Joinery: A Tale of Un-Windowed Joins

-
Vipul Singh, Technical Lead
- Dec 11, 2018
Summary
At Yelp, we generate a wide array of high throughput data streams spanning logs, business data, and application data. These streams need to be joined, filtered, aggregated, and sometimes even quickly transformed. To facilitate this process, the engineering team has invested a significant amount of time analyzing multiple stream processing frameworks, ultimately identifying Apache Flink as the best suited option for these scenarios. We’ve now implemented a join algorithm using Flink, which we’re calling “Joinery.” It is capable of performing un-windowed one-to-one, one-to-many, and many-to-many inner joins across two-or-more keyed data streams.
So, how does it work? In the simplest terms, developers provide a config file describing the desired join, and the Joinery service executes a joined keyed output stream.
Background: What Problem Are We Trying to Solve?
Since the advent of streaming pipelines, the gap between streams and tables has been greatly reduced. Streaming pipelines allow for computationally intensive data operations like joins, filtering, and aggregation to be performed on high throughput data streams. While most streaming pipelines support joins within time-bounded windows, there are many that require joins on un-windowed data.
One such use case is Salesforce. Salesforce is a downstream data store we use at Yelp to empower sales teams. It contains data about the businesses supported on the platform, such as purchased advertising packages and business owner profiles. The data is stored in separate tables in a relational database, but is also denormalized in Salesforce to help prevent expensive real-time join operations when sales people need access to data on-the-fly (e.g., while pitching to clients).
To support this use case, we implemented a real time stream joiner that joins data across multiple data streams and presents the normalized tables in the relational database into one stream that feeds into the denormalized table in Salesforce. In the figure below, each inbound stream represents a table in the relational database. The stream joiner consumes messages from these inbound streams and creates fully joined messages based on a key before publishing them to outbound streams. For example, in the stream joiner below, the key used to join messages is the business-id, which represents the primary key of the business and advertisement tables and the foreign key of the business owner table.
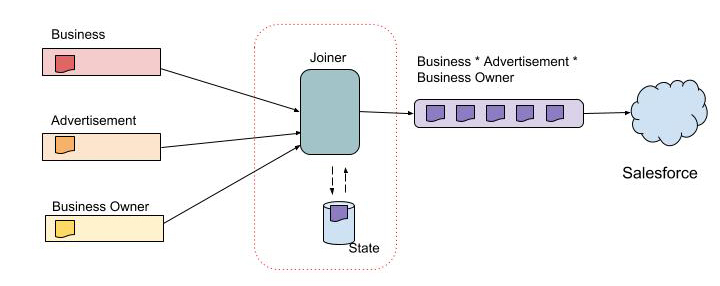
Previous Approach
Historically, Yelp Engineering has built Paastorm spolts to solve similar problems. However, when datasets grew to the tens of gigabytes, spolts incurred a higher maintenance cost to recover. Another issue was that they were not designed for stateful applications, so using Paastorm spolts for stateful solutions meant having to implement state management from scratch. To cite an example, one spolt that uploaded results to Salesforce stored several tens of millions of messages at any given time, and in case of a crash, took several hours to recover! This resulted in delays in the overall pipeline and required manual intervention, which ultimately hampered engineering productivity.
This historical use mandates that any approach to joining unbounded streams must scale to be fault tolerant.
A Join Algorithm?
Our past experience in building data pipelines and aggregation led us to the following joiner algorithm:
Algorithm:
- Shuffle/sort messages into equi-join partitions based on message keys.
- Insert every message into its corresponding hash table within the multi-map.
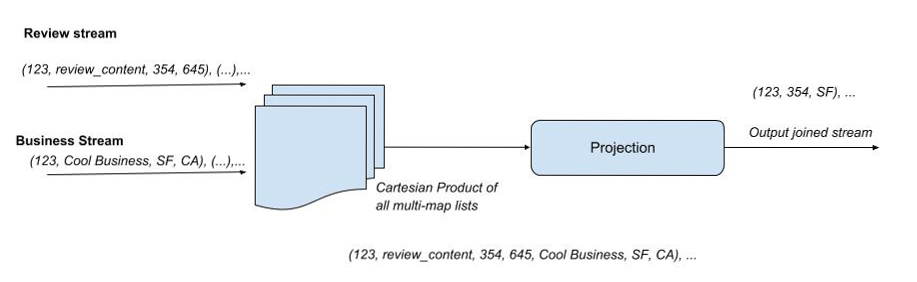
- Construct the output by taking the Cartesian product of all the multi-map’s lists.
- Filter and project based on what’s required in the final output.
The above algorithm can be summed up into three key parts:
- Update phase
- Join phase
- Projection phase
Let’s discuss these phases in more detail.
Update Phase
For each input, the algorithm creates a hash table of schemas, and then maps datapipeline messages to keys in these streams. For every new incoming message, we check the message type (analogous to MySQL LogType - log, create, update, delete) and apply the create/update/delete messages to their corresponding hash tables.
Join Phase
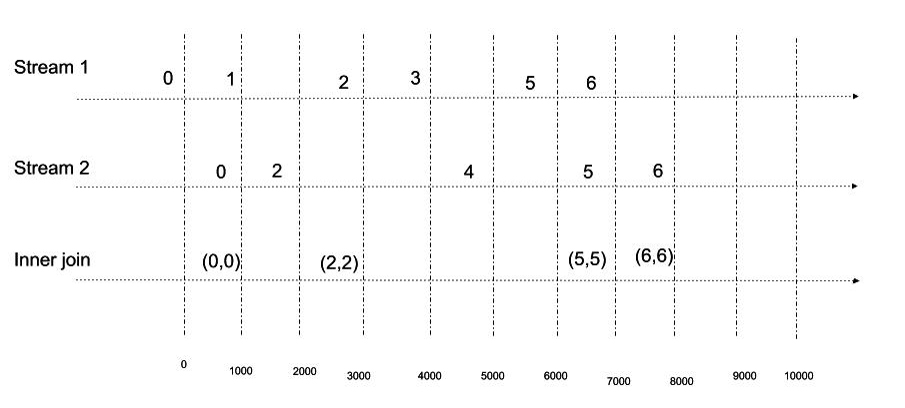
Next, we probe the above hash tables to generate a cross-product of all messages. This generates all possible permutations of the new message with the tuples of the other relations. The joined messages are then published to the target stream. Note that a joined message (one for each row of the joined result) is published to the target stream when there are inbound messages (one on each inbound stream) with the same key. The join phase of the algorithm here performs an inner join.
Projection Phase
During creation of the output message, aliases can be used to project fields in the output schema to prevent naming collisions. Fields can also be dropped entirely if unnecessary to downstream consumers.
This algorithm only works on log compacted, schematized keyed streams. Using a log compacted stream prevents unbounded growth and ensures that a consumer application will retain at least the last known value for each message key within the kafka partition. These constraints imply the algorithm works with data change log streams as opposed to regular log streams.
In the diagram below, the input streams are represented on the left, with messages coming from different input sources. The figures depict the cartesian product computed for the input streams. In the join phase, we perform stream aggregation that emits a tuple when records with the same key (id in this example) are detected from the input sources. In other words, the algorithm checks if the keys in the input stream have a mapping in all hash tables (streams), and only if there is, move to the projection phase.
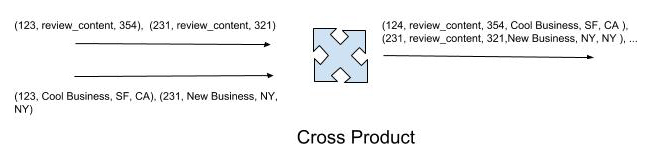
This schematic illustrates how the algorithm emits records:
This Is Cool, but What About the Memory Footprint?
Since Joinery computes joins on unbounded streams, its internal state could potentially grow very large. Having a large in-memory state is costly and does not allow fast recovery. To alleviate this, Joinery keys data streams by different keys, which helps distribute the memory footprint across nodes. However, this doesn’t necessarily keep the state size from growing beyond the total available heap memory on its nodes, which may lead to OOM errors. Therefore, we needed a way to spill data to disk while maintaining a relatively low memory footprint.
By utilizing Flink’s incremental checkpointing with RocksDB, we can persist the application state to an external storage. This results in a low memory footprint and allows for a faster recovery time (as compared to our spolt implementation), in a matter of minutes. For a more thorough understanding of Flink and RocksDB, check out this article.
So Far So Good, but Do You Have an End-To-End Example?
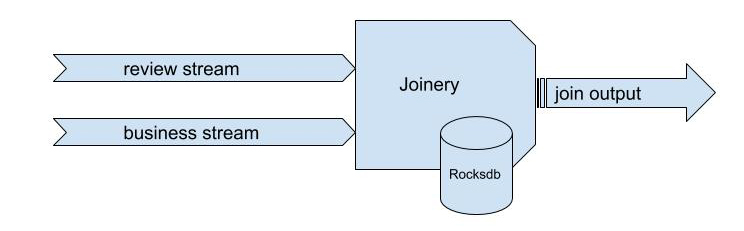
Let’s talk about a hypothetical scenario where Joinery joins two streams: user review and business.
user review:
- biz_id
- content
- review_id
- user_id
user review stream
business:
- business_id
- name
- address
- state
business stream
We want to generate an output stream that joins the above two streams based on the business id. The Joinery configuration for this would be as follows:
join:
- schema_id: 12345
join_keys: [biz_id]
exclude_fields: [content, review_id]
- schema_id: 23143
join_keys: [business_id]
aliases:
- from: business_id
to: biz_id
exclude_fields: [address, name]
output:
namespace: joinery_example
source: business_review_join
Doc: Join of business table and review table
pkey:
- business_id
Joinery Configuration
The above configuration guides Joinery to join the two streams of the biz_id key across the input streams. One important thing to note here is that even though we don’t have the same key names in both streams, we can utilize aliases to map keys (similar to traditional SQL aliases). An example of this join is provided below:

Future Work
One of the main challenges we’ve faced and are looking to tackle in the future is maintaining data integrity during upgrades and state migrations. A truly robust streaming application deployed in production should be resilient to restarts and state recovery should work consistently without any significant time lags.
Blackbox testing and auditing an application like Joinery is hard. Yelp has built tooling like pqctl (custom docker compose environment) that helps infrastructure teams have testbeds to implement repeatable, simple unit tests. By leveraging this tooling and developing an extensive acceptance test suite, we look to test more end-to-end joins while inducing failures scenarios. Some of this is in progress, but there is still more work to be done to ensure that we can repeatedly verify states after restarts, particularly on version upgrades of Joinery.
Appendix:
Acknowledgements
Thanks to Justin Cunningham, Semir Patel, Alexandru Malaescu and Sharvari Marathe who contributed to this project, in addition to members of the Stream Processing team for their advice and support.
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job