
There are some packages like dbt-expectations that allow us to build the tests easily for many common use cases. Alternatively, you can build tests from scratch to customize them further with maximum flexibility.
Let’s take a look at a simplified example to understand how a user-defined dbt generic test is used for sessions_table. The example below shows how the test is configured in the sessions_table model config file.
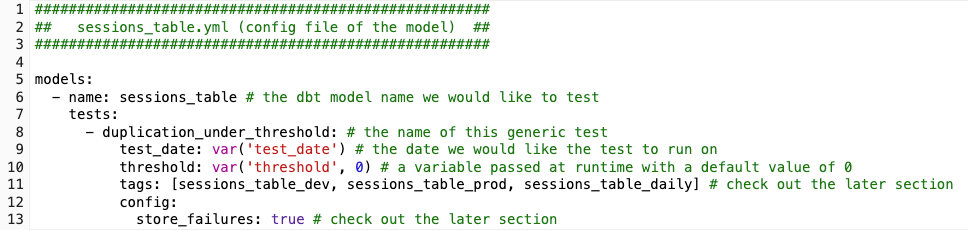
Once you have your test macro and config ready, the command below is all you need to trigger the tests that relate to this model. In this example, we only have one test associated with the model, so only this one test will be triggered.
dbt test -m sessions_table --vars "{test_date: 2023-01-01}"
This is how the test is actually defined.
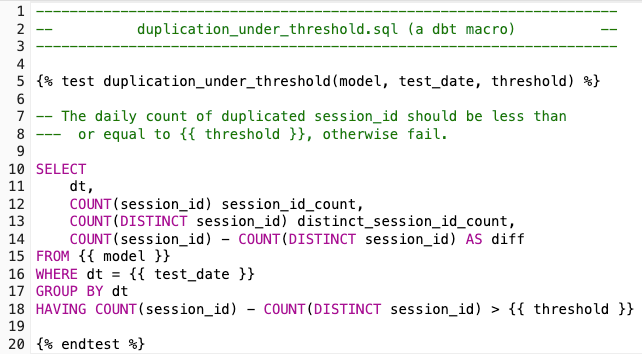
For any day the test duplication_under_threshold passes on, we would be pretty confident that the daily sessions_id duplications should be lower than the threshold we specified.
In general, dbt generic tests are highly customizable because they leverage the dbt macro that supports Jinja. This allows for the implementation of more complicated tests and provides scalability for use across multiple models and more complicated use cases.
Categorizing Tests Using Tags
dbt allows us to manage and organize our tests effectively using tags. By tagging tests, we can easily run all tests with the same tag together. This is useful for testing different things at different stages or for separating tests for other reasons.
In our sessions data development cycle, we categorized our validation stages into three different types based on our needs, which is why we see three tags in the config file.
Data validation for development
dbt test -m sessions_table --tag:sessions_table_dev --vars "{test_date: 2023-01-01}"
These tests are triggered by developers while changes are actively being made for evolving the dev model. Some time-cost tests can be put here, since they can finish in a reasonable amount of time given that the size of the data at this stage is typically small.
We proceed to backfill all production data only after the data validation for development has passed.
Data validation for production
dbt test -m sessions_table --tag:sessions_table_prod --vars "{test_date: 2023-01-01}"
These tests are triggered by developers manually for all historical prod data, which is normally years of data.
We announce the completion of data evolution and the general availability of the changes we made only after the data validation for production has passed.
Data validation for daily run
dbt test -m sessions_table --tag:sessions_table_daily --vars "{test_date: 2023-01-01}"
These tests are triggered after the daily batch job that generates sessions_table runs, to make sure we catch any issues immediately after the data for that day is generated.
Storing Test Failures
Running the tests is not always the last step of the validation stage, especially when we have multiple tests serving different purposes. It’s impossible for us to identify what went wrong at a first glance of the validation results and fix them immediately. Thus we have to store them somewhere for further debugging or for sharing results across teams to craft a debug plan without rerunning the tests.
store_failures allows us to persist the results of failed tests in the data store where this test is triggered (S3 in our case), which makes retrieving test results possible and efficient.
Acknowledgements
I would like to thank Regine Fan, Sudhakar Duraiswamy, Kritika Somani, Neelima Bhattiprolu and Krishna Pidaparthi for their valuable feedback on this post. Special thanks to Bryan Marty, Keegan Parker, James Coles-Nash and Eric Hernandez for their thorough reviews and insightful comments. Your contributions have greatly improved the quality of this work.
Appendix
When should I run my tests? | dbt Developer Hub
Writing custom generic data tests | dbt Developer Hub
Become a Software Engineer at Yelp
Want to help us make even better tools for our full stack engineers?
View Job