Building Biz Ask Anything: From Prototype to Product

-
Maria Christoforaki, Group Tech Lead; Shree Shalini Pusapati, Software Engineer
- Mar 27, 2026
Introduction
Users have access to a wealth of information on Yelp business pages – from reviews and photos to structured information, menus, and Ask the Community feature on the business page, a single business page can be an ocean of content. At the same time, user expectations have evolved: people now expect immediate, direct answers. Sifting through dozens of reviews to find a simple fact can be time-consuming. Fortunately, advances in Large Language Models (LLMs) have given us a new set of tools, allowing us to tackle information retrieval and summarization tasks that were prohibitively complex just a few years ago.
Finding an Answer in an Ocean of Content
The core user need in this context is simple: when people have a specific question, they want a straight answer. When a user asks, “Is the patio heated?” or “Is this place good for kids?” they often don’t want to hunt through dozens of reviews, photos, and structured business information (e.g., hours, location, amenities, etc). That kind of fact-finding can be time-consuming, especially if you’re on the go. At the same time, many users still enjoy exploring long-form reviews and rich, detailed content–and that depth remains a key Yelp advantage. Our goal is to support both behaviors, using AI to surface direct answers while preserving the value of in-depth reviews.
We first introduced Yelp Assistant, our AI-powered chatbot, in 2024 to help consumers diagnose service needs and easily connect with service pros. That first version did not know how to answer business-level questions as it focused only on identifying businesses that can solve a user’s problem. Therefore, and to address the data abundance challenge, we recently introduced Yelp Assistant on business pages—our solution to give users one simple, evidence-backed answer to their specific questions.
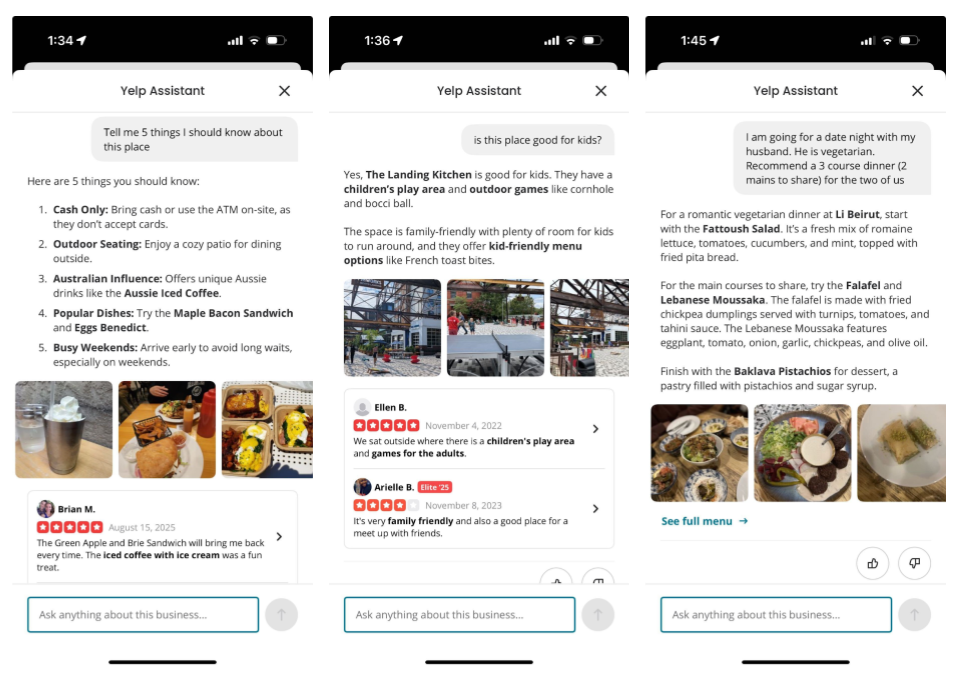
Figure 1. Biz Ask Anything
In Figure 1, on the left, we have the “Tell 5 things I should know about this place” question which asks Yelp Assistant to identify the five most important or interesting things that a new visitor should be aware of when deciding whether to visit.
In the middle, we have a more targeted question asking whether the business is “good for kids?” In this case Yelp Assistant has to give a straight yes or no and explain why.
Finally, on the right, is an example of a complex question asking Yelp Assistant to recommend a three-course dinner with two mains for two people, where one of them is vegetarian. Yelp Assistant has to consider the requirements and compose a recommendation that fits the use case.
In all these cases, Yelp Assistant has to understand the question, retrieve the right content, and compose an answer—fast. In the next section, we outline the high-level steps involved in answering real-world questions. Then, we zoom into the systems and challenges behind making this work at scale.
The Life of a Question
To deliver that simple answer, a user’s question goes on a complex journey in just a few seconds. Here’s a high-level look at the life of a question in our system:
- Conversation Context: The user sends a question, which is augmented with any recent chat history for that user–business pair (if available).
- Question Analysis: The system classifies the question for safety and intent, chooses the right data sources (e.g., reviews, business information, or both), and generates retrieval hints or keywords.
- Retrieval: We search our near-real-time (NRT) indices (reviews, photos, websites) and fetch structured facts from our databases when relevant.
- Answer Generation: A prompt is composed with the retrieved evidence. The LLM uses the prompt to synthesize a concise answer, complete with citations.
- Answer Augmentation: The system attaches relevant visuals (such as photos) to support the answer.
- Delivery: The answer is streamed token-by-token to the UI, while traces and metrics are logged for monitoring.
The generated answers, along with the intermediate steps, are logged, processed, sampled, and evaluated as feedback on the quality of the system and used for iterative improvements.
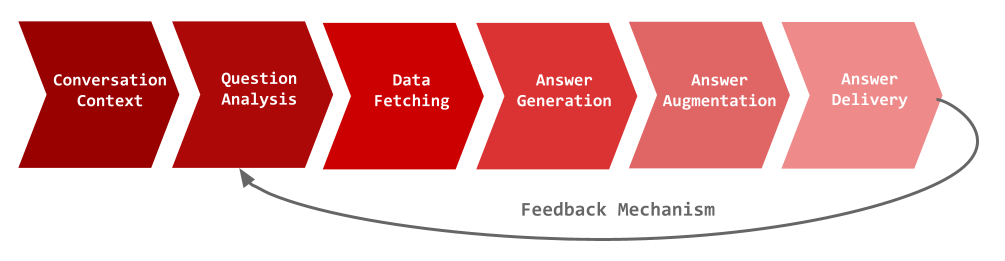
Figure 2. BAA Overview
While the high-level shape of this system looks similar to the first prototype we built, the guts are entirely new. We evolved from scrappy prompts, simple scripts and ad-hoc data to a robust system of near-real-time data services, fine-tuned models, automated quality evaluation, comprehensive guardrails, response streaming, and many versions of increasingly sophisticated prompts.
Challenges on Our Way to Production
We first introduced Yelp Assistant, our AI-powered chatbot, in 2024 to help consumers diagnose service needs and easily connect with service pros. In this session, we’ll detail how we built the next evolution of Yelp Assistant, transforming it from a two-week proof of concept, into a full-scale production-ready system over nine months.
The Data Problem — Scalable, Fresh, Searchable
Our prototype ran on ad hoc batches for a small set of popular businesses: data warehouse dumps loaded into a Redis snapshot. Great for demos; a dead end for production. Product requirements were clear: near-real-time freshness, high QPS, sub-100ms reads, and reliable text/hybrid search at scale.
What we built
- Search (NRT): Three near-real-time indices for a) reviews, b) photos and photo embeddings, and c) website/menu content and Ask the Community feature on the business page. Reviews and photos are large and metadata-rich, so each review and each photo is a document.
- Structured facts: A Cassandra store with an EAV (Entity-Attribute-Value) schema for business structured information. In particular a
(business_id, field_name, field_group, value, update_ts)table. - Ingestion:
- Streaming from source-of-truth databases (SoT) → joins/transforms → data pipeline → Cassandra and NRT indexers.
- Weekly batches for websites, menus, and Ask the Community business page feature → data pipeline → NRT.
- Retrieval: For relevant content retrieval, we rely mostly on keyword search except for photo retrieval, where we leverage a combination of embedding similarity and photo-caption text.
- One API: A content-fetching engine that returns “all” or “selected sources” for a business in an LLM-friendly shape. In under 100 ms (p95)
- Recovery and correctness: When ingestion issues surface (e.g., bad joins or transforms), we replay streams from the point of failure; some datasets are derived from chains of 3–4 streams, so replayability and idempotent upserts are required.
Freshness at a glance
- Reviews & photo captions: near-real-time < 10 min (streamed from SoT)
- Business structured information: near-real-time < 10 min (streamed from SoT)
- Websites, menus, Ask the Community on business page: weekly batches
This replaces static snapshots with a fresh, observable data layer: fast reads, clear source boundaries, and a single interface that downstream components can rely on.
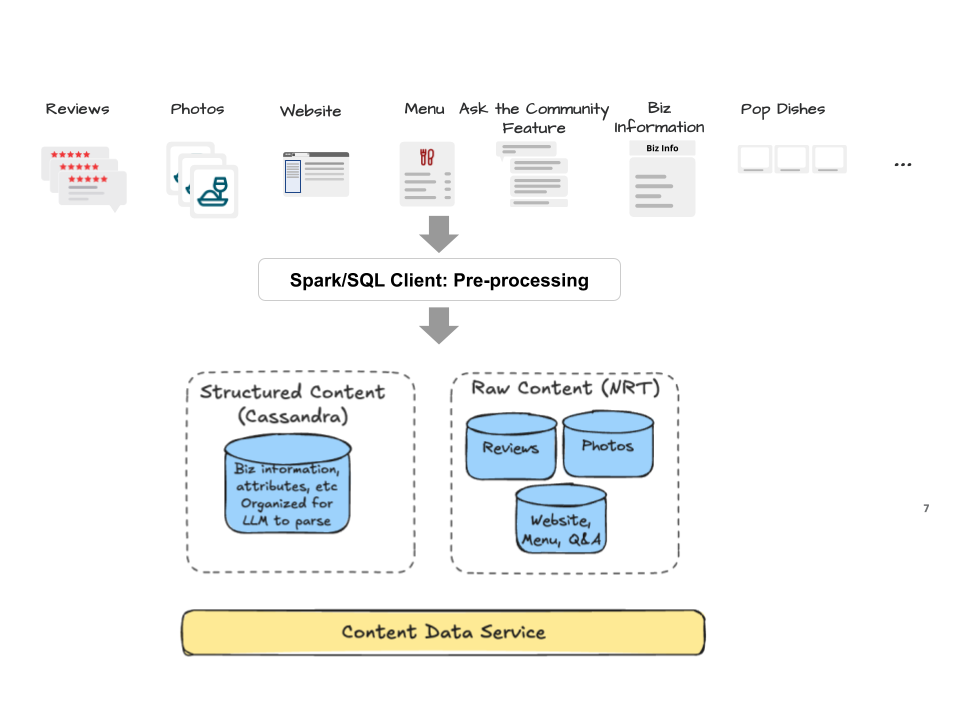
Figure 3. Data Ingestion & Indexing
Key Learnings:
- Sacrificing strict schema was acceptable: Because the data is consumed by an LLM that already expects unstructured strings. EAV was practical for our use case with frequently changing fields: A (business_id, field_name, field_group, value, updated_at) table lets us add new attributes without schema changes and keeps ingestion jobs isolated.
- Stream where staleness is noticed; batch the rest: Because stream debugging is cumbersome, we limited streaming to reviews, photos, and business properties where freshness is key, and kept websites/Ask the Community business page feature on weekly batches.
- One content-fetch API helps everyone: A single interface that returns “all” or selected sources in an LLM-friendly shape reduces coupling. It’s an abstraction that helps other business-centric LLM applications besides ours.
- Keyword-first was the right v1: With existing IR/ranking, keyword search plus an LLM expansion step hit quality targets faster than standing up an online embeddings stack and tuning similarity thresholds + embeddings alone failed to rank well in a lot of “specific intent” scenarios. Known trade-off: ~0.8s added by keyword expansion and our recall is weaker on non-specific user questions. Keyword got us to launch; chunking + embeddings are useful for less “keywordy” questions and for removing the blocking expansion call. We treat them as complementary and are investing in embeddings as a followup.
- Store data in the shape you read it: Putting data together before reading avoids large fan-outs, hot-path joins and other reliability issues.
Deconstructing the Question — Intent, Safety, and Retrieval
Before we fetch any content to answer a user’s question we first decide what the user is really asking, whether we should answer at all, and what content is appropriate to consult. Doing this upfront keeps users safe, protects businesses, reduces hallucinations, lowers costs, and makes the final answer more helpful.
When we built our first prototype for internal consumption we didn’t assume unsafe questions, or people not knowing what our application cannot do. When exposing such a product to real-traffic one has to anticipate that users may try to mis-use it and that users will ask questions that it is not built to answer and shouldn’t attempt to answer.
Trust & Safety
When testing our chat bot internally and on questions from real consumers posted to the Ask the Community feature on Yelp business pages, we found various questions that we should avoid answering. Therefore we built a Trust & Safety (T&S) classifier that sits in front of our chat bot. Our classifier assigns one (or more) labels to the question. For each of the questions, when flagged as unsafe, we return templated, safe answers and encourage users to focus on asking questions about the business services or offerings. Examples of unsafe questions include system attacks (e.g. attempts to override instructions), questions that could be tied to illegal activity (e.g. requests to plan illegal acts) etc.
We fine-tuned GPT-4.1-nano on a data set of a few thousands of questions-label pairs. The data set also includes ~50% of questions that should be considered legitimate and was generated by a combination of manually crafted question-labels that we used for seeding LLM generated question variations.
The majority of our time was spent on crafting examples that could be considered ambiguous or borderline until we reached a precision-recall sweetspot.
Inquiry Type Classification
In our first internal prototype, we implicitly assumed users would ask the “right” questions—i.e., things a single business page can answer from its Yelp content. That worked in demos. In real traffic, people ask for recommendations, account help, or general knowledge—things our bot wasn’t built (or allowed) to answer.
Why we can’t “just answer” everything that looks reasonable Even when a question sounds harmless, answering it with a general-purpose LLM invites two problems:
- Scope drift: The model will cheerfully answer using its own prior knowledge instead of the business’s Yelp content. This nudges users to ask more out-of-scope questions, and we lose control over answer quality because it’s no longer grounded in our vetted sources.
- Hallucinations: When the model lacks (or only partially has) relevant knowledge, it still tends to produce a confident answer—filling gaps with fabricated details rather than deferring or asking for clarification.
- Cost & latency: Fetching evidence and generating a full answer for out-of-scope questions wastes tokens and time.
We added an Inquiry Type classifier that runs in parallel with Trust & Safety. If T&S rejects, we cancel the rest of the pipeline (including inquiry typing). Otherwise, this classifier decides whether the question is in-scope for a single business, content-grounded answer. It returns a label that drives the next step or redirects.
Examples from real behavior
- “Show me good plumbers.” → Explains the bot can’t help with general recommendations + redirects to Yelp’s search.
- “How do I change my password?” → Graceful decline + redirects to Yelp’s support page
- “Is there god?” → Graceful decline + guidance on business-specific questions we can answer.
Similarly to trust and safety we built our model by fine-tuning GPT-4.1-nano with ~7K samples. We used real and synthetic questions to ensure the model sees multiple variations of the same question and doesn’t overfit a particular style. We spent a lot of time mining logs from smaller launches to discover new inquiry types that we hadn’t discovered before and re-fine tune for new classes.
Content Selection for Answering
In the prototype, we fed the model everything we had for a business - menus, Ask the Community feature on the business page, hours, amenities, owner descriptions. That worked in demos, but in production it caused predictable issues:
- Irrelevance overload: Menus don’t help an ambiance question; hours don’t help with “popular cocktails”; reviews talking about the business “ambiance” don’t help with vegan dishes questions. The more irrelevant information, the more likely the LLM will not find the right answer.
- Source hygiene: Some questions should lean on community signals (e.g., reviews, photos or the Ask the Community business page feature) rather than owner-authored sources; others (prices, hours) should prefer canonical sources like menus.
- Cost & latency: Massive prompts increased tokens and slowed responses without improving quality.
Initially we used a single LLM pass to (a) pick sources and (b) generate search terms but eventually split into two more lightweight fine-tuned models. Decoupling the two tasks lets us tune failure modes independently and debug decisions in isolation while optimizing for low latency.
Content Source Selection
Given the user’s question, conversation history, and the catalog of available sources for that business, the selector returns the subset of sources we should consult, balancing topical relevance with the right subjectivity/objectivity profile for the question.
Keyword Generation
Using the question, conversation history, and business context (name, categories, location), the generator emits a compact list of search terms/phrases to pull the right chunks of text from the chosen sources. Business context steers synonyms toward what users mean in that vertical. Take the question: “Do they have vegan options?”
- Hair salon: animal-free, cruelty-free, plant-based, vegan shampoo, vegan conditioner, vegan styling, vegan products, vegan hair dye, …
- Mexican restaurant: vegan, bean burrito, vegan tacos, dairy-free, cauliflower, beans, cactus, nopales, enchiladas verdes, tacos de pappa, vegetarian, …
When keywording is skipped For generic prompts like “What should I know about this place?”, keywording adds noise. The generator is tuned to return no keywords in such cases; we then fetch recent reviews/photos from the selected sources without term constraints.
Precision/recall trade-off The core challenge was avoiding keywords that are too vague (match everything) or too specific (match nothing). We iterated on prompts and fine-tunes to hit a sweet spot that yields diverse but tight evidence sets. We started with keyword retrieval due to mature text-search backends and ranking expertise; we’re now investing in embeddings-based retrieval for fuzzier intents (e.g., “What’s the ambiance here?”), which we’ll cover in a separate post.
Question Analysis Overview
Below is a diagram of the full question analysis phase. Content Source Selection and Keyword Generation run in parallel with Trust & Safety and Inquiry Type. If either classifier says “don’t answer,” we cancel content work immediately and return a safe, helpful redirect.
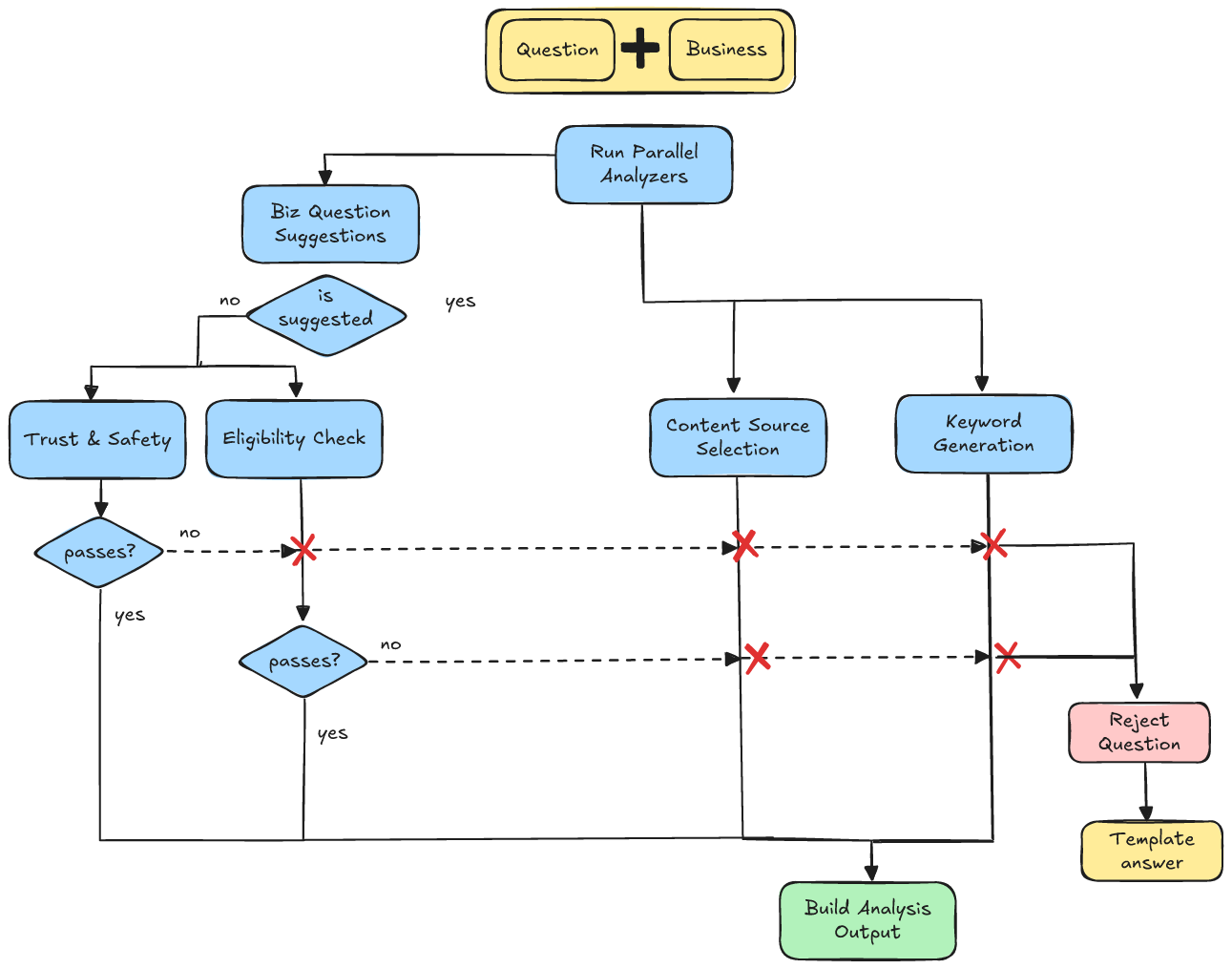
Figure 4. Question Analysis
Key Learnings:
- People ask everything: Real traffic surfaced intents we didn’t expect. Questions from the Ask the Community feature on the business page, small internal launches, phased rollouts, and good logging/analytics helped us expand labels and iterate quickly.
- Model choice vs. budget: Large models did well with minimal prompting, but didn’t meet latency goals. Fine-tuning a small model worked, but required more care in data and prompts.
- Fine-tuning data quality matters most: Early fine-tunes overfit our wording. We improved by:
- Using realistic seeds (Questions from Ask the Community feature on the business page, early traffic failures), not only synthetic data.
- Adding paraphrase variety and edge cases across intents.
- Including conversation context so outputs adapt to prior turns.
- Keep prompts minimal: Smaller models were sensitive to prompt bloat. Short schemas and concise instructions were more stable and faster.
- Split and parallelize tasks that look similar: “Pick sources + generate keywords” in one pass underperformed. Splitting into two small models improved precision and made failures easier to debug and lowered latency.
- Labels keep changing: As usage shifts, new behaviors appear. We treat T&S and Inquiry Type as live label taxonomies and periodically add/update labels.
Answer Quality — Accuracy, Helpfulness and Voice
Our prototype “looked smart” at a glance. However, even when correct, the responses often weren’t helpful—they might be wordy and vague, failing to provide a direct action or a useful alternative. Finally, the tone didn’t match our brand, veering between overly stiff and overly formal.
| Criterion | ❌ BEFORE: Prototype Issues | ✅ AFTER: Improved | 💡 Key Improvements |
|---|---|---|---|
| Correctness/ Faithfulness | Q: "Best hikes for 3-5 year old kids?" |
|
|
| "The Lower Yosemite Fall Trail is a short, easy walk... The Cook's Meadow Loop is another gentle trail... Additionally, the Mirror Lake Trail is relatively flat and offers a scenic walk." | For 3-5 year olds, consider the Lower Yosemite Falls Trail and Glacier Point Trail. Both are short, paved, and suitable for young children. The Lower Yosemite Falls Trail is 1.2 miles and takes about 25 minutes, while the Glacier Point Trail is 0.5 miles and takes around 12 minutes. |
||
| Evidence Relevance | Q: Tell me about their menu, pricing, variety, veggie options, etc. |
|
|
| Gary Danko offers a customizable menu with options for 3, 4, or 5 courses, priced at approximately $81, $99, and $117 respectively. The menu includes a variety of dishes across categories such as appetizers, seafood, meat, cheese, and dessert. Supporting evidence: From review 260003628: The price for 4 courses is about $140 each so be prepared. |
Restaurant Gary Danko offers a flexible prix-fixe menu where you can choose 3, 4, or 5 courses, priced at 150, and 170 respectively. The menu includes a variety of options such as seafood, beef, and duck, with wine pairings available. Vegetarian options are available, though they may be limited. Some vegetarian dishes include Potato Gnocchi with Stilton Blue Cheese and Soy Marinated Tofu Scallops. |
||
| Completeness | Q: Do they have massages for muscle pain and what's the cost? |
|
|
| Yes, A Beautiful Day Spa offers massages for muscle pains. | A Beautiful Day Spa offers several massage options that can help with muscle pain, including sage, Swedish massage, and hot stone massage. The cost for a 60-minute massage is typically around $55, with options to extend the session to 90 minutes or 2 hours based on availability. They also offer a cash discount. | ||
| Conciseness | Q: I am vegan. Will I have any options here? |
|
|
| El Vez offers limited vegan options, but there are still a few choices available for you. While the restaurant primarily focuses on Mexican cuisine, which often includes meat and dairy, they do have some vegan-friendly dishes. For instance, the vegan burrito is available on the brunch menu, and you can also enjoy a variety of guacamole and chips. However, it's important to note that the menu may not clearly label vegan options in person, so it might be helpful to ask the staff for guidance when ordering. Additionally, the restaurant's online menu might list more vegan options than what is available in person, so it's advisable to confirm with the staff during your visit. | Yes, El Vez offers several vegan options. You can enjoy the Tofu al Pastor Vegan Burrito, black bean enchiladas, and cauliflower tacos. They also have a variety of veggie options that don't rely on cauliflower or tofu, like the black bean tlayuda. |
||
We realized we had to treat answer quality as a multi-dimensional problem, focusing on 5 main pillars:
- Correctness/Accuracy: Is the answer factually accurate and grounded in the provided context?
- Completeness/Helpfulness: Does this directly answer the user’s question? Does it provide actionable information or helpful alternatives if a direct answer isn’t available?
- Evidence Relevance/Trustworthiness: Is it well supported by evidence that is presented to the user?
- Conciseness: Is the answer short, skimmable and contains only useful info?
- Structure: Is the answer easy to digest?
- Tone: Does it sound like our brand?
Quality Graders
For the first 3 criteria we clearly defined each criterion, and a handful of labels for each criterion and produced gold data for each criterion and grade to build consensus and have a point of reference. We then manually labeled hundreds of answers with respect to each criterion. We used the labels to tune “LLM as a judge” graders; one per criterion.
- Correctness Grader: Takes the user question, optional prior context, and all available business content. It outputs a correctness label plus a short explanation with supporting quotes. Labels are:
- CORRECT if the answer is fully supported
- UNVERIFIABLE if it’s not supported but also not contradicted
- INCORRECT if the content contradicts the answer.
- Completeness Grader: Takes the question, prior conversation (if any), and the answer. It evaluates how well the answer addresses the question. Labels are:
- SUFFICIENT if the question is fully answered
- NEEDS_FOLLOW_UP if it’s only partially answered or needs clarification
- REFUSE_UNABLE if the answer says it can’t or won’t answer
- OFF_TOPIC if the answer doesn’t actually address the question.
- Evidence Relevance Grader: Takes the question, prior history, the answer, and cited evidence (reviews, photos, other sources). It measures how well the evidence supports the answer. Labels are:
- RELEVANT if all evidence is on-topic and every answer point is supported
- PARTIALLY_RELEVANT if some answer points lack support or some evidence is off-topic
- NOT_RELEVANT if the answer isn’t supported by the evidence at all.
Quality iterations
Before launching externally simulated questions by using our community question threads and synthetic questions, we run these graders when doing major prompt iterations to ensure we got the improvements we needed while not breaking expected good behavior. Once we started exposing the feature to real traffic we could sample real user conversations and run it on actual traffic.
Prod Metrics
Prod metrics are calculated by computing a running average against previous runs on a daily basis. This ensures that our quality analysis is not biased to any specific types of questions. In addition to that, it tells us whether our system has degraded over time. Degradations could be caused either by different user behavior or by changes we made to the system.
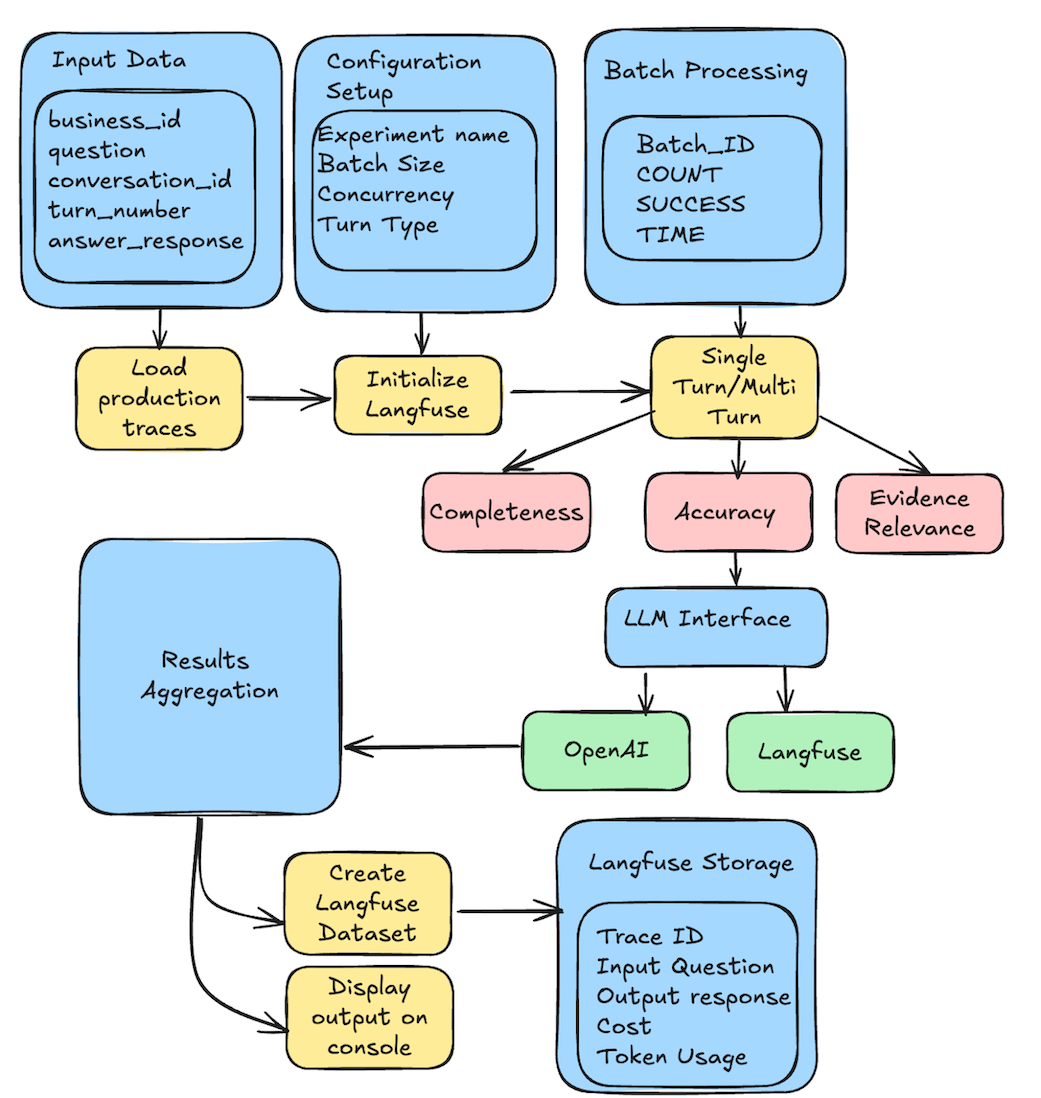
Figure 5. BAA Quality Assessment
The Langfuse-based grader is an automated evaluation system for Question/Answer pairs that uses LLMs to assess answer quality. It provides comprehensive observability, cost tracking, and experiment management through Langfuse integration, enabling detailed insights into evaluation performance and quality metrics. In production we handle this by extracting the logs for each question answering call and passing it to the langfuse based grader. This runs as a batch daily and generates statistics which are stored as a dataset on langfuse.
Style & Tone
We co-designed the ideal tone and structure with our Design and Marketing teams. They also worked with the first version of the Yelp Assistant. However, the types of tasks in the services-problem diagnosis space and answering questions about a particular business differ substantially, so it was almost like starting from scratch. We incorporated the derived principles along with a diverse set of curated few-shot examples into the prompt. In a nutshell, keep answers short, skimmable, and in simple language; always cite sources. We have dozens of versions of prompts and few-shot examples that we continuously adjust based on internal and external feedback, and spot checking real traffic for edge-cases that we don’t handle as we would like to. Initially, we attempted to assign Style & Tone evaluation to an LLM-as-judge but we quickly found that this is a lot harder than the more objective tasks of correctness, answer completeness, and evidence relevance evaluations. Our Style & Tone rules a) are more complex and dynamic as we discover new “use-cases”, and b) they are a lot harder to put into crisp rules that fit in an LLM prompt. Since we also have found updates in the pipeline are affecting style and tone less than our other evaluation metrics we deferred scaling our tone & style automation for later.
Learnings:
- “Quality” is a product spec, not just a feeling. All components of quality have to be defined clearly, and put into examples.
- Examples can be a lot more powerful than rules.
- Automated evaluations are key for quick quality improvement iterations.
- LLM judging style and tone is a much harder task than correctness, or answer completeness. However, it is a challenge we plan to invest in in the near future.
- Iterating on quality (tone, succinctness, edge cases) led to a massive, unmanageable prompt that we are moving into a dynamic prompt composition.
Performance — Time-to-First-Token is Crucial
We’ve made significant strides to achieve high-quality responses and response time. While our initial prototype demonstrated decent answer quality, its responses often lagged at 10–20 seconds. To achieve an optimal product experience, we set an external launch target of a p75 latency of 5 seconds for the backend LLM service. Thanks to extensive architectural and technical improvements, we have significantly surpassed that goal, achieving a current p75 latency to be less than 3 seconds.
Getting there required a multi-front approach: implementing streaming responses , using those fine-tuned fast models for Question Analysis, aggressive retrieval tuning and caching, and constant waterfall profiling to find and remove the next slowest block.
Hardest Problems & Learnings:
- Data fetching latency: Data is distributed across different resources in multiple tables/clusters
- Asynchronous client: We built multiple asynchronous clients within the data fetching service that can run Lucene and CQL queries in parallel to our Cassandra and NRTSearch (Elasticsearch equivalent) datastores.
- Question Answering Completion Time: The question answer LLM needed to wait for completion before sending a response to the user. This would mean the user would be waiting > 10s in the worst case for a response. This proved to be a Multi-faceted problem.
- Streaming was the biggest win: By streaming the response from the LLM we have very low latency for the TTFB (Time to first Byte). This was facilitated by migrating from pyramid to a fastapi server that supports sse (Server side events).
- LLMs priority tier: We also moved our LLMs to run on the priority tier on OpenAI which increased our inference speed by close to 20%.
- Question Analysis Completion Time: The question analysis LLMs needed to wait for completion before we ran the question answering pipeline.
- Asynchronous Pipeline: We built the question analysis agents as asynchronous chains invoked through langchain, which meant that they can run in parallel and we just need to wait for the longest agent to complete. We also added early stopping to the components in the pipeline when the trust and safety classifier rejects the question to avoid waiting longer before responding.
- Fine tuned models: We fine-tuned smaller models using carefully curated training data generated from larger reasoning models to help with cost reduction for the question analysis phase. This in turn also helped us with the latency aspect as nano had quicker inference times compared to larger models.
Cost - Every token counts
The prototype was also far too expensive per question to be viable. It used expensive models, didn’t optimize input token size and didn’t have any early rejection installed. Using fine-tuned smaller models for the analysis pipeline was a massive win. We also invested in aggressively shrinking our context windows by intelligently selecting only content that we think is necessary to answer the question that brought the cost down to 25% of the original cost.
Hardest Problems & Learnings:
- Question Answering Cost Optimizations: The question answering model on the other hand had a difficult tradeoff. Complex questions require nuanced synthesis across multiple pieces of evidence, citation accuracy, and consistent tone—tasks where smaller models struggled despite extensive fine-tuning.
- Quick iteration with cheaper models: We instead chose to migrate to a newer OpenAI model, which produced the same quality of results with less cost and negligible effort. We were able to quickly iterate and deploy this system as we built a quality grader that ensures we are not reducing quality while making cost optimizations.
- Reducing Input Tokens:
- Keyword Snippet Extraction: A combination of Ahocorasick + sliding window was used for snippet extraction. This algorithm uses keywords generated during the keyword generation process, which helped with reducing the size of the input user prompt.
- Biz Content Cleanup: To reduce the input token size we also made data optimizations, by cleaning up and reducing the size of our website/menu data as we found websites and reviews to be the largest contributors to the user prompt size. This resulted in some small improvements to the cost of the LLM calls but not a substantial amount.
- As we were iterating we significantly increased system prompt size which “overwrote” some of our savings from the smarter data selection, so we went with this approach to solve it:
- Dynamic prompt composition**: Instead of one massive system prompt, we’re building a prompt assembly system that includes only the instructions, examples, and constraints relevant to the detected question type and content sources. For example, the menu-focused question doesn’t need our full 20-example guide on handling ambiance queries. This information is extracted by semantically searching across our few shot examples to construct system prompts only with the examples that are relevant.
User Education — “What Can I Even Ask?”
The prototype was a blank chat box and a problem as users would not always know what and how to ask.
Initially, we used an LLM to generate generic questions at a business category level. So, Mexican restaurants, Bars, Parks, each had their own suggestion list. This approach occasionally produced questions that were unanswerable with the available data for the particular business.

Figure 6. Suggested Questions
Therefore, we invested in generating suggestions from the business’s actual content. To reduce cost, we used a handful of recent reviews, a summary that we have generated for every business, as well as the business owner’s description (instead of using the full content). This surfaces what people really care about and talk about that specific place. In the image above you can see an example of suggested questions for Parc. On the left, the suggested questions are not bad, but are generic given that this is a French, breakfast & brunch place. However, this restaurant is known for its freshly baked bread basket that is offered complementary to customers so the question “Can you order freshly baked bread to go?” is a lot more relevant and insightful to this particular business than a generic breakfast options question. For businesses with limited content (e.g. new businesses) the questions tend to be more generic but will adjust as content increased on the business page over time.
After several waves of wording and format tweaks, this content-driven approach led to a ~50% lift in engagement with suggested questions and a ~26% drop in inability to answer rate for suggested questions.
Next, we will be incorporating user engagement signals to adjust the suggested question ranking and invest in short-term caching of suggested question answers to improve the user experience with faster answers and cost reduction.
Conclusion
We started this journey with a quick prototype that promised a new way to get information. We ended with a complete production system spanning real-time data pipelines, multiple fine-tuned models, dozens of versions of prompts, streaming infrastructure, a proactive and re-active automated quality control system and a reusable chat SDK.
And we’re still iterating. Next, we’re investing further in Yelp Assistant to add new capabilities such as search, side-by-side business comparisons, more advanced dynamic prompt composition, RAG improvements that include incorporating embedding-based search for review snippets and website content and ranking. improvements, advanced caching, allowing for multimedia inputs, and more. Thanks for reading!
Acknowledgements
This was a multi-quarter project with dozens of engineers, product managers, and designers.
The authors would like to acknowledge the Core Content team for their exceptional contributions to this initiative, especially Hakampreet Pandher, Shilpa Gopi, Shalini Pusapati, Matthew Calder, Akash Motwani, Sarthak Nandi, Alex Shkurko, Elena Marengi Sheng Pu, Filip Wolanski, and Mo Sayed.
In addition, we’d like to recognize the many engineers and UX teams who designed and built the chat frontend and platform; while this post focuses on the backend systems, a follow-up post will cover the chat UX and server-driven UI work in more detail.
This blog reflects the collaborative effort and technical expertise that each member has brought to the table. Your dedication and innovative approach have been crucial in advancing our engineering goals. Thank you!
Join Our Team at Yelp
We're tackling exciting challenges at Yelp. Interested in joining us? Apply now!
View Job