Open-Sourcing Yelp's Data Pipeline

-
Matt K., Software Engineer
- Nov 17, 2016
![]()
For the past few months we’ve been spreading the word about our shiny new Data Pipeline: a Python-based tool that streams and transforms real-time data to services that need it. We wrote a series of blog posts covering how we replicate messages from our MySQL tables, how we track schemas and compute schema migrations, and finally how we connect our data to different types of data targets like Redshift and Salesforce.
With all of this talk about the Data Pipeline, you might think that we here at Yelp are like a kid with a new toy, wanting to keep it all to ourselves. But unlike most kids with new toys, we like to share–which is why we’ve decided to open-source the main components of our pipeline, just in time for the holiday season.
Without further ado, here are some stocking-stuffers for the upcoming holidays:
- The MySQL Streamer tails MySQL binlogs for table changes. The Streamer is responsible for capturing individual database changes, enveloping those changes into Kafka messages (with an updated schema if necessary), and publishing to Kafka topics.
- The Schematizer service tracks the schemas associated with each message. When a new schema is encountered, the Schematizer handles registration and generates migration plans for downstream tables.
- The Data Pipeline clientlib provides an easy-to-use interface for producing and consuming Kafka messages. With the clientlib, you don’t have to worry about Kafka topic names, encryption, or partitioning your consumer. You can think at the level of tables and data sources, and forget the rest.
- The Data Pipeline Avro utility package provides a Pythonic interface for reading and writing Avro schemas. It also provides an enum class for metadata like primary key info that we’ve found useful to include in our schemas.
- The Yelp Kafka library extends the kafka-python package to provide features such as a multiprocessing consumer group. This helps us to interact with Kafka in a high-performance way. The library also allows our users to discover information about the multi-regional Kafka deployment at Yelp.
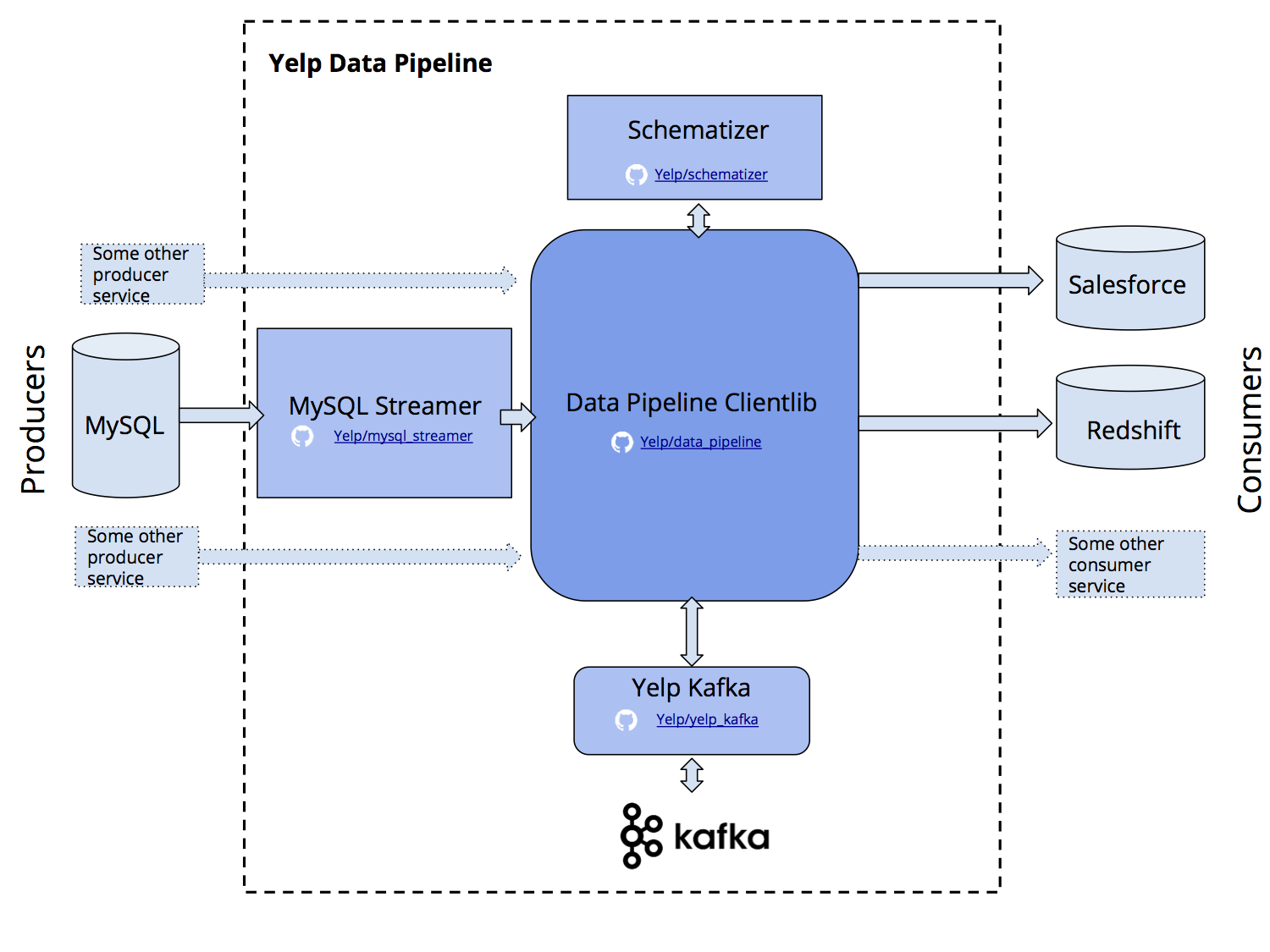
A diagram of different components in the Data Pipeline. Individual services are shown with square edges, while shared packages have rounded edges.
Each of these projects is a Dockerized service that can easily be adapted to fit your infrastructure. We hope that they’ll prove useful to anyone building a real-time streaming application with Python.
Happy hacking, and may your holidays be filled with real-time data!
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
Build Real-time Data Infrastructure at Yelp
Want to build next-generation streaming data infrastructure? Apply to become an Infrastructure Engineer today.
View Job