Streaming Messages from Kafka into Redshift in near Real-Time

-
Shahid C., Software Engineer
- Oct 17, 2016
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
The Yelp Data Pipeline gives developers a suite of tools to easily move data around the company. We have outlined three main components of the core Data Pipeline infrastructure so far. First, the MySQLStreamer replicates MySQL statements and publishes them into a stream of schema-backed Kafka topics. Second, the Schematizer provides a centralized source of truth about each of our Kafka topics. It persists the Avro schema used to encode the data in a particular topic, the owners of this data, and documentation about various fields. Finally, our stream processor, PaaStorm, makes it simple to consume from the Data Pipeline, perform transformations, and publish back into the Pipeline. Together, these tools can be used to get data to the people who care about it most.
Let’s focus on the “Targets” box in our diagram of the Data Pipeline. We can see that transformed data has to make its way into target data stores before services can use it.
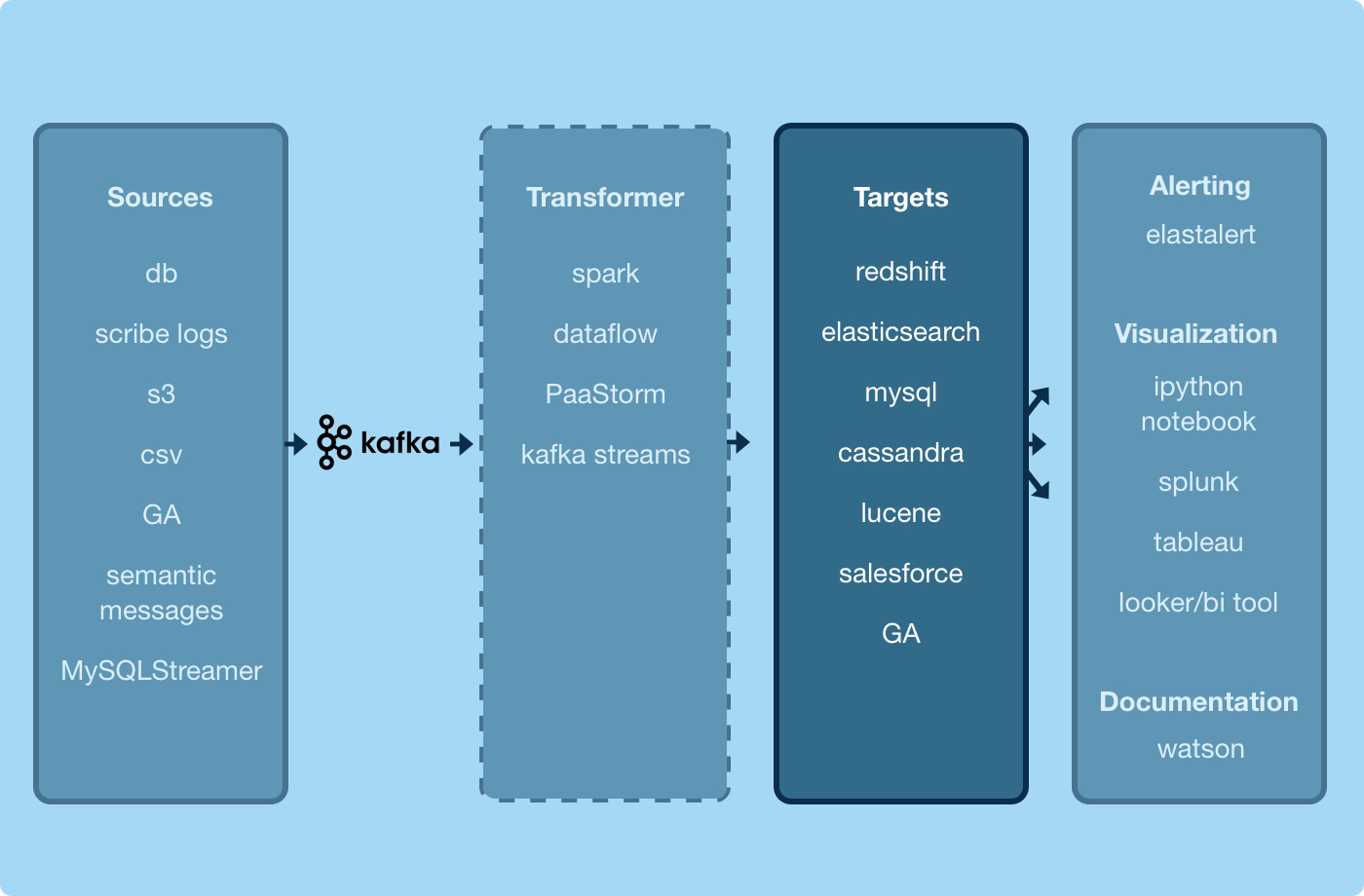
After abstracting much of the data transfer and transformation into the Data Pipeline infrastructure, we still have to connect data inside Kafka topics to the final data targets that services use. Each data target has its own idiosyncrasies and therefore requires a separate connector.
One of the most popular tools for doing analytics processing at Yelp is Redshift. It makes computation and aggregation easy with its column-based storage, and also scales well for performing complicated joins across tables with billions of rows. This makes Redshift a great data warehouse that analysts, data scientists, and engineers can use to interactively get answers to their complex data questions. This post will focus on a Redshift connector: a service that uses PaaStorm to read from Kafka and load data into a Redshift cluster.
The Data Warehouse is dead. Long live the Data Warehouse.
Our legacy ETL system served us for many years in moving data from our production application databases into our data warehouse. The diagram below outlines the high-level infrastructure of this system.
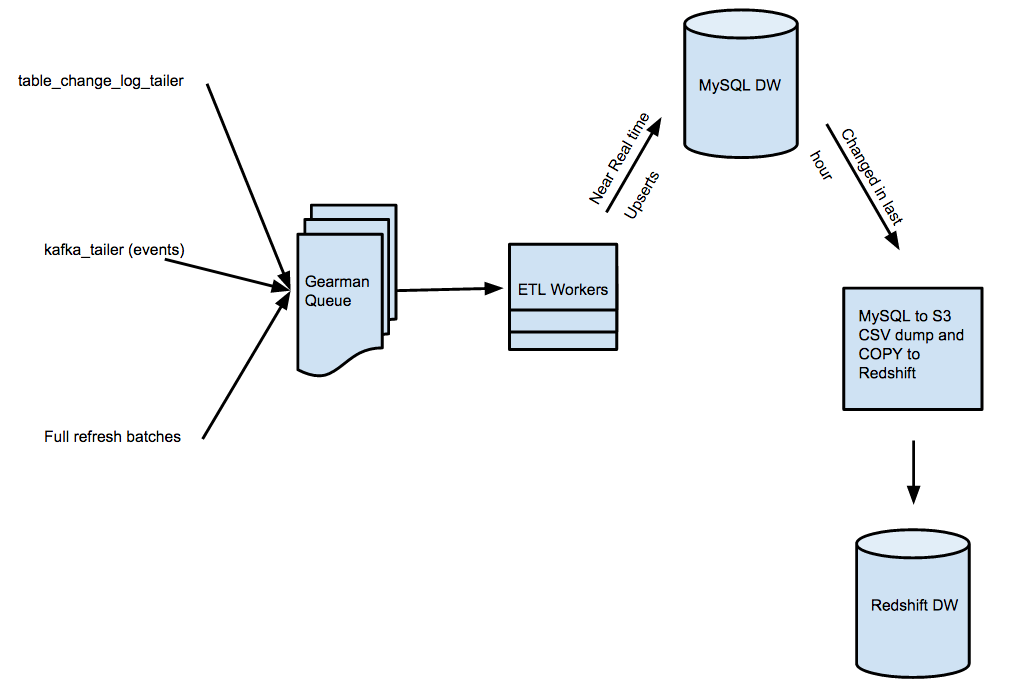
We had triggers on various tables in our MySQL databases listening for row changes. On each row change, we would write to a table changelog. A worker tailing this changelog would then create ETL tasks and put them on our job queue. Next, a pool of workers would perform transformations on each row according to custom logic written for each type of ETL. The output of these transformations would be written to MySQL, where they would sit temporarily before being dumped to S3 and finally COPY‘d into Redshift.
This system served us well for getting data from our MySQL databases into Redshift and, despite the complexity, it was made robust through various alerts and tooling we had built over the years. However, this system suffered from major drawbacks which made it hard to scale.
One of the most pressing concerns was that it would take precious developer time to write custom ETLs, their associated unit tests, get through code review, and push it into our monolithic code base. Furthermore, these code changes would often require performing schema migrations in both MySQL and Redshift across development and production clusters every time a field we cared about in the underlying source table changed.
Worst of all was that this system was designed to support a single Redshift cluster (i.e. the data warehouse) which meant that each team that managed a Redshift cluster would have to build their own systems for ingesting the data they cared about. We had reached a tipping point and desperately needed a new system that would better scale with the needs of our growing company.
The Redshift Connector: A New Hope
To address our issues with our legacy Redshift ingestion systems, the new system needed the following features:
- Ingestion of new tables without writing custom ETL
- Automated schema migrations
- Low latency ingestion
- Graceful recovery from failures
- Idempotent writes
- Support for multiple Redshift clusters
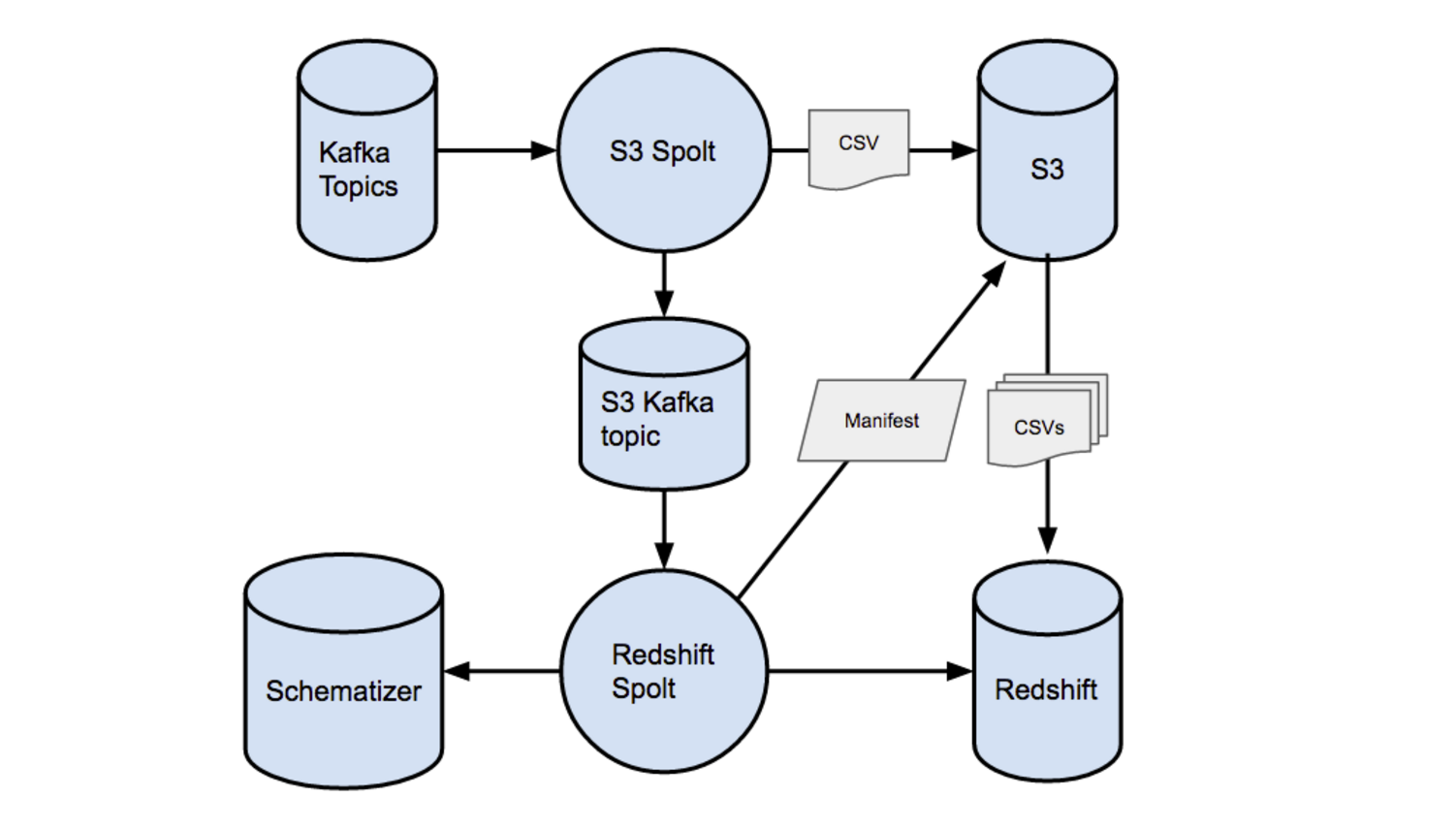
From experience with our legacy ETL system, we knew that Redshift was great for performing bulk COPYs from S3: doing row-by-row inserts would not scale for performing millions of upserts per day. Therefore, we needed the new system to accomplish two main tasks: one to write data into S3, and another to take the data from S3 and upsert it into Redshift.
Fortunately, PaaStorm already provided the necessary abstraction, the Spolt, to perform these two tasks. A Spolt reads in a message from a specified Kafka topic, processes that message in some way, and optionally publishes a new message downstream. An S3 Spolt could read in messages from an upstream Kafka topic, batch them together into small chunks, and write them to S3. After each write to S3, the S3 Spolt could then publish a downstream message to Kafka about the data that written to S3. Thus, the downstream topic would serve as state, recording which messages had been written to S3 successfully.
Next, a Redshift Spolt could read the Kafka messages published by the S3 Spolt and use that to figure out how to write the S3 data into Redshift. This way, the system that moves data into S3 and the system that moves data into Redshift could operate independently, using Kafka as the common protocol for communication.
The S3 Spolt
An S3 Spolt is responsible for reading data from an upstream Kafka topic in the Data Pipeline and writing that data into files on S3. The diagram below outlines the S3 Spolt at a high level.
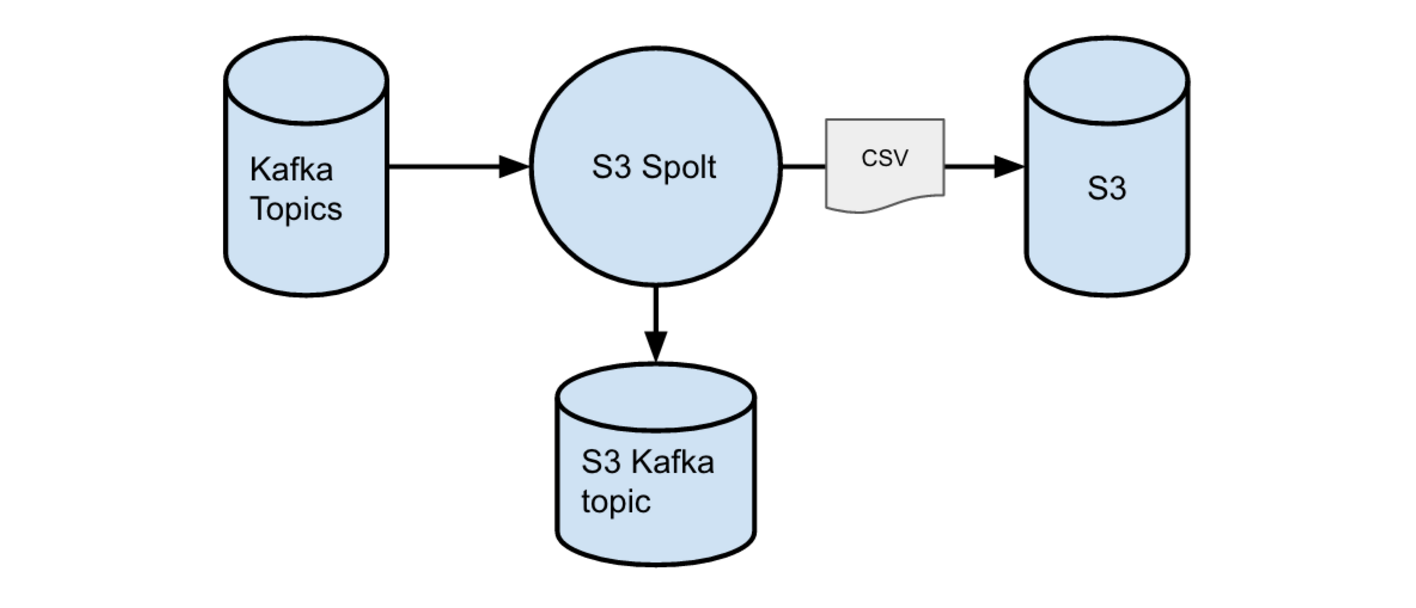
The upstream Kafka topics might contain raw row events coming from a table in MySQL, raw messages written to the Data Pipeline by a developer’s batch, or any extension of these raw data sources via a series of transformations performed by intermediate Spolts.
Writing to S3 in batches
Redshift is great for loading multiple files from S3 into Redshift in parallel. To take advantage of this, the S3 Spolt batches messages together and writes them into a key on S3 as a CSV file. The key is determined by the topic, partition, and starting offset of the messages in the batch. The S3 Spolt publishes a new batch to S3 whenever either the message limit or a time limit (or a new schema_id in the upstream messages) is reached. Both the number of messages to batch and the time limit for each batch are tunable parameters.
The S3 Spolt performs some transformations on the data it writes to S3. It annotates each message with an additional field, the message type, to describe what sort of data event this message represents (create, update, delete, or refresh). It also constructs an additional field for each message containing its Kafka offset from the upstream topic. Each batch of messages is then flattened into a CSV file using a carefully constructed csv.Dialect object – which enables easy parsing of our input CSVs while offering great robustness around parsing diverse formats. This data is then written to the appropriate key on S3.
Signaling to the Redshift Spolt
Once the S3 Spolt has written a batch of messages to a key on S3, it needs a way to signal this event to the Redshift Spolt. The S3 Spolt constructs a Kafka message containing the following information about data written to S3:
- name of the upstream topic
- start and end offsets of the messages in the upstream topic
- dialect of CSV used to write data
- path to the data on S3
- schema id corresponding to the data written to S3
This message is published to a topic from which the Redshift Spolt will eventually read.
Checkpointing and recovery
Because we can experience occasional outages, or network flakes, the S3 Spolt needs to be resilient against restarts. We don’t want the S3 Spolt to have to start from the earliest offset for a topic every time it restarts. We also can’t afford to lose any data, so we need to know for sure where we left off. The S3 Spolt solves this problem in an elegant way. Upon restart, the S3 Spolt starts a lightweight consumer and reads the tail message for the downstream topic for that spolt.
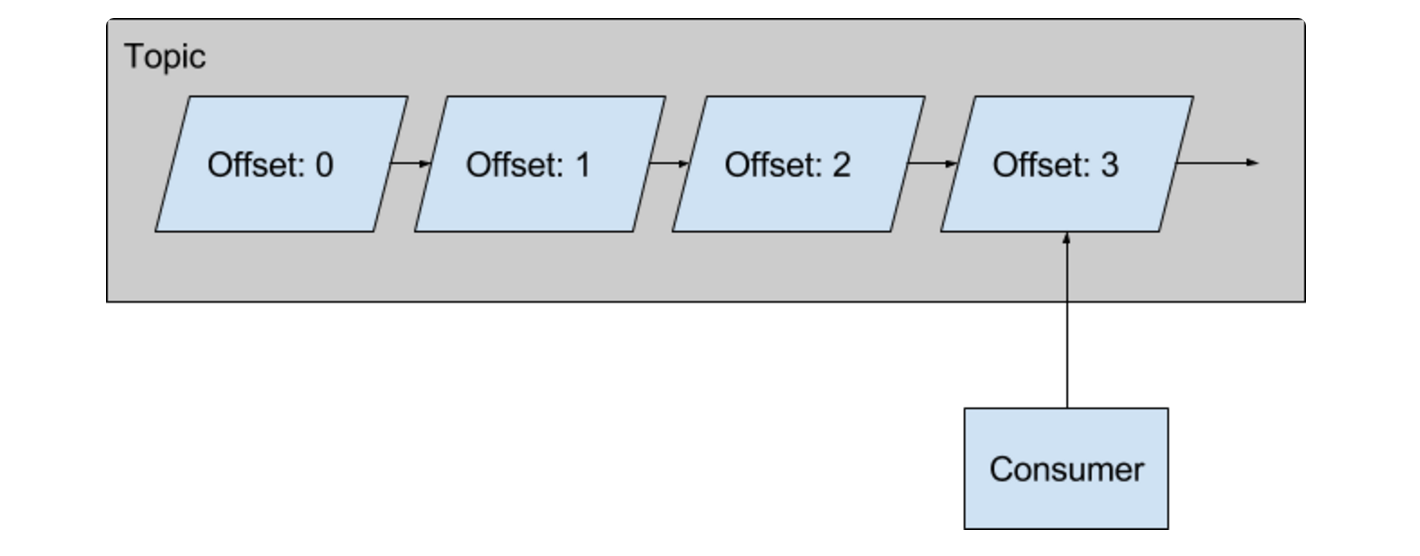
The tail message contains information about the upstream topic and end offset, which the S3 Spolt uses to restore its position in a Kafka topic if necessary. Furthermore, the S3 file writes are idempotent, so if the Kafka write fails, the S3 Spolt will replace the file upon restart. This provides a safeguard against duplicating work and dropping messages.
The Redshift Spolt
A Redshift Spolt reads in messages from topics coming out of S3 Spolts, determines where the data lives on S3, and upserts this data into a Redshift cluster. Each Redshift cluster has a dedicated Redshift spolt. The diagram below outlines the Redshift Spolt at a high level.
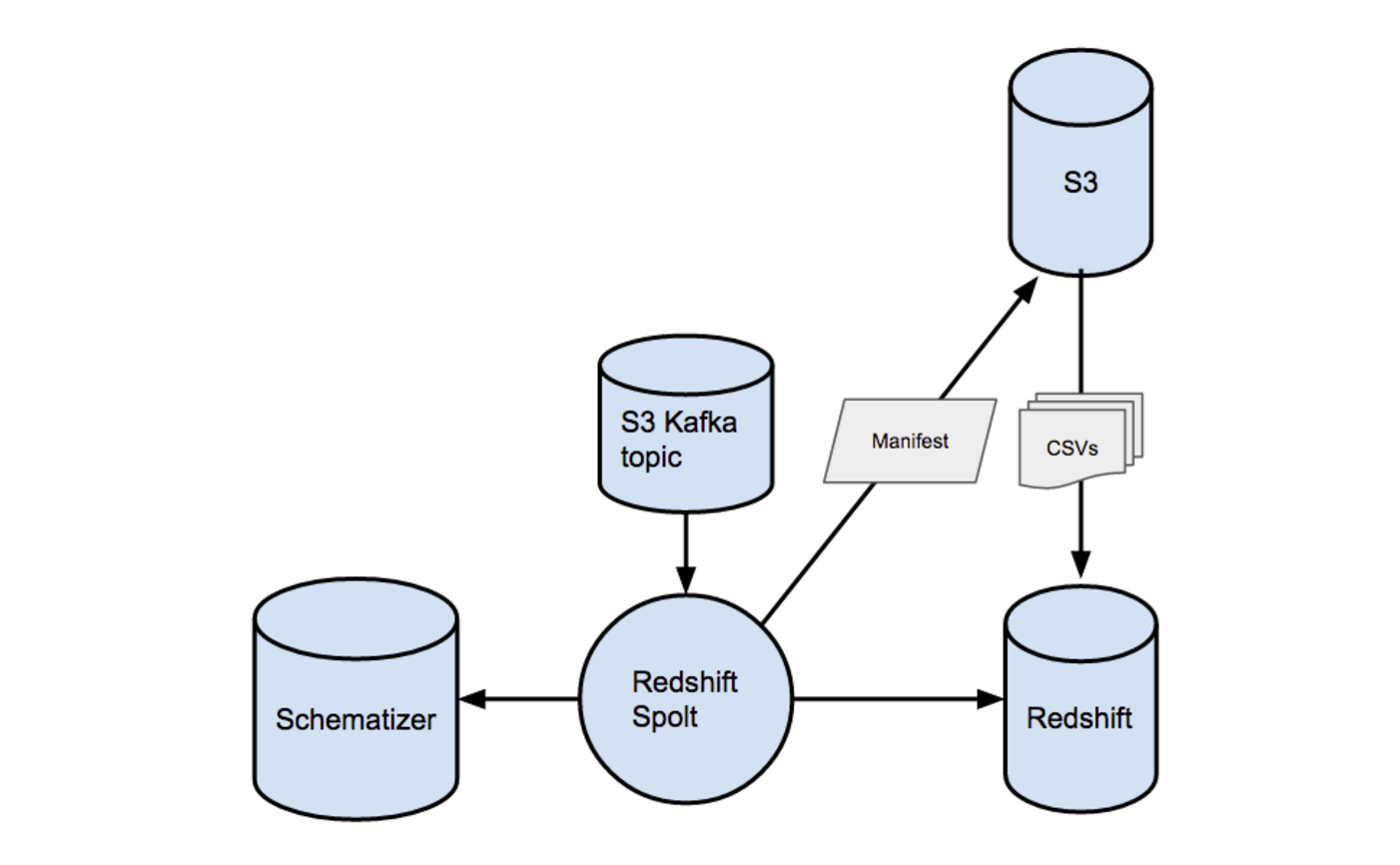
Creating S3 manifest files in batches
We take advantage of Redshift’s ability to COPY in multiple files from S3 by using a batching strategy similar to the one used by the S3 Spolt. Each Kafka message that the Redshift Spolt reads in represents a batched S3 file–in turn, we can batch up some number of those messages and COPY them all via an S3 manifest. For example, 1,000 messages in Kafka, representing 10,000 rows each on S3, gives us 10,000,000 rows at a time to be upserted with a COPY command. As long as we are batching by the schema id, all the rows across all the files in the batch are in the exact same format. We buffer messages by their schema id and flush them once we hit the desired number of messages, or if we hit the timeout for accumulating messages in a buffer.
When we flush a buffer, we first extract the S3 paths in each of the messages, and write them into a unique manifest file on S3. Because S3 lacks list after write consistency, this manifest file is critical in ensuring strong consistency in fetching the files we need to COPY into Redshift. The Redshift Spolt then passes along the location of this manifest file to our Redshift upserter.
Performing schema migrations
The Schematizer provides a set of utilities for converting Avro schemas to Redshift table CREATE statements. Given a new set of files to COPY into Redshift, the Spolt has to check for three cases: if the target table doesn’t exist, if it does exist but has a different schema, and finally if it both exists and has the proper schema already.
When the Redshift spolt starts upserting data, it checks a state table that maps each table to its schema id to see if we have already created that target table in Redshift. If not, we’ll use the schema id from the task to ask the Schematizer for a CREATE TABLE statement.
If that target table already exists, but the schema id we used to create it differs from the one in the current upsert task, this indicates the schema has changed, so we generate a sequence of statements to migrate our data from the old table into the new desired table.
Finally, if the schema id in the state table matches the desired schema id in our current upsert task, we do nothing–the target table already has the schema we want.
Staging and merging data into the target table
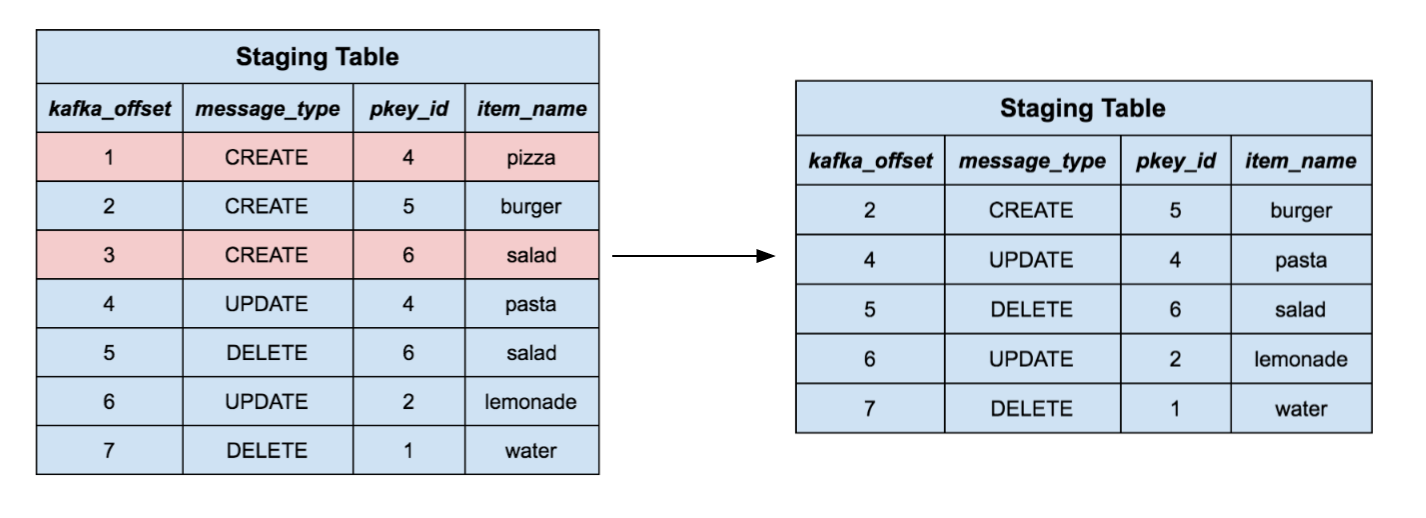
Now that our target table exists and has the desired schema, we need a way to upsert rows into it. We create a temporary staging table using the schema id for the current task. Then, we use the S3 manifest file to tell redshift to bulk COPY files into this temporary table. We now have a table containing (possibly) millions of rows, which we need to merge into our target table.
Each row in the staging table represents a row event, that is, a create, update, delete, or refresh event in the upstream source. We can’t naively upsert each row into the target table, because we have to deal with special events like updates and deletes. Instead, we perform a merging strategy, similar to the one recommended in the Redshift documentation with some slight modifications. This has the added benefit of enforcing unique key constraints, which is not natively supported by Redshift.
First, we only keep the highest offset row per primary key. This way, if a series of changes on the same upstream row occurred, we will only retain the most recent representation of that row.
For the remaining rows in our staging table, we delete all the corresponding rows in the target table with the same primary key. Intuitively, we’re removing the rows from the target table that we’re about to replace with new content. Note that this handles delete messages as well, because those rows are simply removed with nothing to replace them.
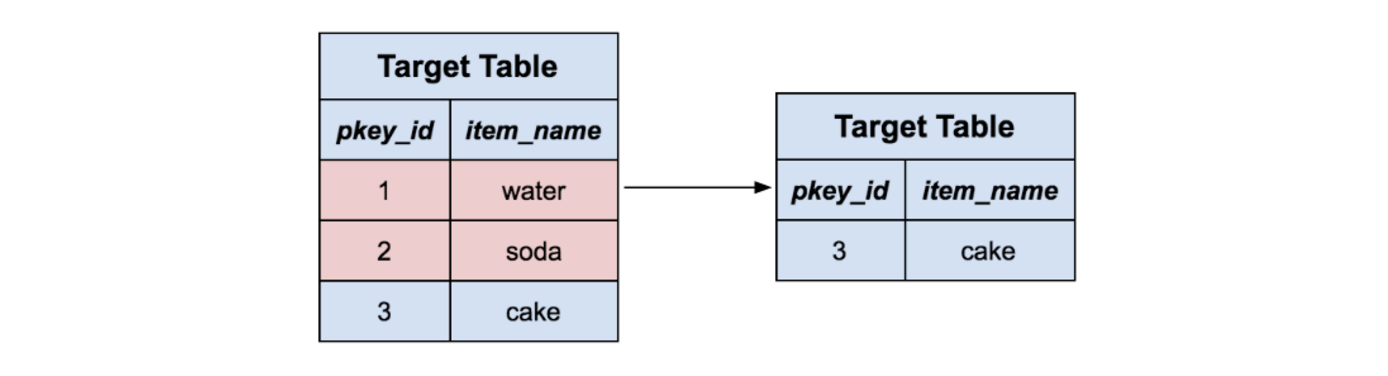
Next, we delete all rows in the staging table which correspond to delete events, since they’ve just been removed from the target table.
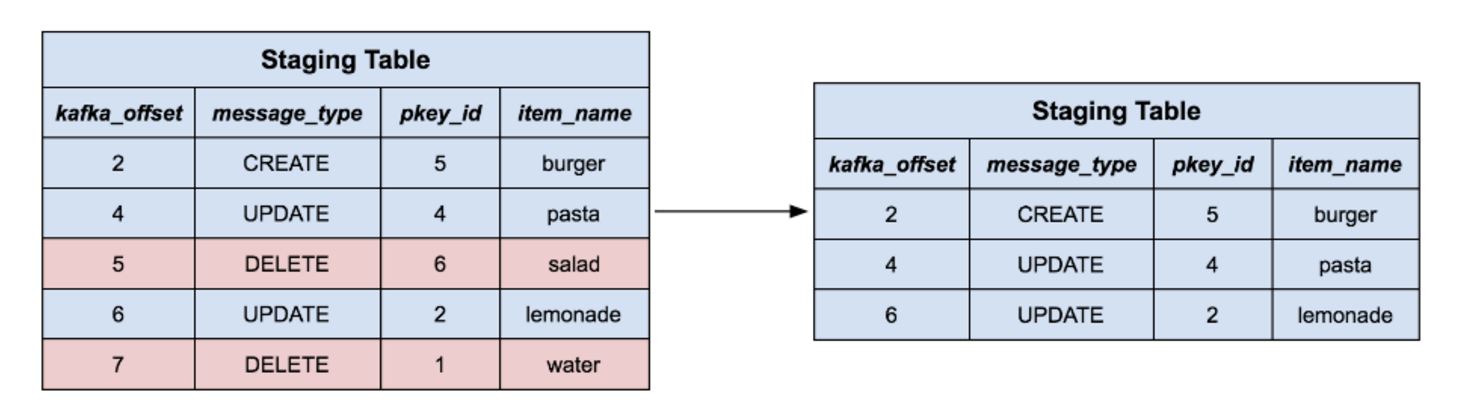
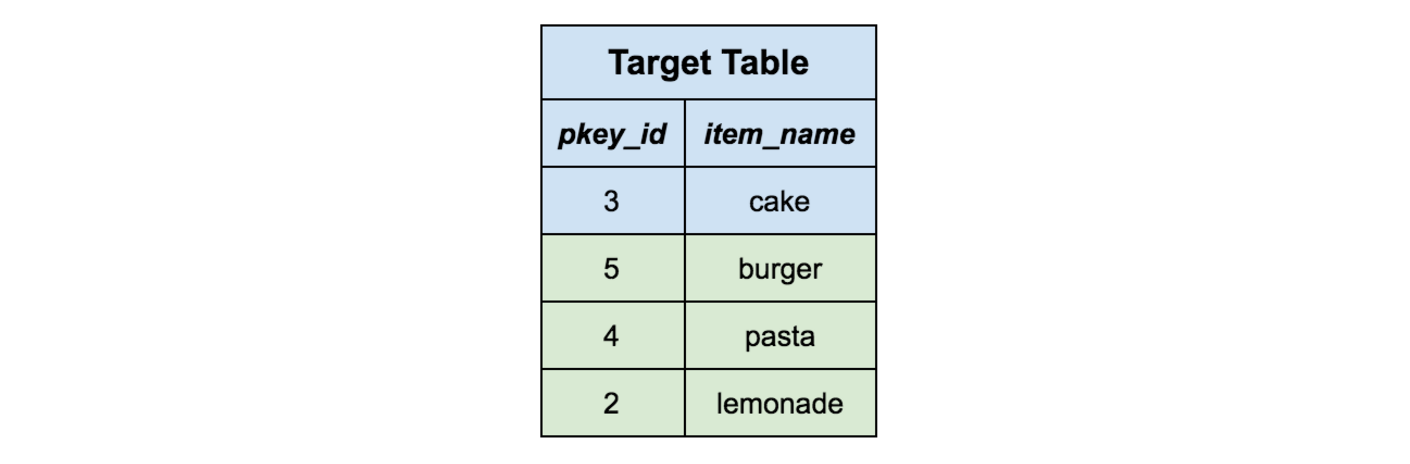
All the remaining rows represent data that does not exist in the target table already, so we simply insert them all into the target table and drop the staging table. Now our data has been fully merged from the staging table into the target table.
Checkpointing and recovery
Each upsert task can take minutes and often represents millions of underlying row changes. Like the S3 Spolt, the Redshift Spolt needs to be robust against restarts due to events like network flakiness or losing connection to Redshift so that we don’t have to duplicate any work. We use a state table in Redshift that maps every topic and partition to an offset. When the Redshift Spolt completes an upsert task, it updates the state table in Redshift with the largest offset in its batch of messages for the corresponding topic and partition. This entire upsert and checkpointing process happens within a transaction so that each task is all-or-nothing and it never leaves Redshift in a bad state. Any time the Spolt restarts, it will first check this state table and restore its position for its Kafka topics to the last known checkpoint.
Looking Forward
Yelp’s Data Pipeline has dramatically changed the way we think about data. We are shifting away from moving data via batches and scheduled jobs to a future where we connect streams like building blocks in order to build more real-time systems. The abstractions the Data Pipeline infrastructure provides have proved to be useful in building connectors to various data targets such as Redshift and Salesforce. The potential unlocked so far by the data pipeline is encouraging and we are excited to see how we can further leverage these tools to make data at Yelp even more easily accessible in the future.
Acknowledgements
Special thanks to the co-author of the Redshift Connector, Matt K. and to Chia-Chi L. and Justin C. for providing feedback and direction throughout the entire project. Many thanks also to the entire Business Analytics and Metrics team whose work on the entire Data Pipeline infrastructure has made this project possible.
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
Build Real-time Data Infrastructure at Yelp
Want to build next-generation streaming data infrastructure? Apply to become an Infrastructure Engineer today.
View Job