Modernizing Business Data Indexing

-
Benjamin Douglas, Tech Lead; Mohammad Mohtasham, Software Engineer
- Jun 7, 2021
On the Yelp app and website, there are many occasions where we need to show detailed business information. We refer to this process as Data Hydration, filling out a “dry” business with compelling, rich data. Whether on the home screen, search results page or business details page, there is a large set of properties we may show about any given business, everything from name and address to photos, Verified Licenses, insights, and more. These properties are stored in a variety of different databases, and their display is subject to a significant amount of filtering and transformation logic. All of this creates challenges for scaling and performance.
One technique we rely on heavily is the use of materialized views. Using this technique, we gather the data from the various sources and apply the transformation logic offline, storing it in a single key-value store for rapid fetching. The indexing process for this system for many years was our home-grown ElasticIndexer, which has become outdated and doesn’t take advantage of recent advances in Yelp’s backend data processing infrastructure. This post tells the story of our migration from the legacy system to an improved ElasticIndexer 2, meeting several challenges in the process and ultimately delivering a host of advantages.
ElasticIndexer: Legacy Indexing System for the Materialized View
Let’s take a closer look at our materialized view and the role it plays in our Data Hydration system. As a motivating example, let’s look at the delivery property. This shows up in the UI when a restaurant offers delivery through the Yelp platform.
For various reasons, the form of a business’s delivery-related data stored in our database is not the same as that served to clients such as the website or app. For one, the database schema is relatively static to accommodate data from years ago, while the client applications are constantly changing. Also, the database form is optimized for data modeling, while the form sent to clients is optimized for speedy processing. Thus, transformation logic needs to be applied to the data fetched from the database before being sent to the clients.
The central challenge of maintaining a materialized view of this property is to react to changes in the underlying data store to update the view with the transformed property. This all must happen in real-time to avoid serving stale data. This becomes especially complicated when a property depends on multiple database tables, which is true for many properties including delivery availability.
For many years, we used ElasticIndexer to index the materialized view for our Data Hydration platform. ElasticIndexer listens to table change logs (implemented as a separate MySQL table) in the underlying databases, and, in response to changes, will issue database queries and run the transformation logic, ultimately writing the result to the Cassandra materialized view. As a performance and scaling measure, the change logs only contain the primary key of the row being changed, so re-fetching the row from the database is required for any non-trivial transformation. In cases where the business ID is not the primary key of the database table, a domain-specific language (DSL) was used to establish a mapping between a given row and the relevant business ID. This process is illustrated below.
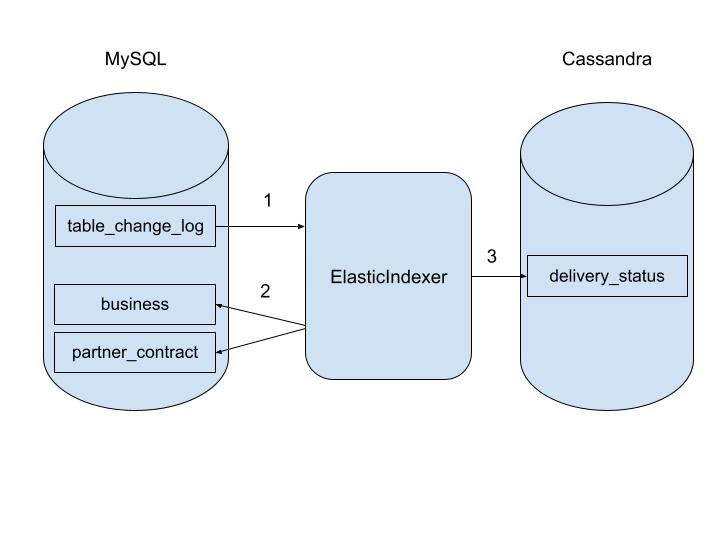
While this system has generally served us well, there are several downsides to this approach. First, the need to re-issue queries to the database unnecessarily increases the load on the database and introduces race conditions. Database deletes are not supported, as the row would be gone when the indexer would query it. Rewinding the materialized view to an arbitrary point is not possible. Specifying relationships between the different tables was awkward in the special-purpose DSL. Having properties based on the current time was hacky to implement. And parallelizing the process was difficult given the implementation of the change log.
There must be a better way…
ElasticIndexer 2: The Next Generation Indexing System for the Materialized View
As stream processing tools and systems such as Flink become more mature and popular, we have decided to create our next generation Data Hydration indexing system based on these new technologies. MySQL is the authoritative source of truth for most applications at Yelp. We stream real-time changes in MySQL to Kafka topics using MySQLStreamer, which is a database change data capture (CDC) and publishing system. Once this data is available in Kafka data pipelines, we have a variety of handy customized stream processing tools based on Flink to do most of the necessary data transformation on business properties before storing them in materialized views in Cassandra:
- StreamSQL: A Flink Application for performing queries on one or more Kafka data streams using syntax supported by Apache Calcite.
- Joinery: A Flink service built at Yelp, performing un-windowed joins across keyed data streams. Each join output is in the form of a data stream.
- Aggregator: A Flink-based service that aggregates Data Pipeline messages. Think of it as the GROUP BY SQL statement over streams.
- Apache Beam: An open-source unified programming model that allows users to write pipelines in a set of different languages (Java, Python, Go, etc.) and to execute those pipelines on a set of different backends (Flink, Spark, etc.).
- Cassandra Sink: A Flink-based data pipeline data connector for Apache Cassandra. It is responsible for reliably loading data pipeline messages into Cassandra in real time.
- Timespan Updater: A Flink-based tool to schedule data transformation tasks based on date and time conditions.
There are several cases that data transformation requires complex logics that the above tools alone cannot implement. To support such cases we define the logic in a stand-alone service that Beam jobs can communicate to retrieve transformed data. The following figure illustrates a high level overview of our new indexing topology:
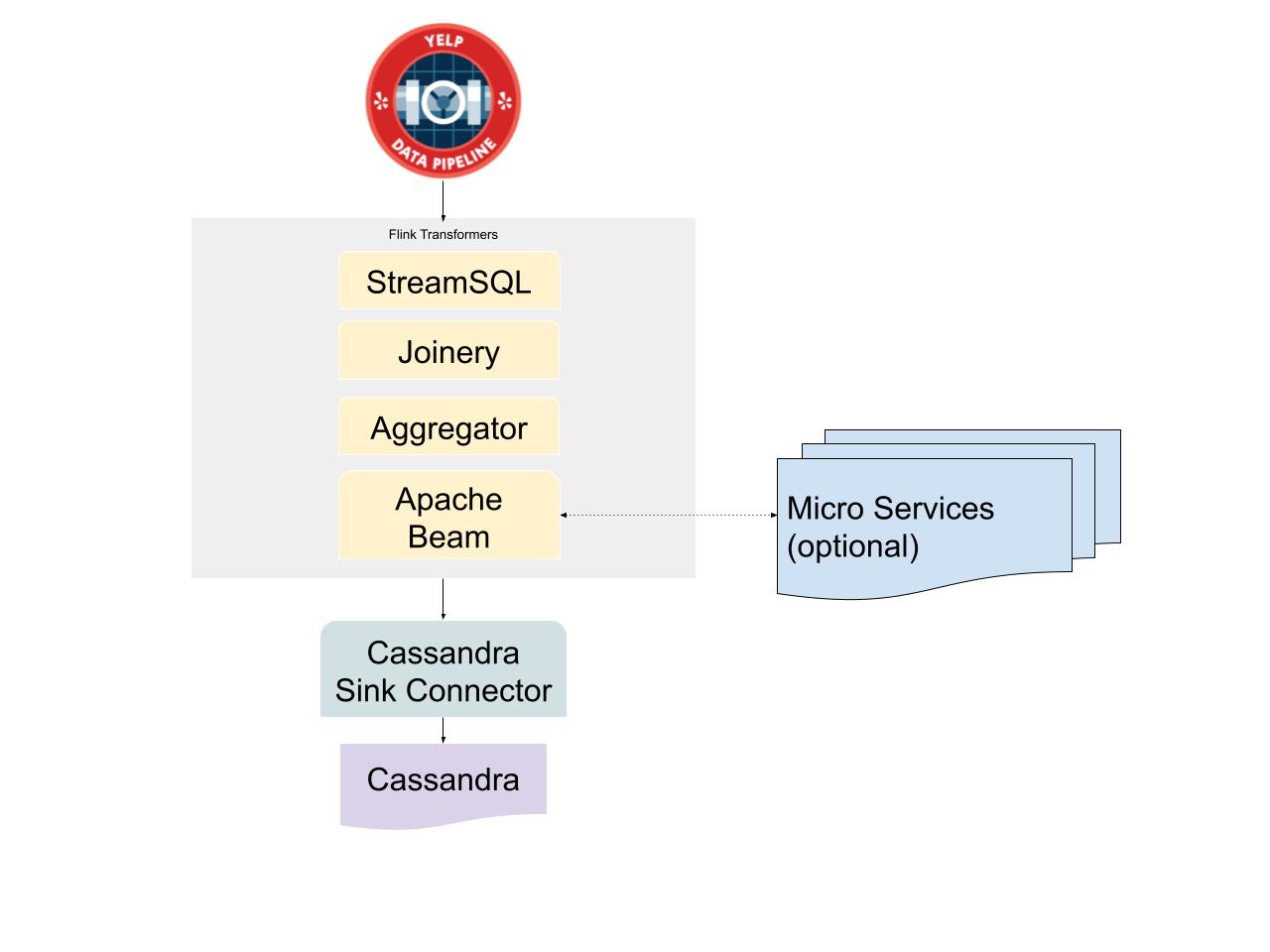
The new mechanism reduces database load dramatically as most of the transformation is done inside Flink applications. With this system, the source of data changes can be any data stream, and we are no longer limited to getting changes only from MySQL. Backfilling data in case of adding new properties or failures is relatively easy by changing data pipeline schemas and resetting/rewinding input streams’ offsets. All of the data pipeline tools at Yelp support delete operations, which makes it very easy to delete business properties from materialized views. This ensures that we don’t store stale data in Cassandra. Since both Kafka and Flink are built for distributed environments, they provide first class parallelization capability, which can be used to increase indexing throughput, especially during backfilling data for all businesses.
Migration Process and its Challenges
One of the main challenges that we faced during the migration was porting complex business logic from stand-alone services (Python or Java) into Flink applications, despite having various Flink applications to cover various specific use cases. Some of these logic migrations required complex streaming topology that were hard to maintain and monitor.
The legacy indexer’s logic was in multiple microservices. Not only was this logic used by the legacy indexer, but also other applications and clients. That’s why we couldn’t simply move the logic to the data pipeline. We would have had to create duplicate logic in our Flink applications to keep other parts of Yelp’s microservice ecosystem working smoothly. This could easily lead to discrepancies in application logic in microservices and Flink applications, especially when new complex logic that is hard to create in our generic Flink applications is added to a microservice. This was the reason that we had to keep some of the logic in microservices and call them from Beam jobs, whenever they were needed.
One of the biggest requirements for this project was to switch to the new system without causing any down time for the downstream services. We achieved this goal by a multi-step launch process for each property at a time. We ran the legacy and the new indexers in parallel so that both Cassandra clusters had the same data. The next step was to verify if the data in the new cluster matched that of the old one. Because of the large amount of data and the real-time indexing aspect of both of the indexers, we couldn’t simply do a direct one-to-one comparison between records in each cluster by querying them directly from Cassandra. That’s why we modified the consumer service of this data to pull data for a small percentage of requests from the new Cassandra cluster in the background, while it was serving users with the data from the old cluster. Then we logged both old and new data. After collecting enough data samples, we ran a sanity check script to verify that the new data was correct. It was only after this step that we had enough confidence to switch the consumer service to read data from the new cluster.
How’s the New System Working?
Fantastic! 😉 We now have a proper monitoring system for our data ingestion system, which gives us granular information and control on each component. Maintenance has become a lot easier. We can now scale up/down the indexer for each property according to its load without affecting indexing jobs in other properties.
We now have a proper dead-letter queue that can be utilized to backfill properties for businesses that fail for various reasons. With this tool we would know the exact count of failing records, if they ever happen.
Acknowledgements
Many people were involved in this project, but special thanks to Yujin Zhang, Weiheng Qiu, Catlyn Kong, Julian Kudszus, Charles Tan, Toby Cole, and Fatima Zahra Elfilali who helped with the design and implementation of this project.
Become an Engineer at Yelp
Are you interested in using streaming infrastructure to help solve tough engineering problems?
View Job