Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift

-
Jacob Park, Software Engineering Intern
- Apr 12, 2018
Since Yelp introduced its real-time streaming data infrastructure, “Data Pipeline”, it has grown in scope and matured vastly. It now supports some of Yelp’s most critical business requirements in its mission to connect people with great local businesses.
Today, it has expanded into a diverse ecosystem of connectors sourcing data from Kafka and MySQL, and sinking data into Cassandra, Elasticsearch, Kafka, MySQL, Redshift, and S3. To ensure that the whole ecosystem is functioning correctly, Yelp’s Data Pipeline infrastructure is continually growing its repertoire of reliability techniques such as write-ahead logging, two-phase commit, fuzz testing, monkey testing, and black-box auditing to verify the behavior of various components within the ecosystem.
Black-box auditing is an essential technique we employ to verify the behavior of every individual component within Yelp’s Data Pipeline infrastructure. It’s particularly useful because it does not rely on any assumptions about the internals of the components. In this post, we’ll explore how we designed a novel algorithm to black-box audit one of our most critical flows: replicating data from MySQL into Redshift.
MySQLStreamer, Application Specific Transformer, and Redshift Connector
Before explaining why we designed a novel algorithm to black-box audit end-to-end replication integrity between MySQL and Redshift, it is important to provide a bit of context on how replication between MySQL and Redshift is achieved in Yelp’s Data Pipeline infrastructure:
- The MySQLStreamer is a single leader, producing Kafka messages from the binary log of a MySQL database.
- The Application Specific Transformer is an intermediary stage consuming from and producing to Kafka, essentially, as one link in the asynchronous chain replication from MySQL into Redshift.
- The Redshift Connector is a collection of many workers consuming Kafka messages into a Redshift cluster.
In this design, we chose to make the replication between MySQL and Redshift eventually consistent by favoring the availability of a MySQL database, instead of requiring acknowledgements from all downstream consumers, ultimately opting for asynchronous chain replication.
In the face of transient logical errors and machine failures, we needed a way to prove replication was reliable between MySQL and Redshift. To address this concern, we designed a black-box auditing algorithm to build trust that the replication was consistent (or eventually consistent to be specific).
Anti-Entropy Repair in Dynamo Systems
How do other eventually consistent systems verify their data is actually eventually consistent? Dynamo systems such as Cassandra and Riak utilize a process called anti-entropy repair that incorporates Merkle trees to verify and update all replicas, ultimately ensuring that the systems are eventually consistent.
The anti-entropy repair algorithm can be summarized by the following steps:
- Snapshot each replica
- Partition each replica
- Hash each replica (e.g. compact Merkle trees)
- Repair each inconsistent partition by the equality of their hashes
This algorithm is very resource intensive in terms of disk I/O as it aims to minimize network utilization. As a result, Cassandra provides incremental repair that utilizes an anti-compaction process that segregates repaired and unrepaired data to successively reduce the cost in performing repairs.
What’s Wrong with Anti-Entropy Repair in Dynamo Systems?
Why didn’t we use anti-entropy repair to black-box audit end-to-end replication integrity between MySQL and Redshift? As alluded to in the prior section, anti-entropy repair is highly effective in systems which can segregate their data into partitions which are repaired and unrepaired.
At Yelp, there is no universal method of snapshotting MySQL and Redshift to align their snapshots for proper segregation into repaired and unrepaired partitions for black-box auditing with anti-entropy repair.
Furthermore, as propagation delay in an eventually consistent system reduces the integrity between replicas, a uniform distribution of writes can potentially invalidate all partitions from utilizing hashes for equality, regardless of the size of the partitions.
Thus, the anti-entropy repair algorithm would state the data between MySQL and Redshift to be fully inconsistent unless a one-to-one projection of the data to hashes was saved to disk, which is a prohibitively expensive solution.
Ultimately, we need to innovate or invent an algorithm that migrates away from a binary notion of replication integrity, utilizing hashes for equality, to a continuous notion of replication integrity utilizing hashes for similarity. This shift relaxes the effects of propagation delay and uniformly distributed writes from invalidating partitioning. With partitioning, the algorithm can execute at scale, with a trade-off in accuracy.
New and Improved Anti-Entropy Repair for Replication between MySQL and Redshift
To solve the issues of the original anti-entropy repair algorithm, our algorithm to black-box audit end-to-end replication integrity between MySQL and Redshift can be succinctly summarized by the following steps:
- Snapshot each replica
- Partition each replica
- Hash each replica for equality testing
- Hash each replica for similarity testing
- Identify each inconsistent partition by their equality testing hashes and their similarity testing hashes
Overall, this algorithm is very similar to the original anti-entropy repair algorithm except for the addition of hashing for similarity testing.
Hashing for Similarity Testing?
To hash for similarity testing, we opted to use MinHash to estimate the Jaccard similarity coefficient between two sets, primarily MySQL and Redshift.
Before diving into MinHash, it is important to explain the Jaccard similarity coefficient. It is a measure of similarity between two sets defined by the cardinality of their intersection divided by the cardinality of their union. A coefficient of 0 represents that the two sets are disjoint, while a coefficient of 1 represents that the two sets are equivalent. To minimize bias when calculating the Jaccard similarity coefficient, the cardinalities between the two sets should be approximately equivalent.
Finally, MinHash is a technique that estimates the Jaccard similarity coefficient between two sets, by the observation that the Jaccard similarity coefficient is equivalent to the probability of a set of minimum hashes generated from k different hash functions being equivalent across the two sets. This estimation has an expected error of O(1/\sqrt(k)).
Too Succinct, Where’s the Details?
In practice, our algorithm to black-box audit the end-to-end replication integrity between MySQL and Redshift is primarily expressed in SQL, to score whether each partition common between MySQL and Redshift is consistent.
Using SQL, the algorithm benefits from data locality to be network efficient by generating scores from MySQL and Redshift in sub-linear or constant space. Furthermore, Redshift’s distributed query execution engine executes the SQL as a highly-parallelized MapReduce job that executes in seconds.
More Details Through an Example
The following example will provide a sample set of SQL statements that accomplishes Steps 1 to 4 of the algorithm to generate hashes for equality testing and hashes for similarity testing. These hashes will be consumed by another process that will illustrate how inconsistent partitions are identified.
MySQL and Redshift Datasets
For this example, MySQL and Redshift share a key-value structured table of 32 rows in which 2 rows differ between MySQL and Redshift.
mysql> SELECT * FROM `MASTER`;
+------+-------------+
| id | text |
+------+-------------+
| 0 | ALPHA |
| ... | ... |
| 16 | QUEBEC |
| ... | ... |
| 24 | YANKEE |
| ... | ... |
| 31 | CONSECTETUR |
+------+-------------+
redshift> SELECT * FROM `SLAVE`;
+------+-------------+
| id | text |
+------+-------------+
| 0 | ALPHA |
| ... | ... |
| 16 | JPARKIE | -- Different From MySQL.
| ... | ... |
| 24 | JPARKIE | -- Different From MySQL.
| ... | ... |
| 31 | CONSECTETUR |
+------+-------------+
SQL Statements
The following SQL statements can be executed on MySQL and on Redshift to generate hashes for equality testing and similarity testing per partition.
START TRANSACTION WITH CONSISTENT SNAPSHOT;
SELECT
`partition`,
MIN(`partition_key`) AS `min_partition_key`,
MAX(`partition_key`) AS `max_partition_key`,
COUNT(`partition_key`) AS `count`,
SUM(CAST(CONV(SUBSTRING(`hash`, 1, 8), 16, 10) AS UNSIGNED)) AS `signature_0`,
SUM(CAST(CONV(SUBSTRING(`hash`, 9, 8), 16, 10) AS UNSIGNED)) AS `signature_1`,
SUM(CAST(CONV(SUBSTRING(`hash`, 17, 8), 16, 10) AS UNSIGNED)) AS `signature_2`,
SUM(CAST(CONV(SUBSTRING(`hash`, 25, 8), 16, 10) AS UNSIGNED)) AS `signature_3`,
MIN(`partial_hash_0`) AS `min_hash_0`,
MIN(`partial_hash_1`) AS `min_hash_1`,
MIN(`partial_hash_2`) AS `min_hash_2`,
MIN(`partial_hash_3`) AS `min_hash_3`
FROM (
SELECT
`partition_key`,
`partition`,
`hash`,
((((`seed` * 1285533145) + 1655539436) % 2305843009213693951) & 2147483647) AS `partial_hash_0`,
((((`seed` * 1350832907) + 492214603) % 2305843009213693951) & 2147483647) AS `partial_hash_1`,
((((`seed` * 1235092432) + 1629043653) % 2305843009213693951) & 2147483647) AS `partial_hash_2`,
((((`seed` * 176256801) + 205743474) % 2305843009213693951) & 2147483647) AS `partial_hash_3`
FROM (
SELECT
`partition_key`,
`partition`,
`hash`,
CAST(CONV(SUBSTRING(`hash`, 25, 8), 16, 10) AS UNSIGNED) AS `seed`
FROM (
SELECT
`id` AS `partition_key`,
FLOOR(`id` / 8) AS `partition`,
MD5(CONCAT(COALESCE(`id`, 'NULL'), COALESCE(`text`, 'NULL'))) AS `hash`
FROM `MASTER`
) AS `PARTITION_HASH_SUBQUERY`
) AS `PARTITION_HASH_SEED_SUBQUERY`
) AS `PARTITION_HASH_PARTIAL_HASH_SUBQUERY`
GROUP BY `partition`
ORDER BY `partition`;
COMMIT;
The SQL statements accomplish the following actions:
- Start a transaction for a consistent snapshot
- Partition each row by the partition key into fixed-sized partitions
- Map each row of the table to a MD5 hash
- Map 32-bits of each MD5 hash into a seed
- Permute
k=4partial hashes from the seed with theh(x) - mod(a * x + b, p) ^ mhash family - Split each MD5 hash into a vector of signatures
- Calculate the minimum partition key for each partition
- Calculate the maximum partition key for each partition
- Calculate the number of partition keys for each partition
- Calculate the vector sum of the signatures for each partition to be the partition’s hashes for equality testing
- Calculate the
k=4MinHash values for within each partition to be the partition’s hashes for similarity testing
Step 1: Snapshot each Replica
Action 1 illustrates how each replica is snapshot by utilizing consistent-read semantics provided by a transaction with a consistent snapshot.
Step 2: Partition each Replica
Action 2 illustrates how each replica is partitioned by floored division with fixed-sized partitions on the partition key.
Step 3: Hash each Replica for Equality Testing
Actions 3, 6, and 10 illustrate how all the row-level hashes of a partition are mixed by vector summation to generate a partition-level hash to be used for equality testing.
Step 4: Hash each Replica for Similarity Testing
Actions 4, 5, and 11 illustrate how all the row-level hashes are seeded to be permuted by the h(x) - mod(a * x + b, p) ^ m hash family into partition-level, k=4 MinHash values to be used for similarity testing.
MySQL and Redshift Results
The following tables lists the results of executing the SQL statements on MySQL and on Redshift. The green highlight illustrates that the values are equivalent between MySQL and Redshift. The red highlight illustrates that the values are not equivalent between MySQL and Redshift.
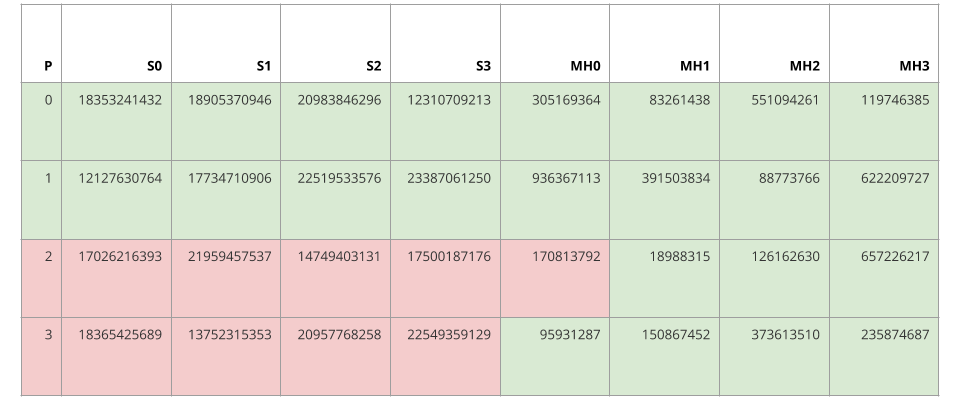
Example MySQL Results
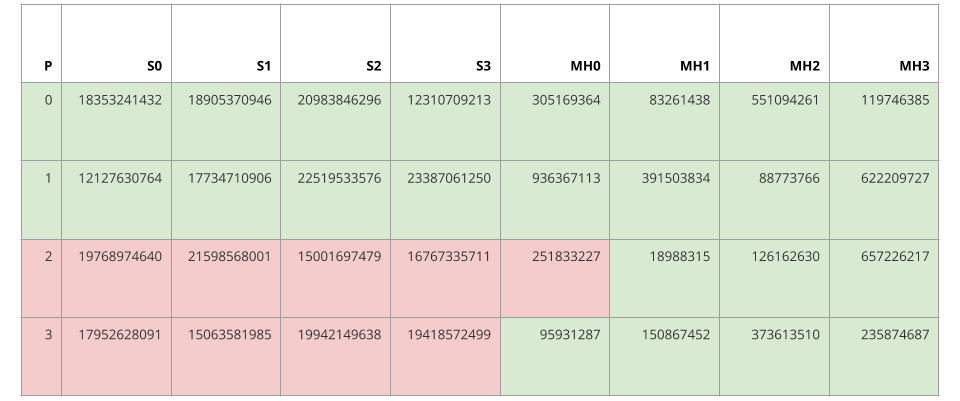
Example Redshift Results
Analyzing MySQL and Redshift Results
Utilizing the signatures S0, S1, S2, and S3, which were generated for equality testing, we can state the following with confidence:
- Partitions 0 and 1 are equivalent between MySQL and Redshift
- Partitions 2 and 3 are different between MySQL and Redshift
If these absolute statements were accepted at face value, then 50 percent of the data within Redshift would need to be repaired. In actuality, only 6 percent of the data needs to be repaired. This discrepancy is too draconian if we believe that MySQL and Redshift primarily diverge due to propagation delay.
Luckily, the MinHash values MH0, MH1, MH2, and MH3, which were generated for similarity testing, can be utilized to relax such harsh conclusions by introducing some uncertainty. If we apply the MinHash technique to Partitions 2 and 3, then we would respectively estimate the Jaccard similarity coefficients to be 3/4 or 0.75 and 4/4 or 1.0, both with an expected error of 0.5. These estimated Jaccard similarity coefficients suggest that Partitions 2 and 3 are not drastically different between MySQL and Redshift. Hopefully, such a suggestion would relax operators from eagerly repairing transiently divergent partitions.
Scoring Consistency between MySQL and Redshift
In practice, to effectively respond to a black-box audit of the end-to-end replication integrity between MySQL and Redshift, we use a bounded score of their consistency/similarity such that we can escalate incident response if the bounded score falls below desired thresholds. The following is the formula we used to calculate the bounded score.
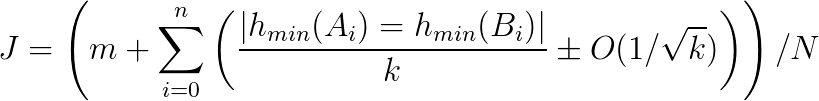
Consistency Scoring Formula
The following list explains all the symbols within the formula.
- Let
Jrepresent the similarity between a MySQL table and a Redshift table - Let
Arepresent the data within the MySQL table - Let
Brepresent the data within the Redshift table. - Let
Nrepresent the total number of partitions shared between the MySQL table and the Redshift table - Let
mrepresent the number of partitions where their signatures are equal - Let
nrepresent the number of partitions where their signatures are not equal - Let
h_minrepresent a permutation in the MinHash of theith partition - Let
krepresent the number of permutations - Let
|h_min(A_i) = h_min(B_i)|represent the number of equivalent permutations
This score is akin to the Jaccard similarity coefficient. Thus, for the previous example, the actual Jaccard similarity coefficient between MySQL and Redshift is 30/34 or 0.882. Meanwhile, its bounded score is 0.938 bounded by 0.688 and 1.0. Although 0.938 is fairly close to 0.882, such a wide bounded score is unsettling. In practice, we utilize higher values of k to restrict the bounds for increasing accuracy for a trade-off in network efficiency and time efficiency.
Conclusion
At Yelp, we use either the old or the new anti-entropy repair algorithm to audit end-to-end replication integrity between many MySQL and Redshift tables. By analyzing the distribution of writes per table, we opt to use one algorithm over the other, optimizing accuracy versus performance.
These algorithms deliver daily reports that state the overall similarity scores between MySQL and Redshift tables. If an overall similarity score is below a specified threshold, its report lists all the divergent partitions between a pair of MySQL and Redshift tables. These reports empower operators to investigate and resolve potential problems within the Data Pipeline infrastructure.
To conclude, I hope you’ve enjoyed learning how we designed our own black-box algorithm to verify end-to-end replication integrity between MySQL and Redshift and encourage you to explore how your own systems can benefit from the use of black-box auditing!
Aside: Yelp Internship Program
The work discussed within this Yelp Engineering Blog post was completed as one of my projects during my internship with Yelp at the San Francisco office in Summer 2017. Yelp has a phenomenal internship program in which interns can join a wide breadth of teams to work on exciting and relevant work as if you were a full-time software engineer. Yelp’s commitment to help interns enjoy their stay in the company and the city is fantastic. At the time of writing this post, I am completing my third internship with Yelp. For any students actively looking for internships, visit https://www.yelp.com/careers/teams/college-engineering.
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2