Streaming MySQL tables in real-time to Kafka

-
Prem Santosh Udaya Shankar, Software Engineer
- Aug 1, 2016
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
As our engineering team grew, we realized we had to move away from a single monolithic application towards services that were easier to use and could scale with us. While there are many upsides to switching to this architecture, there are downsides as well, one of the bigger ones being: how do we provide services with the data they require as soon as possible?
In an ecosystem with hundreds of services, each managing millions and millions of rows in MySQL, communicating these data changes across services becomes a hard technical challenge. As mentioned in our previous blog post, you will quickly hit the N+1 query problem. For us, this meant building a system, called MySQLStreamer, to monitor against data changes and alert all subscribing services about them.
MySQLStreamer is a database change data capture and publish system. It’s responsible for capturing each individual database change, enveloping them into messages and publishing to Kafka. The notion of replaying every changeset from a table to reconstruct the entire table at a particular snapshot in time and reproducing a stream by iterating over every change in a table is referred to as a stream-table duality.
In order to understand how we capture and publish database changes, it’s essential to know a bit about our database infrastructure. At Yelp, we store most of our data in MySQL clusters. To handle a high volume of visits, Yelp must operate a hierarchy of dozens of geographically distributed read replicas to manage the read load.
How does replication work?
In order for replication to work, events on the master database cluster are written to a special log called the binary log. When a replica connects to its master, this binary log is read by the replica to complete or continue the process of replication, depending on the replication hierarchy. This process is bolstered by two threads running on the replica, an IO thread and a SQL thread. This is visualized in the figure below. The IO thread is primarily responsible for reading the binary log events from master, as they arrive, and copying them over to a local relay log in the replica. The SQL thread then reads these events and replays them in the same order that they arrived in.
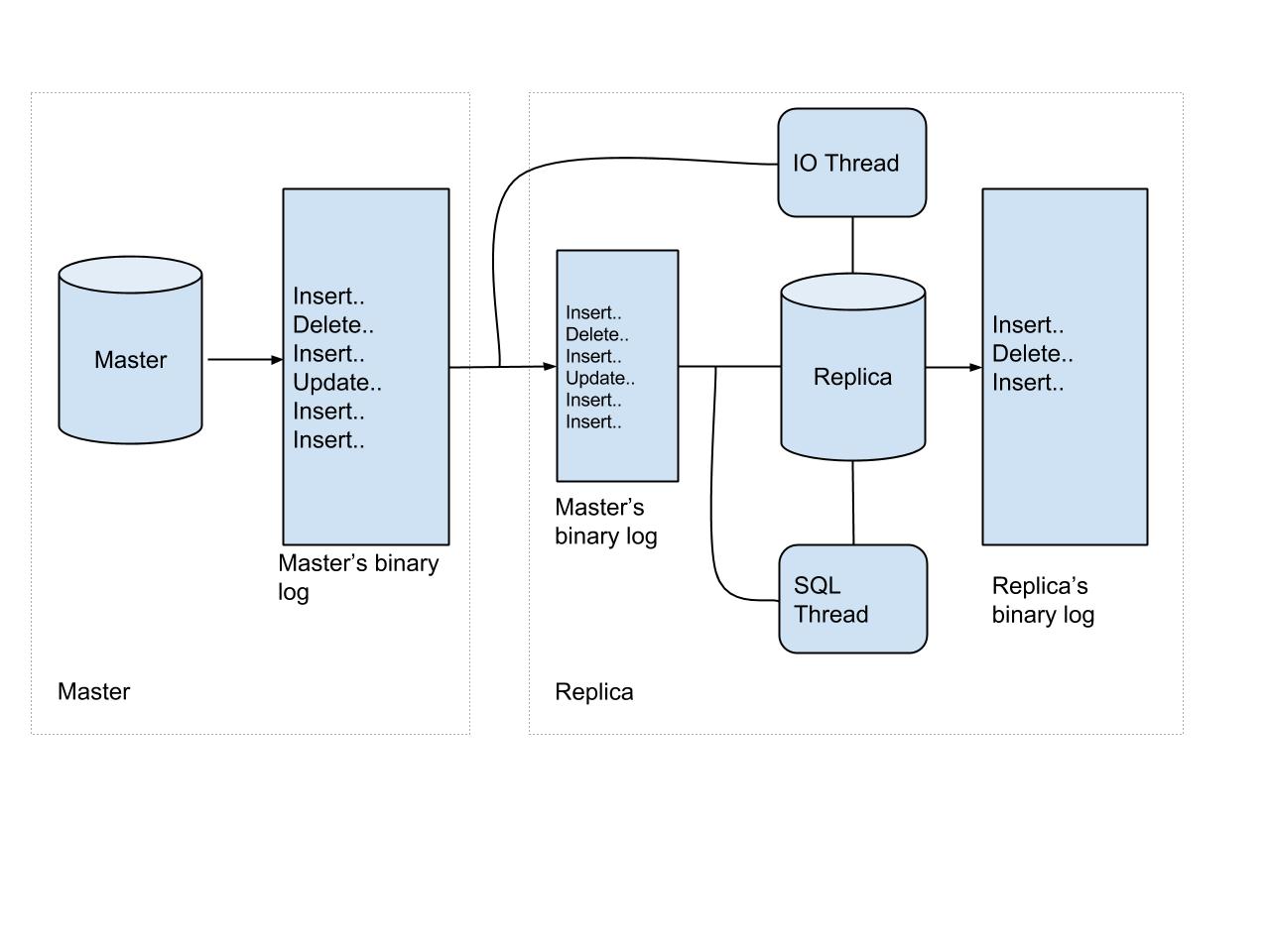
It should be noted here that an event played by the replica’s SQL thread need not necessarily be the latest event logged in the master’s binary log. This is shown in the figure above and is called replication lag. Yelp’s MySQLStreamer acts as a read replica, persisting updates into Apache Kafka, instead of materializing them into a table.
Type of MySQL replication
There are two ways of replicating a MySQL database:
- Statement-based replication (SBR)
- Row-based replication (RBR)
In statement-based replication, SQL statements are written to the binary log by master and the slave’s SQL thread then replays these statements on the slave. There are a few disadvantages of using statement-based replication. One important disadvantage is the possibility of data inconsistency between master and the slave. This is because the SQL thread in the slave is simply responsible for replaying log statements copied over from the master, but there could be instances where the statements generate non-deterministic outputs. Consider the following query:
INSERT INTO places (name, location)
(SELECT name, location FROM business)
This is a scenario where you want to SELECT certain rows and INSERT them into another table. In this case, selecting multiple rows without an ORDER BY clause would result in rows returned–but the order of those rows may not be the same if the statement was to be replayed multiple times. Also, if a column had an AUTO_INCREMENT associated with it, the rows might end up with different ranks each time the statement is executed. Another example would be using the RAND() or the NOW() methods which would end up generating different results when played on different hosts in the replication topology. Due to these limitations, we use row-based replication in the database required by the MySQLStreamer. In row-based replication, each event shows how the individual rows of a table have been modified. UPDATE and DELETE statements contain the original state of the row before it was modified. Hence, replaying these row changes will keep the data consistent.
Now we know what replication is, but why do we need the MySQLStreamer?
One of the main uses of Yelp’s real time streaming platform is to stream data changes and process them, in order to keep downstream systems up to date. There are two kinds of SQL change events that we have to be aware of:
- DDL (Data Definition Language) statements, which define or alter a database structure or schema.
- DML (Data Manipulation Language) statements, which manipulate data within schema objects.
The MySQLStreamer is responsible for:
- Tailing the MySQL binary log consuming both these types of events
- Handling the events depending on their type, and publishing the DML events to Kafka topics.
The MySQLStreamer publishes four distinct event types: Insert, Update, Delete and Refresh. The former three events correspond to DML statements of the same type. Refresh events are generated by our bootstrap process, described in detail later. For each event type, we include the complete row contents. Update events include the full row, both before and after the update. This is particularly important for dealing with cycles. Imagine implementing a geocoding service that consumes Business updates, and triggers a latitude and longitude update on that same Business row if the address changes. Without the before row content, the service would have to store a significant amount of state to determine if a row’s address had actually changed, and to ignore latitude and longitude updates. With both before and after content, it’s trivial to generate a diff and break these cycles without keeping any state.
| Event Type | Message Contents |
|---|---|
| Insert | Full Row |
| Update | Full Row Before Update and Full Row After Update |
| Delete | Full Row Before Delete |
| Refresh | Full Row |
Database Topology
The MySQLStreamer is powered by three databases as shown below:
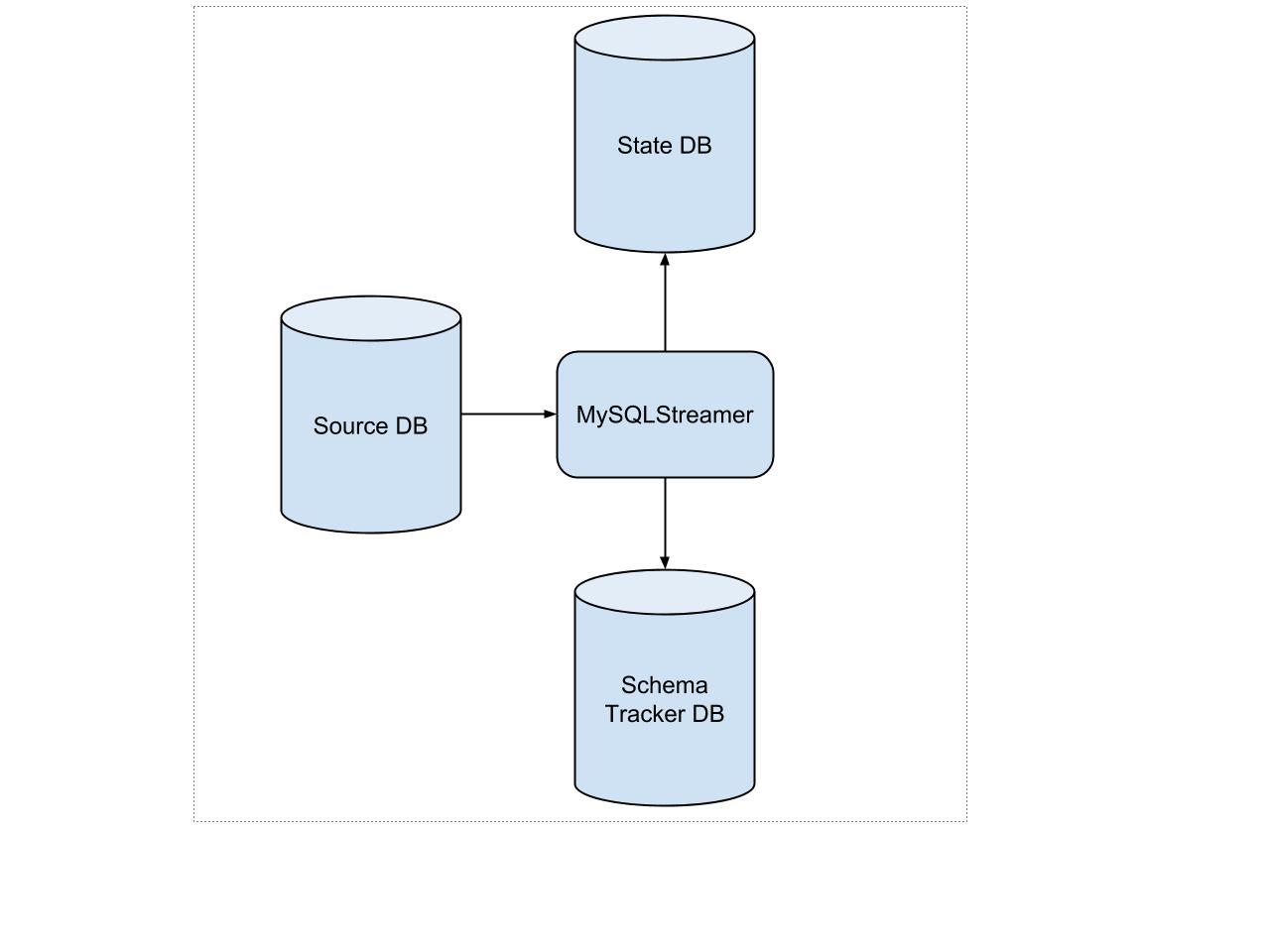
The Source Database
This database stores change events in the upstream data. It is tracked by the MySQLStreamer in order to stream those events to downstream consumers. A binary log stream reader in the MySQLStreamer is responsible for parsing the binary log for new events. Our stream reader is an abstraction over the BinLogStreamReader from the python-mysql-replication package. This api provides three main functionalities: to peek at the next event, to pop the next event, and to resume reading from the stream at a specific position.
The Schema Tracker Database
The schema tracker database is analogous to a schema-only slave database. It is initially populated with schemas from the source database, and kept up to date by replaying DDL statements against it. This means it skips the data and stores the skeleton of all the tables. We lazily retrieve CREATE TABLE statements from this database to generate Avro schemas using the Schematizer service. Schema information is also necessary to map column name information to rows in the binary log. Because of replication lag, the database schema for the current replication position of the MySQLStreamer doesn’t necessarily match the current schema on the master. Hence, the schema used by the MySQLStreamer cannot be retrieved from the master. We chose to use a database for this to avoid re-implementing MySQL’s DDL engine.
Should the system encounter a failure during the execution of the SQL statement, the database might end up in a corrupted state, as DDL statements are not transactional. To circumvent this issue, we treat the entire database transactionally. Before applying any DDL event, we checkpoint, take a schema dump of the entire schema tracker database, and store it in the state database. The DDL event is then played. If it succeeds, the stored schema dump is deleted and another checkpoint is taken. A checkpoint basically consists of saving the binary log file name and the position along with the Kafka offset information. In case of failure, after the MySQLStreamer restarts it checks to see if a schema dump exists. If it does, it replays the schema dump before handling the DDL event it failed on. Once the schema dump is replayed, the MySQLStreamer restarts the tailing of events from the checkpointed position, eventually catching up to real time.
The State Database
The state database stores the MySQLStreamer’s internal state. It consists of three tables that store various pieces of state information:
DATA_EVENT_CHECKPOINT
Stores information about each topic and the corresponding last known published offset.
GLOBAL_EVENT_STATE
The most important piece of information stored in this table is the position. The position looks like this:
| heartbeat_signal | heartbeat_timestamp | log_file | log_position | offset |
|---|
One of the prerequisites for fail-safe replication is to have an unique identifier associated with every transaction. It not only provides benefit in the process of recovery but also in hierarchical replication. The global transaction identifier (GTID) in one such identifier. It’s identical across all the servers in a given replication setup. Though our code supports GTID, the version of MySQL we use does not. Hence, we needed an alternative approach to store the state that could be easily translated across the entire replication setup, which motivated us to piggyback on Yelp’s heartbeat daemon. This python daemon is responsible for sending periodic heartbeat database updates that consists of a serial number and a timestamp. This is then replicated to all other replicas. The MySQLStreamer takes the heartbeat serial number and timestamp and attaches the log file name and log position it is currently working with and stores that in the global_event_state table. If the current master fails for some reason, a batch finds the log file and the log position from the new master using the heartbeat serial number and heartbeat timestamp.
MYSQL_DUMPS
Stores the schema dump of the schema tracker database for restoring the database to a stable state after a failure.
How does the MySQLStreamer work?
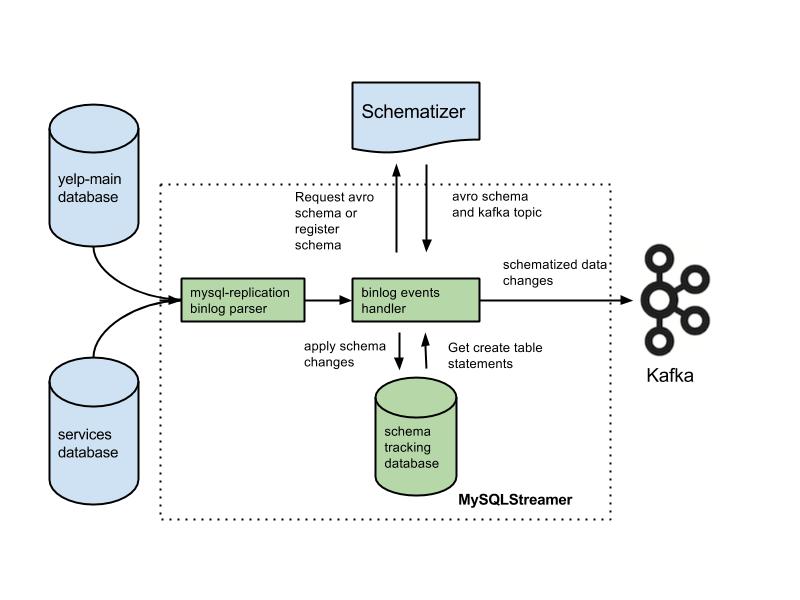
As the MySQLStreamer starts, it acquires a Zookeeper lock before it initiates processing on any of the incoming events. This step is necessary to prevent multiple instances of the MySQLStreamer from running on the same cluster. The problem with multiple instances running on the same cluster is that replication is inherently serial. In some applications we want to maintain order within and between tables, so we prevent multiple instances from running, preserving order and preventing message duplication.
As we have previously discussed, the MySQLStreamer receives events from the source database (Yelp database as seen in the figure above) via the binlog parser. If the event is a data event then the table schema for that event is extracted and sent to the Schematizer service. This service then returns the corresponding Avro schema and a Kafka topic. The Schematizer service is idempotent. It will return the exact same Avro schema and topic if it’s called with the same create table statement multiple times.
Data events are encoded with the received Avro schema and published to Kafka topics. The data pipeline’s Kafka Producer maintains an internal queue of events to be published to Kafka. If a schema event is received from the binlog parser, the MySQLStreamer first flushes all the events already present in the internal queue and then takes a checkpoint for the purposes of recovery in case of a failure. It then applies the schema event on the schema tracker database.
Failure handling of data events is slightly different compared to schema events. We checkpoint before processing any data event, and continue checkpointing as we publish batches of messages successfully. We trust successes, but never failures. If we encounter a failure we recover from it by inspecting the last checkpoint and Kafka high watermarks, and publishing only those messages that were not successfully published previously. On the Kafka side, we require acks from all in-sync replicas, and run with a high min.isr setting, trading availability for consistency. By methodically verifying and recovering from failures, we’re able to ensure that messages are published exactly once.
Bootstrapping a Topic
Yelp was founded in 2004. Many of the most interesting tables have existed for nearly as long as Yelp. We needed to find a way to bootstrap a Kafka topic with existing table contents. We engineered a procedure that can perform a consistent topic bootstrap while still processing live replication events.
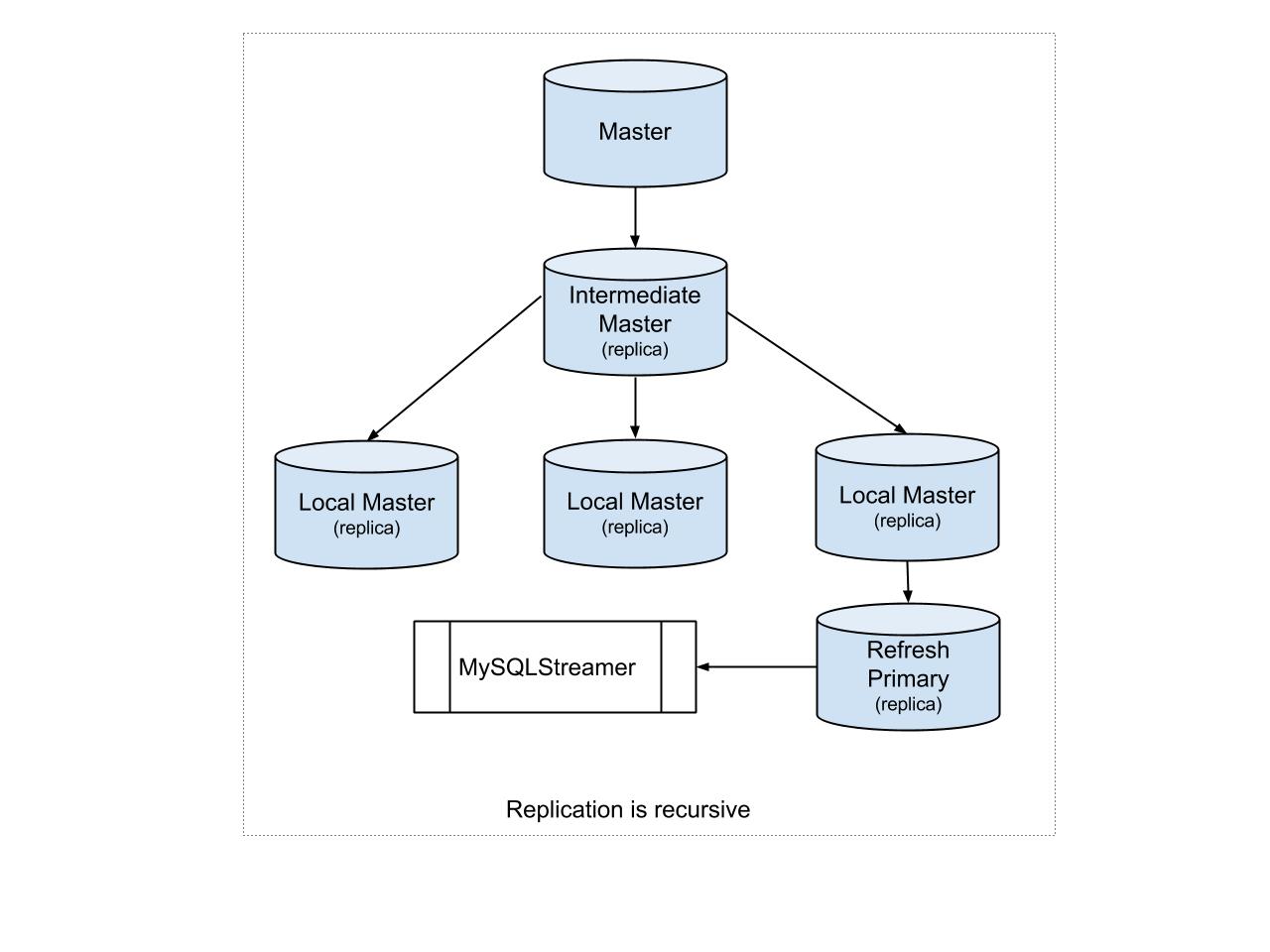
Before we talk about bootstrapping, let us see what the actual database replication topology looks like. Referencing the figure above, we notice there exists a master and a replica of master called the intermediate master. There are other replicas of intermediate master called local masters. The MySQLStreamer is connected to a replica called refresh primary which in turn is a replica of one of the local master. The refresh primary is setup with row-based replication whereas all other replicas run statement-based replication.
Bootstrapping is initiated by creating a table like the original table we want to bootstrap on the MySQLStreamer’s refresh primary, using MySQL’s blackhole engine.
blackhole_table = create_blackhole_table(original_table)
while remaining_data(original_table):
lock_table(original_table)
copy_batch(original_table, blackhole_table, batch_size)
unlock_table(original_table)
wait_for_replication()
drop_table(blackhole_table)
Pseudo-code Bootstrap Process
The blackhole engine is like the /dev/null of database engines. The primary reason we chose to use the blackhole engine is because writes to blackhole tables aren’t persisted, but are logged and replicated. This way we’re recreating the binary logs of the original table and not worry about storing the duplicate table.
Once we’ve created the blackhole table, we lock the original table to prevent any data changes during the bootstrap process. We then copy rows from the original table to the blackhole table in batches. As shown in the figure, the MySQLStreamer is connected to one of the leaf clusters. This is because, we do not want any change triggered by the bootstrap logic to trickle down to every child cluster. But we do want the original table to be updated with the latest changes during bootstrapping hence, between batches, we unlock the original table and wait for replication to catch up. Locking the original table can cause replication from a local master to the replica (refresh primary) to stall , but it guarantees that the data we’re copying into the blackhole table is consistent at that point in replication. By unlocking and allowing replication to catch up, the bootstrap process naturally throttles itself. The process is very fast, since the data never leaves the MySQL server. The replication delay we’re causing is measured in milliseconds per batch.
All of the complexity of this process happens in the database. Inside the MySQLStreamer, our code simply treats inserts into specially named blackhole tables as Refresh events on the original table. Refresh events are interleaved in topics with normal replication events, as regular Insert, Update, and Delete events are published during the bootstrap. Semantically, many consumers treat Refresh events like upserts.
The Takeaway
Engineering time is valuable. A good principle for engineers to follow is “Any repetitive task should try to be automated”. For Yelp to scale we had to engineer a single, flexible piece of infrastructure that would help with a multitude of applications. With the data pipeline we can index data for search, warehouse data and share transformed data with other internal services. The data pipeline proved to be immensely valuable and was a positive step towards achieving the required automation. The MySQLStreamer is a cardinal part of the data pipeline that scrapes MySQL binary logs for all the change events and publishes those changes to Kafka. Once the changes are in the Kafka topics, it’s easy for the downstream consumers to utilize them based on their individual use case.
Acknowledgements
Thanks to the entire Business Analytics and Metrics (B.A.M) team, the Database Engineering team and everyone that helped build the MySQLStreamer: Abrar Sheikh, Cheng Chen, Jenni Snyder and Justin Cunningham.
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
Build Real-time Data Infrastructure at Yelp
Want to build next-generation streaming data infrastructure? Apply to become an Infrastructure Engineer today.
View Job