Billions of Messages a Day - Yelp's Real-time Data Pipeline

-
Justin C., Software Engineer
- Jul 14, 2016
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
Faced with the challenges of scaling out its engineering organization, Yelp transitioned to a service oriented architecture (SOA). Services improved developer productivity but introduced new communications challenges. To solve these problems, Yelp built a real-time streaming data platform.
We built a unified system for producer and consumer applications to stream information between each other efficiently and scalably. It does this by connecting applications via a common message bus and a standardized message format. This allows us to stream database changes and log events into any service or system that needs them, for example: Amazon Redshift, Salesforce, and Marketo.
The Challenges with Scaling Out
In 2011, Yelp had more than a million lines of code in a single monolithic repo, “yelp-main”. We decided to break the monolith apart into a service oriented architecture (SOA), and by 2014 had more than 150 production services, with over 100 services owning data. Breaking apart “yelp-main” allowed Yelp to scale both development and the application, especially when coupled with our platform-as-a-service, PaaSTA.
Services don’t solve everything. Particularly when dealing with communication and data, services introduce new challenges.
Service to Service Communication
Service-to-service Communication Scales Poorly
Metcalfe’s Law says that the value of a communications network is proportional to the square of the number of connected compatible communications devices. Translating to a SOA, the value of a network of services is proportional to the square of the number of connected services. The trouble is, the way that service-to-service communication is typically implemented isn’t very developer-efficient.
Implementing RESTful HTTP connections between every pair of services scales poorly. HTTP connections are usually implemented in an ad hoc way, and they’re also almost exclusively omni-directional. 22,350 service-to-service omni-directional HTTP connections would be necessary to fully connect Yelp’s 150 production services. If we were to make a communications analogy, this would mean every time you wanted to visit a new website, you’d have to first have a direct link installed between your computer and the site. That’s woefully inefficient.
Failing at Failure
Aside from complexity, consistency is problematic. Consider this database transaction and service notification:
session.begin()
business = Business()
session.add(business)
session.commit()
my_service_client.notify_business_changed(business.id)
If the service call fails, the service may never be notified about the business creation. This could be refactored like:
session.begin()
business = Business()
session.add(business)
my_service_client.notify_business_changed(business.id)
session.commit()
Then the commit could fail, in which case the service would be notified that a business was created that doesn’t exist.
Workarounds exist. The service could poll for new businesses, or use a messaging queue and call back to make sure the business was actually added. None of this is as easy as it initially appears. In a large SOA, it wouldn’t be strange to find multiple notification implementations, with varying degrees of correctness.
Working with Data Across Services is Hard
~86 million is a magic number
Yelp passed 100 million reviews in March 2016. Imagine asking two questions. First, “Can I pull the review information from your service every day?” Now rephrase it, “I want to make more than 1,000 requests per second to your service, every second, forever. Can I do that?” At scale, with more than 86 million objects, these are the same thing. At scale the reasonable becomes unreasonable. Bulk data applications become service scalability problems.
Joins get pretty ugly. The N+1 Query Problem tends to turn into the N Service Calls problem. Instead of code making N extra queries, it makes N service calls instead. The N+1 Query Problem is already well understood. Most ORMs implement the eager loading solution out-of-the-box. There isn’t a ready solution for service joins.
Without a ready solution, developers tend to design adhoc bulk data APIs. These APIs tend to be inconsistent because developers are distributed across teams and services. Pagination is particularly prone to inconsistency issues, with no clear standard. Popular public APIs use everything from custom response metadata to HTTP Link headers.
To join across services scalably you need to upgrade your service stack. Every data-owning service and client library will need work.
Possible Solutions?
The first solution that developers usually come to is implementing bulk data APIs. Of course, implementing a bulk data API for every data type stored by every service can be very time consuming. Somewhat naturally, a generalized bulk data API comes up, where the API can take arbitrary SQL, execute it, and return the results. Unfortunately, this is a pretty major violation of service boundaries. It’s equivalent to connecting to a service’s database to create new data, resulting in a distributed monolith. And it’s brittle. Every caller needs to know a lot about the internal representation of data inside the services that it needs data from, and needs to respond in lockstep to data changes in the service, tightly coupling the caller and service.
A potential solution for bulk data sharing is periodically snapshotting the service database, and sharing the snapshots. This approach shares the brittleness of the bulk data API, with the added challenge that differential updates can be difficult to implement correctly, and full updates can be very expensive. Snapshots are further complicated by having some data that is meaningless without the underlying code. Concretely, boolean flags stored in bitfields or categorical data stored as integer enums are common examples of data that isn’t inherently meaningful without context.
A Generalized Solution
Now that you have the context of the problem, we’ll explore how it can be solved at a high level using a message bus and standardized data formatting. We’ll also discuss the system architecture when those two components are integrated, and what can be accomplished with that architecture.
The Message Bus
Architecturally, a message bus seemed like a good starting point for addressing these issues.
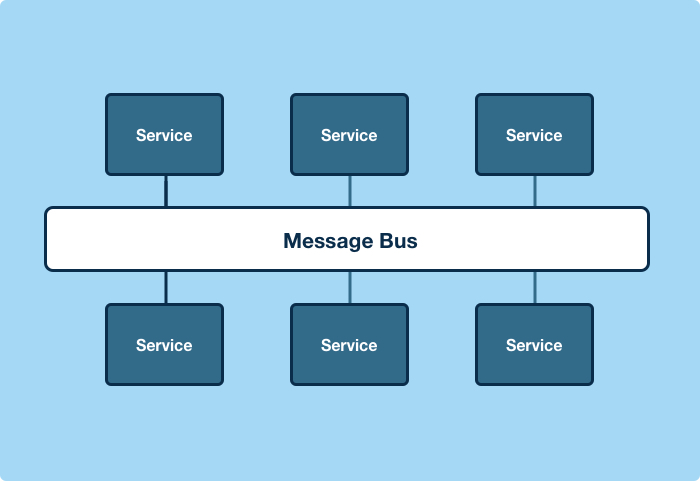
A bus would reduce the connection complexity from n^2 to n, and in our case from more than 22,000 connections to just 150.
Apache Kafka, a distributed, partitioned, replicated commit log service, is ideal for this application. Aside from being both fast and reliable, it has a feature called log compaction that’s very useful in this context. Log compaction prunes topics with a simple guarantee – the most recent message for a given key is guaranteed to remain in the topic. This yields an interesting property, if you were to write every change that happens in a database table into a topic, keyed by the primary key in the database, replaying the topic would yield the current state of the database table.
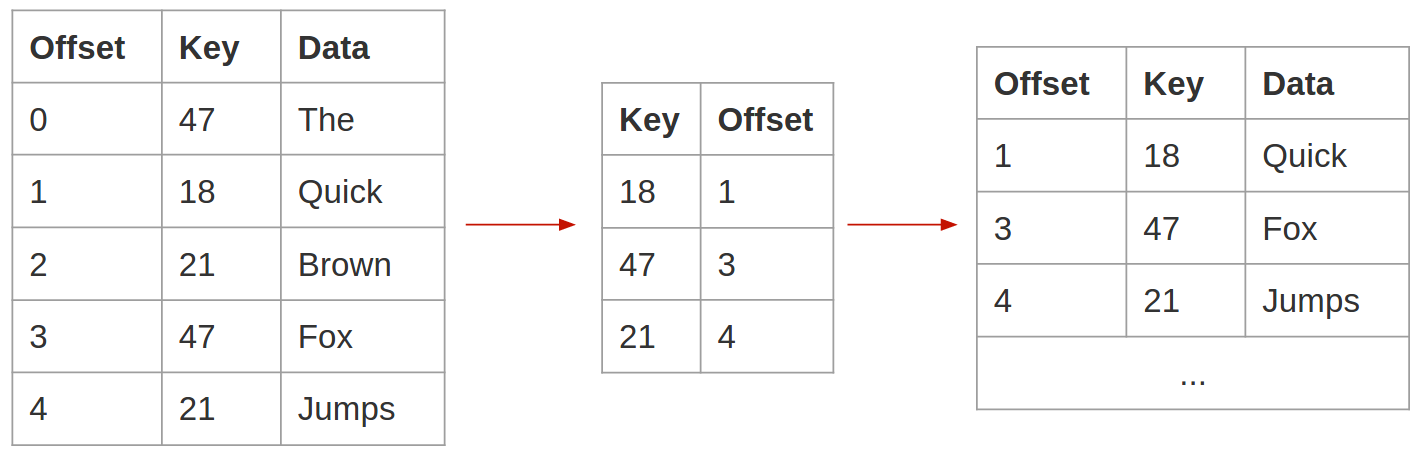
Log compaction retains at least the most recent message for every key.
Stream-table duality is well-covered by Jay Kreps in The Log: What every software engineer should know about real-time data’s unifying abstraction, and in the Kafka Streams docs. Exploiting this duality using log compaction allows us to solve many of our bulk data problems. We can provide streaming differential updates and with them guarantee that a new consumer, replaying a topic from the beginning, will eventually reconstruct the current state of a database table. In Yelp’s data pipeline, this property enables engineering teams to initially populate and stream data changes to Redshift clusters.
Decoupled Data Formats
Selecting how data will be transported is only part of the solution. Equally important is determining how the transported data will be formatted. All messages are “just bytes” to Kafka, so the message format can really be anything. The obvious answer to this is JSON, since it has performant parsing implementations in most languages, is very broadly supported, and is easy to work with. However, JSON has one core issue: it’s brittle. Developers can change the contents, type, or layout of their JSON data at any time, and in a distributed application it’s hard to know the impact of data changes. Unfortunately, JSON data changes often are first detected as production errors, necessitating either a hotfix or rollback, and causing all kinds of problems downstream.
Yelp’s data processing infrastructure is tree-like. Our core data processing tends to produce intermediate outputs that are consumed, reprocessed, and refined by multiple layers and branches. Upstream data problems can cause lots of downstream problems and backfilling, across many different teams, especially if they’re not caught early. This problem is one we wanted to address, when we moved to a streaming architecture.
Apache Avro, a data serialization system, has some really nice properties, and is ultimately what we selected. Avro is a space-efficient binary serialization format that integrates nicely with dynamic languages like Python, without requiring code generation. The killer feature of Avro, for our system, is that it supports schema evolution. That means that a reader application and a writer application can use different schema versions to consume and produce data, as long as the two are compatible. This decouples consumers and producers nicely - producers can iterate on their data format, without requiring changes in consumer applications.
We built an HTTP schema store called the “Schematizer,” that catalogs all of the schemas in Yelp’s data pipeline. This enables us to transport data without schemas. Instead, all of our avro-encoded data payloads are packed in an envelope with some metadata, including a message uuid, encryption details, a timestamp, and the identifier for the schema the payload was encoded with. This allows applications to dynamically retrieve schemas to decode data at runtime.
High Level Architecture
If we standardize the transport and formatting of data, we can build universal applications that don’t care about the data itself.
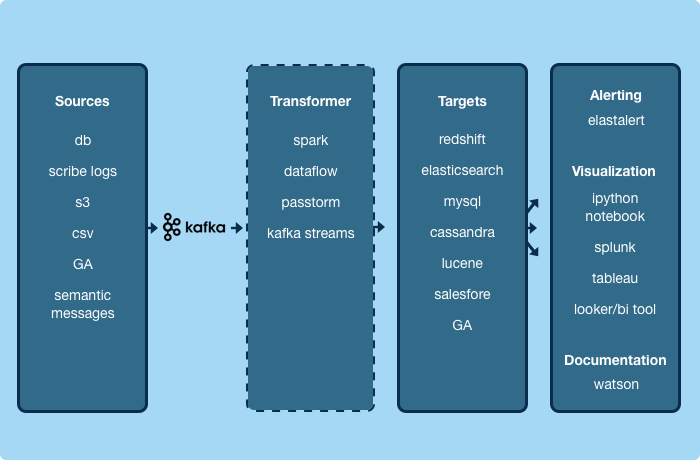
Messages generated by our logging system are treated exactly the same as messages generated from database replication or from a service event. Circling back to Metcalfe’s Law, this architecture increases the value of Yelp’s streaming data infrastructure so that it scales quadratically with the number of universal consumer or producer applications that we build, yielding strong network effects. Concretely, as a service author, it means that if you publish an event today, you can ingest that event into Amazon Redshift and our data lake, index it for search, cache it in Cassandra, or send it to Salesforce or Marketo without writing any code. That same event can be consumed by any other service, or by any future application we build, without modification.
Yelp’s Real-Time Data Pipeline
The data pipeline’s high level architecture gives us a framework in which to build streaming applications. The remaining sections will discuss the core of Yelp’s real-time data pipeline, focusing on the invariants that the system provides, and the system-level properties that result. Following posts in the series will discuss specific applications in depth.
A Protocol for Communication
Yelp’s Real-Time Data Pipeline is, at its core, a communications protocol with some guarantees. In practice, it’s a set of Kafka topics, whose contents are regulated by our Schematizer service. The Schematizer service is responsible for registering and validating schemas, and assigning Kafka topics to those schemas. With these simple functions, we’re able to provide a set of powerful guarantees.
Guaranteed Format
All messages are guaranteed to be published with a pre-defined schema, and the schemas are guaranteed to be registered with the schema store. Data Pipeline producers and consumers deal with data at the schema level, and topics are abstracted away. Schema registration is idempotent, and registered schema are immutable.
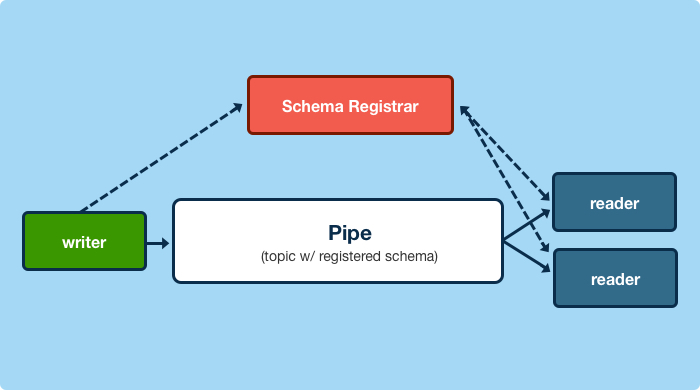
Any consumer, when first encountering data written with any arbitrary schema, can fetch that schema exactly once, and decode any data written with it.
Guaranteed Compatibility
One of the Schematizer’s core functions is assigning topics to schemas. In doing so, the Schematizer guarantees that if a consumer starts reading messages from a topic with an active schema from that topic, it will be able to continue doing so forever, despite upstream schema changes. In other words, every active schema assigned to a topic is guaranteed to be compatible with every other active schema assigned to the same topic. Applications won’t break because of schema changes.
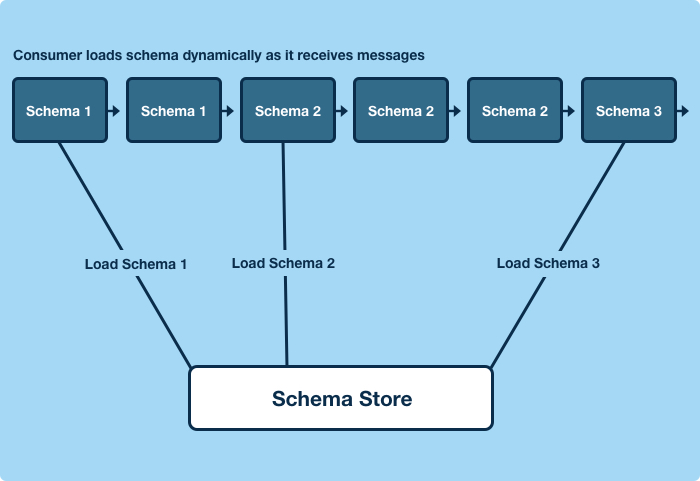
At runtime applications will fetch schemas used to write data messages dynamically, as messages encoded with previously unseen schemas appear in the topic. A producer can change the data format it’s producing without any action from any downstream consumers. The consumers will automatically retrieve the new writer schemas, and continue decoding the data with the reader schema they’ve been using. Producer and consumer data evolution is decoupled.
Guaranteed Registration
Data producers and consumers are required to register whenever they produce or consume data with a schema. We know what teams and applications are producing and consuming data across Yelp, which schemas they’re using, and with what frequency.
This allows producers to coordinate breaking data changes with their consumers, and allows for automated alerting of consumers in the event of a data fault. Producers are given the tools that they need to coordinate incompatible schema changes in advance. Registration further enables the deprecation and inactivation of outdated schemas. We can detect when a schema no longer has producers, and can coordinate the migration of consumers to more recent active schema versions out-of-band. Registration simplifies the compatibility story, since we can artificially constrain the number of active schemas in a topic - compatible schema changes typically need to be compatible with only a single existing schema.
Guaranteed Documentation and Data Ownership
The Schematizer requires documentation on all schema fields, and requires that all schemas assign a team that owns the data. Any schemas without this information will fail validation. That documentation and ownership information is then exposed through a web interface called Watson, where additional wiki-like documentation and comments can be added.
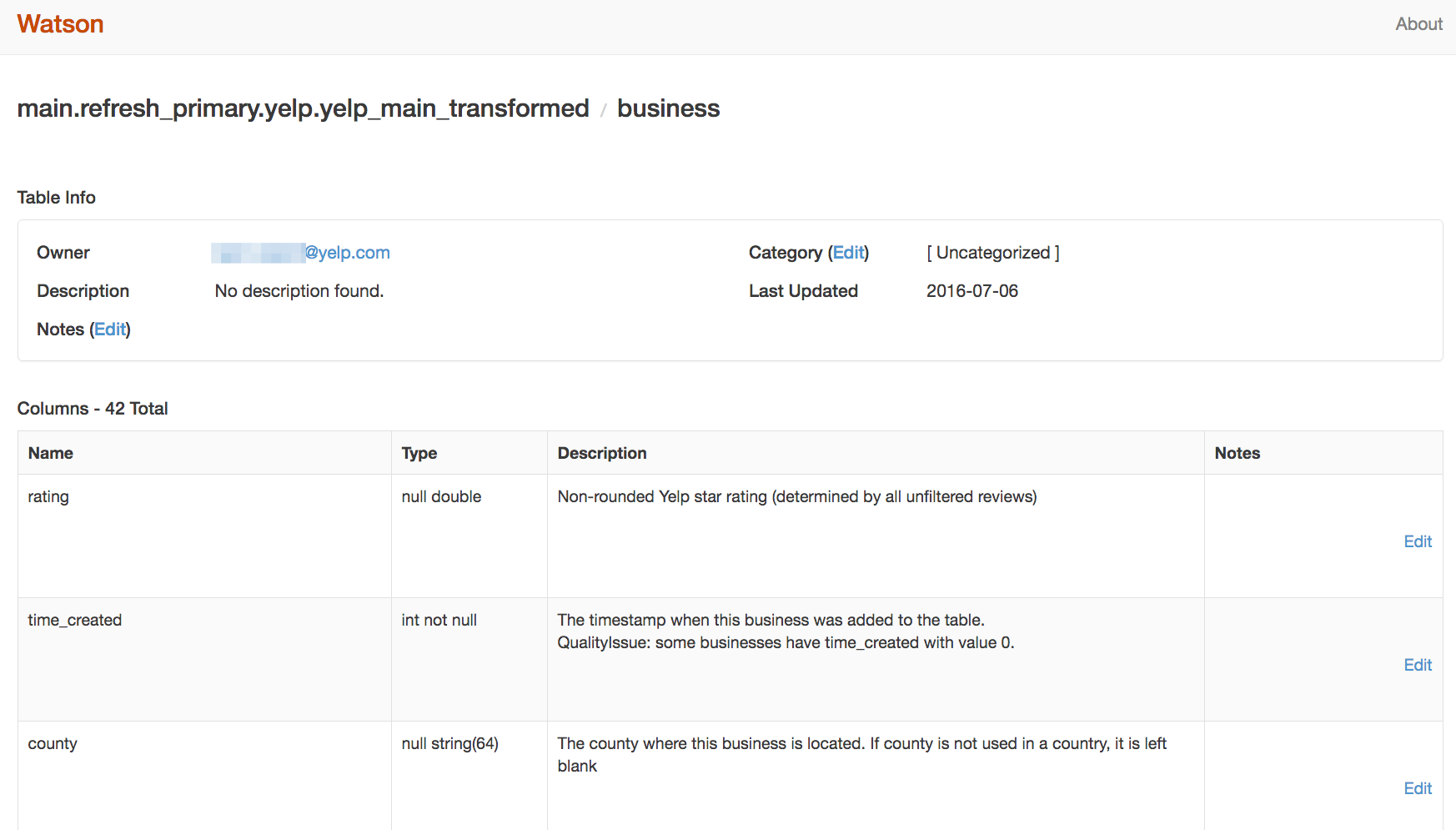
In many cases, we’ve extended this capability to systems that generate messages and schemas automatically. For example, schemas derived from database tables are documented by extracting docstring and ownership information from the corresponding models in our codebase. Automated tests prevent adding new data models without documentation and owners, or modifying existing data models without adding documentation.
Watson enables users to publicly ask the data owners questions, and to browse and contact data producers and consumers. The Schematizer has the concept of data sources and data targets, where it can track, for example, that a schema originates from a MySQL database table, and the data is streamed into a Redshift table. It’s able to produce documentation views dynamically for these data sources and targets. Effectively, adding documentation to code automatically documents Redshift tables, MySQL tables, and Kafka topics.
Guaranteed Data Availability
As mentioned above, one of the major issues with data transfer between services is dealing efficiently with bulk data. Using Kafka log compaction and keyed messages, we’re able guarantee that the most recent message for each key is retained.
This guarantee is particularly useful in the context of database change capture. When materializing a table from a topic containing captured database changes, this guarantees that if a consumer replays the topic from the beginning, and catches up to real time, it will have a complete view of the current state of the data in that table. The same system that provides differential updates, can thus be used to reconstruct a complete snapshot. All Aboard the Databus! describes the utility of streaming database change capture, which is effectively a single universal producer application in our unified infrastructure.
The Next Stage
In this post, we’ve stepped through the communications and bulk data challenges associated with SOAs, and explored the core of the real-time streaming data platform that Yelp built to solve them. We showed how using a message bus and standardized message format, along with some simple guarantees, enables the construction of powerful, data-agnostic producer and consumer applications.
Join us in the coming weeks, where we will dive deeply into some of the applications we’ve built inside and on top of the platform. We will cover the Schematizer and its documentation front-end Watson, our exactly-once MySQL change data capture system, our stream processor, and our Salesforce and Redshift connectors.
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
Build Real-time Data Infrastructure at Yelp
Want to build next-generation streaming data infrastructure? Apply to become an Infrastructure Engineer today.
View Job