PaaStorm: A Streaming Processor

-
Matt K., Software Engineer
- Aug 25, 2016
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
Trouble in Paradise
Back in 2010, Yelp open-sourced MRJob, a framework to run big MapReduce jobs on top of AWS infrastructure. Engineers at Yelp used MRJob to support everything from ad delivery to translation. MRJob proved to be a powerful tool for computation and aggregation on our existing rich dataset.
Unfortunately, as the number of services using MRJob expanded, running and scheduling jobs became more complex. Since most jobs depended on other upstream jobs, the whole system had to be arranged in a topology. MapReduce jobs were never designed to be real-time, so the topology had to be scheduled daily. What’s worse, if an upstream job failed, downstream systems would break, and backfilling bad data required an intrepid detective to determine exactly which jobs had to be rerun, and in what order, before data could be updated.
Inquiring minds started to inquire: how can we perform computations and transformations in a more efficient way? In particular, we’d like to support dependencies between different data transformations in a complex flow, where schema changes and upstream issues are handled gracefully. We’d also like to have the system run at (or close to) real-time. That way, the system can be used for business analytics and metrics. In other words, we need a streaming processor.
An off-the-shelf solution like Storm, the computation system, would have been ideal. But since Python isn’t well-supported by many stream-processing frameworks, integrating the rest of our backend code with Storm or other off-the-shelf systems would have been painful.
We built Pyleus first–an open-source framework that aimed to let developers process and transform data in Python. Pyleus still relied on Storm under the hood. Build times were long; the topology was slow. Twitter Heron had been announced, and we’d been seeing many of the same issues that they cited. We didn’t want to run dedicated Storm clusters if we could rely instead on PaaSTA, Yelp’s Platform-as-a-Service to deploy services, which is much more versatile.
In July of 2015, a group of engineers began work on a new version of our Data Warehouse, which was facing the typical issues of scaling and performance. At first they wanted to use Pyleus to transform data in preparation for copying it to Redshift. Then they realized that deploying a full Storm cluster to run simple Python logic was unnecessary–a Python-based stream processor, deployed using Yelp’s in-house platform for launching services, would suffice. The design for the processor was based on Samza, aiming to provide a simple interface for transformations with a “process message” method.
The engineers used Hackathon 17 to build a prototype for the stream processor running on PyPy, and thus PaaStorm was born.
What’s in a Name?
PaaStorm’s name is a mashup of PaaSTA and Storm. So what does PaaStorm actually do? To answer that, let’s go back to the basic architecture of the Data Pipeline:
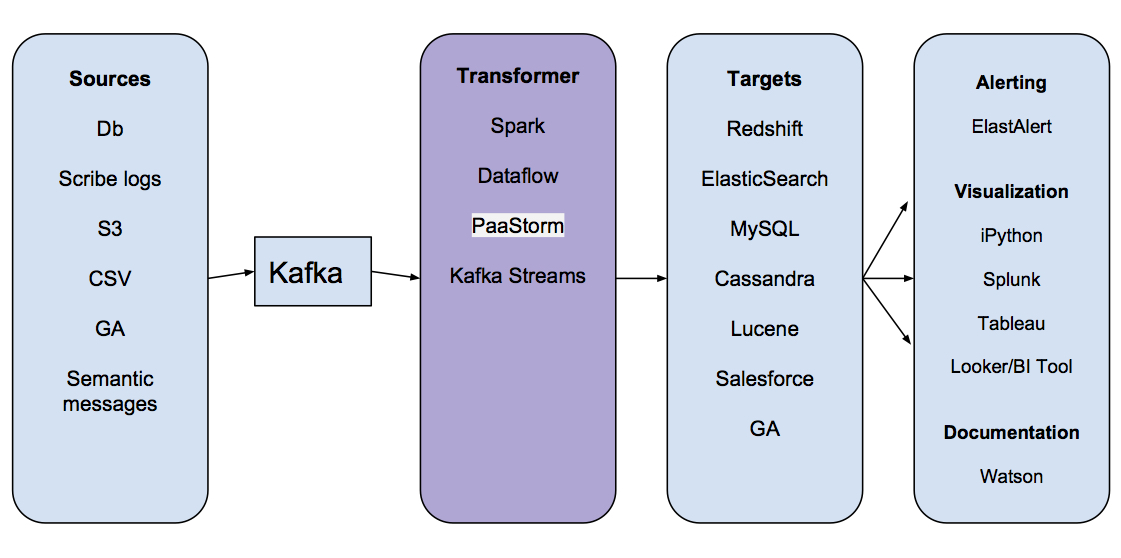
Focusing on the “Transformer” step, we can see that most messages stored in Kafka aren’t ready to be loaded into a target yet. Consider a target Redshift cluster storing data for ad delivery. The ad delivery cluster might want only a single field from an upstream source (say, the average rating of a business), or it might need to perform some aggregation or computation on the data. It would waste storage space and decrease performance if the ad delivery Redshift cluster had to store the entire upstream data source.
In the past, service owners wrote complex MRJobs to transform their data before inserting it into their target datastore. However, those MRJobs faced the performance and scaling issues explained above. One of the benefits provided by the Data Pipeline is that a consumer can have data in exactly the form it needs, regardless of how the upstream data source used to look.
Reducing Boilerplate
In principle, we could let each individual consumer figure out their own transformations to get data in the form they want. For example, the ad delivery team could write a transformer that strips out review averages from business data in Kafka, and then they could own that transformation service as well. That strategy works fine at first, but eventually we hit problems of scale.
We wanted to provide a transformation framework for a few reasons:
- Many transformations are common and can be used by multiple teams (e.g., expanding flags into meaningful columns).
- There is a lot of boilerplate code surrounding transformations (e.g., connecting to and from data sources and targets, saving state, monitoring throughput, recovering from failure) that need not be copied in each service.
- Transforming data needs to happen as fast as data is coming in (i.e., on a stream basis), in order to maintain a real-time system for data processing.
The natural way to reduce boilerplate is to provide an interface for transformations. The interface defines the minimum amount of logic needed to specify a transformation. Then, the rest of the work is taken care of by our streaming framework.
Kafka as a Message Bus
PaaStorm started off specifically as a Kafka-to-Kafka transforming framework, although it has since grown to allow other endpoints. Using Kafka as the endpoints for PaaStorm makes things simpler: each interested service can register as a consumer to any transformed or raw topic, without regard to who “created” a transformed topic, reading new messages as they arrive. The transformed data is persisted according to Kafka’s retention policy. Since Kafka is a pub-sub system, downstream systems can consume data whenever they’re ready.
Taking the World by Storm
So how do we visualize our set of Kafka topics, once PaaStorm has entered the picture? Since some topics feed into other ones in a source-to-target way, we can think of our topology as a directed acyclic graph:
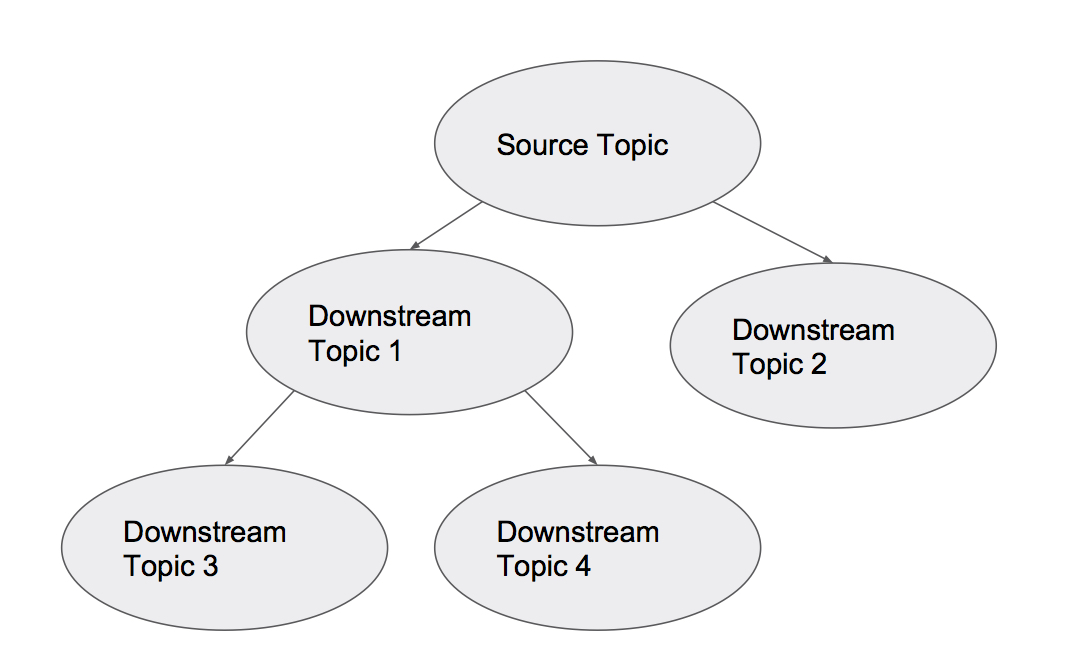
Each node represents a Kafka topic; arrows represent data transformations provided by PaaStorm. The name ‘PaaStorm’ should make more sense now: similar to Storm, PaaStorm provides real-time transformation from stream sources (like Spouts) via transformation components (like Bolts).
The Eye of the Storm (or, PaaStorm Internals)
PaaStorm’s core abstraction is called a Spolt (a cross between Spout and Bolt). As the name suggests, the Spolt interface provides two important things: a source for incoming messages, and a way to process the messages in that source in some way.
At its most basic level, a Spolt looks like this:
class UppercaseNameSpolt(Spolt):
“““Pseudocode implementation of a simple Spolt.”””
spolt_source = FixedTopics(“refresh_primary.business.abc123efg456”)
def process_message(message):
new_message_data = message.payload_data
new_message_data[‘uppercase_name’] = new_message_data[‘name’].upper()
yield CreateMessage(
schema_id=2,
payload_data=new_message_data
)
This Spolt takes each message in the topic “refresh_primary.business.abc123efg456” and adds an extra field, an uppercased version of the ‘name’ column in the original message. The Spolt then passes on the new version of the message.
It’s worth noting that messages in the Data Pipeline are immutable. In order to yield a modified message, a new object has to be created. Also, because we’re adding a new field to the payload (i.e., the message is gaining an ‘uppercase_name’ column), the schema for the new message is different. In production, a message’s schema_id would never be hardcoded. Instead, we rely on the Schematizer service to register and provide the proper schema for a modified message.
One last note: the Data Pipeline clientlib provides several nuanced ways of setting a ‘spolt_source’ with combinations of namespaces, topic names, source names, and schema_ids. That way it’s easy for a given Spolt to group together exactly the sources it needs and read from only those. For more detail, check out the Schematizer blog post.
But Wait, What Happened to Kafka?
You’ll notice that there is no code that actually interacts with Kafka topics in the Spolt above. That’s because in PaaStorm, all of the actual Kafka interfacing is handled by a runner instance (which is just called PaaStorm). The PaaStorm instance takes a Spolt and hooks it up to the proper sources and targets, takes care of feeding messages to the Spolt, and then publishes the messages that the Spolt yields to the correct topic.

Each PaaStorm instance is initialized with a Spolt. For example, the following command begins a process using the UppercaseNameSpolt from above:
PaaStorm(UppercaseNameSpolt()).start()
That means that someone interested in writing a new transformer can simply write a new subclass of Spolt, without having to modify the PaaStorm runner at all.
Internally, the PaaStorm runner’s main method is surprisingly simple. It looks like this (pseudocode):
with self.setup_counters(), Producer()
as producer, Consumer()
as consumer:
while self.running:
message = consumer.get_message()
if message:
self.increment_consumer_counter()
for downstream_message in spolt.process_message(message):
producer.publish(downstream_message)
self.increment_producer_count()
The runner starts off with some set-up: it initializes its producer and consumer, along with message counters. Next, it polls for a new message in the upstream topic. If it finds one, that message is processed through the Spolt. The Spolt in turn yields one or more transformed messages, which the producer publishes to the downstream topic.
A quick side-note: the PaaStorm runner also provides some utilities like consumer registration, and a heartbeat called “tick”–that way, if the Spolt needs to do something like flush its contents every so often, the tick can trigger it.
On State Saving
PaaStorm guarantees reliable recovery from failure. If there’s a crash, we want to restart by consuming from the correct offset. But, unfortunately, that offset is not necessarily the last message we consumed from the upstream topic. That is, we might have consumed some messages, but not actually published the transformed version of those messages.
The right place to restart is actually the place in the upstream topic corresponding to the last successful downstream message. Given the last message downstream, we have to figure out which upstream message it came from so we can restart from there.
To facilitate this, whenever PaaStorm’s Spolt processes a raw message, PaaStorm injects the Kafka offset of that raw message into the last transformed message. The transformed message, in turn, passes that offset to a callback in the producer. That way, we know which upstream offset corresponds to the furthest-along message in the downstream topic. Since the callback is only triggered when the producer successfully publishes the messages, the consumer can reliably commit the offset in the callback, knowing that the raw message has been successfully processed. If we crash, we can then restart from the upstream messages that have not been fully processed.
As seen in the above pseudocode, PaaStorm also counts the number of messages consumed and the number published. That way, interested users can check throughput on the upstream and downstream topics. This gives us free monitoring and performance checks for any given transformation. At Yelp, we send our stats to SignalFX:
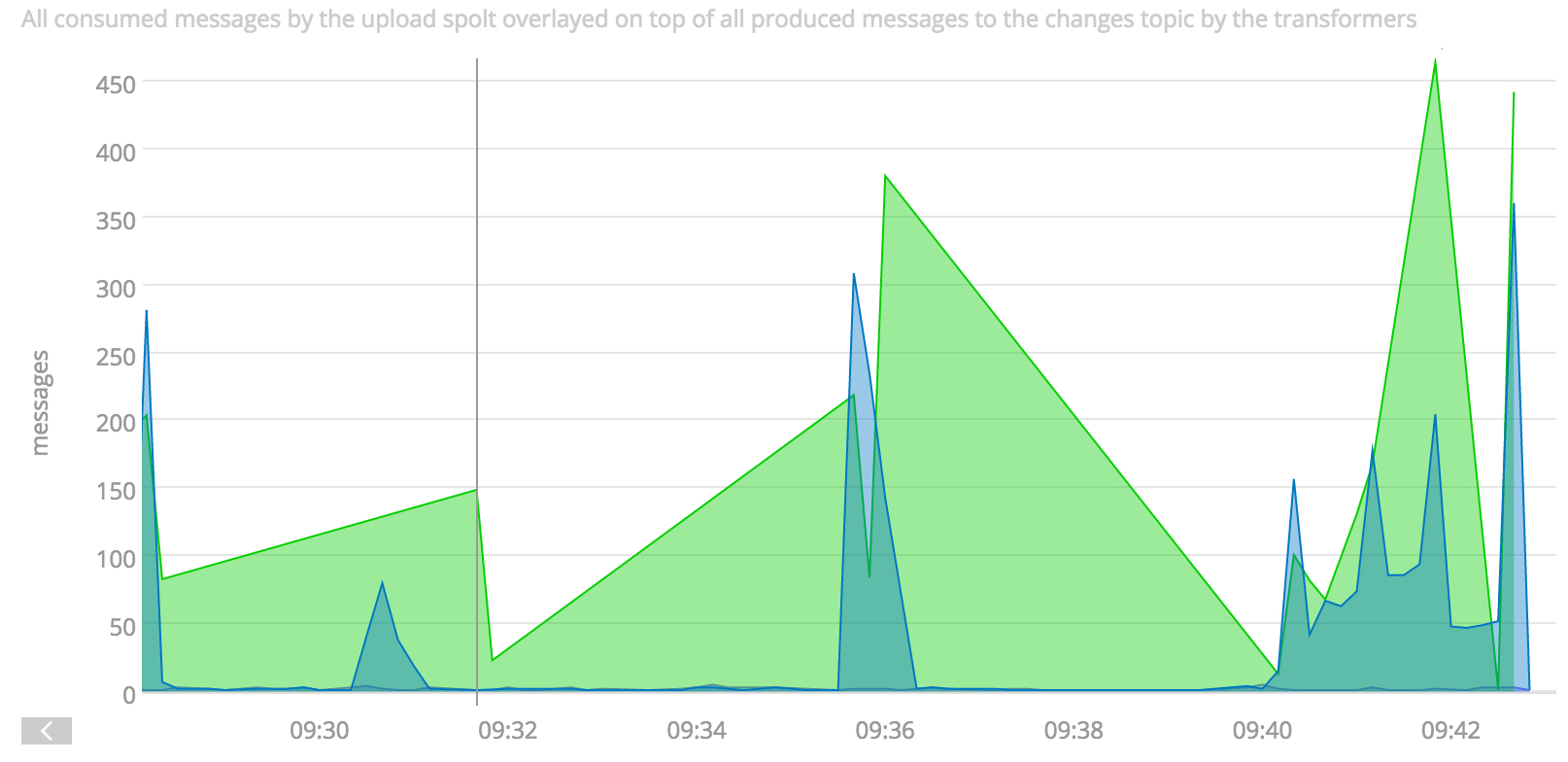
A SignalFX graph showing throughput for a producer and consumer in a Paastorm instance. In this case, incoming and outgoing messages are not matched.
One benefit of having separate counters for both the producer and consumer in PaaStorm is that we can overlay their throughputs to see where bottlenecks are occurring. Without this granularity, it can be hard to understand performance in the pipeline.
The Future of PaaStorm
PaaStorm provides two things: an interface and an implementation of a framework to support that interface. Although we don’t expect the interface of PaaStorm to change any time soon, there are some exciting incubating projects that aim to solve the transformation-and-connection problem. In the future, we’d love to replace the internals of PaaStorm with Kafka Streams or Apache Beam–the main blockers are the extent of Python support and support for the endpoints we care about most. Overall, we think of Paastorm as a bridge for Yelp to use until open-source Python stream-process projects mature.
Next Time on our Show
We’ve discussed how PaaStorm provides real-time transformation of data from sources into targets. PaaStorm was originally written as a Kafka-to-Kafka system. However, many internal services are not set up to directly consume from Kafka–instead, they load data into a datastore like Redshift or MySQL and perform service magic from there. Even after a transformation to get data in the right format, there’s a further connection step needed: the data has to actually be uploaded to a target data store.
As noted above, PaaStorm’s Spolt interface contains no reference to Kafka. In fact, with only a bit of modification, the Spolt can directly publish messages to targets other than Kafka. In a subsequent post, we’ll talk about Yelp’s Salesforce Connector–a service that uses PaaStorm to load data from Kafka into Salesforce in a high-volume, high-performance way.
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
Build Real-time Data Infrastructure at Yelp
Want to build next-generation streaming data infrastructure? Apply to become an Infrastructure Engineer today.
View Job