Streaming Cassandra into Kafka in (Near) Real-Time: Part 2

-
Harshal Dalvi, Engineering Manager and Andrew Prudhomme, Software Engineer
- Dec 18, 2019
The first half of this post covered the requirements and design choices of the Cassandra Source Connector and dove into the details of the CDC Publisher. As described, the CDC Publisher processes Cassandra CDC data and publishes it as loosely ordered PartitionUpdate objects into Kafka as intermediate keyed streams. The intermediate streams then serve as input for the DP Materializer.
Data Pipeline Materializer
The DP Materializer ingests the serialized PartitionUpdate objects published by the CDC Publisher, transforms them into fully formed Data Pipeline messages, and publishes them into the Data Pipeline.
The DP Materializer is built on top of Apache Flink, a stream processing framework. Flink has been used in production at Yelp for a few years now across various streaming applications. It provides an inherent state backend in the form of RocksDB, which is essential for guaranteeing inorder CDC publishing. In addition, Flink’s checkpoint and savepoint capabilities provide extremely powerful fault tolerance.
The application has two main phases:
- Schema Inference (or the “bootstrap phase”)
- ETL (or the “transform phase”)
Schema Inference
During the bootstrap phase, the avro schema necessary for publishing to the Data Pipeline is derived from the Cassandra table schema. The process begins by building the Cassandra table metadata objects (CFMetaData) used by the Cassandra library. Loading this metadata is required to use library functionality to act on the serialized Cassandra data from the CDC Publisher stream. The metadata object contains information on the table primary key, column types, and all other properties specified in a table CREATE statement. This schema representation is processed to produce an avro schema where each Cassandra column is represented by an equivalent avro type.
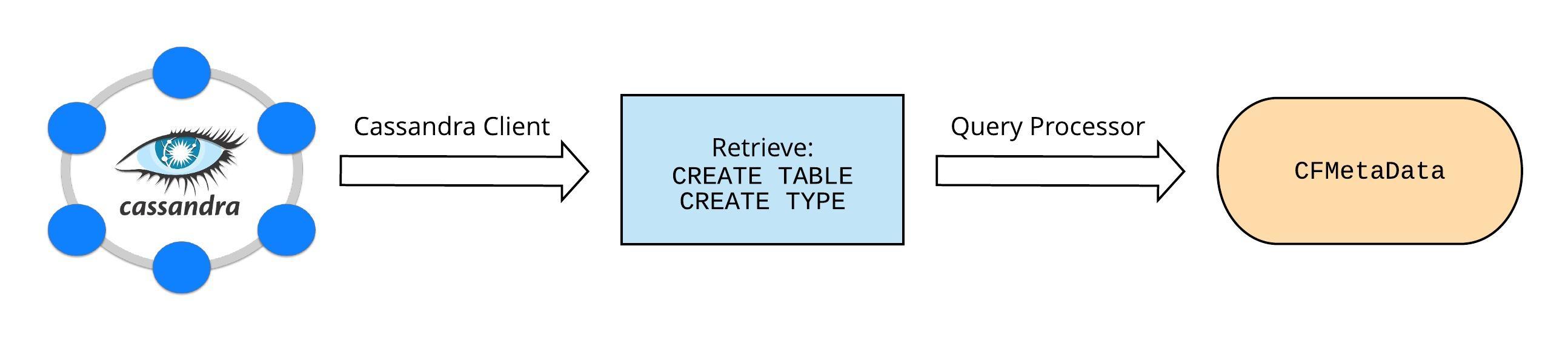
As the DP Materializer is deployed outside of the Cassandra cluster, it cannot load the table metadata from files on the local node (like the CDC Publisher). Instead, it uses the Cassandra client to connect to Cassandra and derive the CFMetaData from the schema of the table being streamed. This is done in the following steps:
- Once connected to a cluster, the create table and type (for UDTs) statements are retrieved.
- Cassandra’s query processor is used to parse the retrieved create statements into the table metadata objects.
- Information about columns previously dropped from the table is retrieved and added to the metadata built in the previous step. Loading the dropped column information is required to read table data created prior to the column being dropped.
Loading Table Metadata from Cassandra
Once the metadata is loaded, the DP Materializer builds the avro schema from the metadata. A couple of key things happen in this derivation phase:
- The table’s partition key and clustering key(s) are mapped as the primary keys of the avro schema.
- All other columns in the table (except the partition and clustering keys) are created as nullable. In the event of schema changes in the table, this guarantees that the corresponding avro schemas are always compatible to their previous versions (except when re-adding a column with a different type, which in itself can cause issues).
Schema generation currently supports nearly all valid Cassandra column types (except when prohibited by Avro), including collections, tuples, UDTs, and nesting thereof.
Schema Change Detection
As the above schema inference is part of the bootstrap phase, the DP Materializer needs the ability to detect Cassandra schema changes online and update the output Avro schema automatically. To achieve this, it implements Cassandra’s schema change listener interface, provided by the Cassandra client, to detect when a change is made to the schema of the tracked table. Once detected, the corresponding Cassandra metadata is updated and the avro schema is rebuilt from the updated metadata.
ETL (or Consume, Transform, and Publish)
This phase of the DP Materializer is where the serialized PartitionUpdate objects from the CDC Publisher are consumed, processed, and transformed into Data Pipeline messages for publishing into the Pipeline. The consumer and publisher are provided out-of-the-box by Flink, so this section primarily focuses on the transformer portion of the DP Materializer.
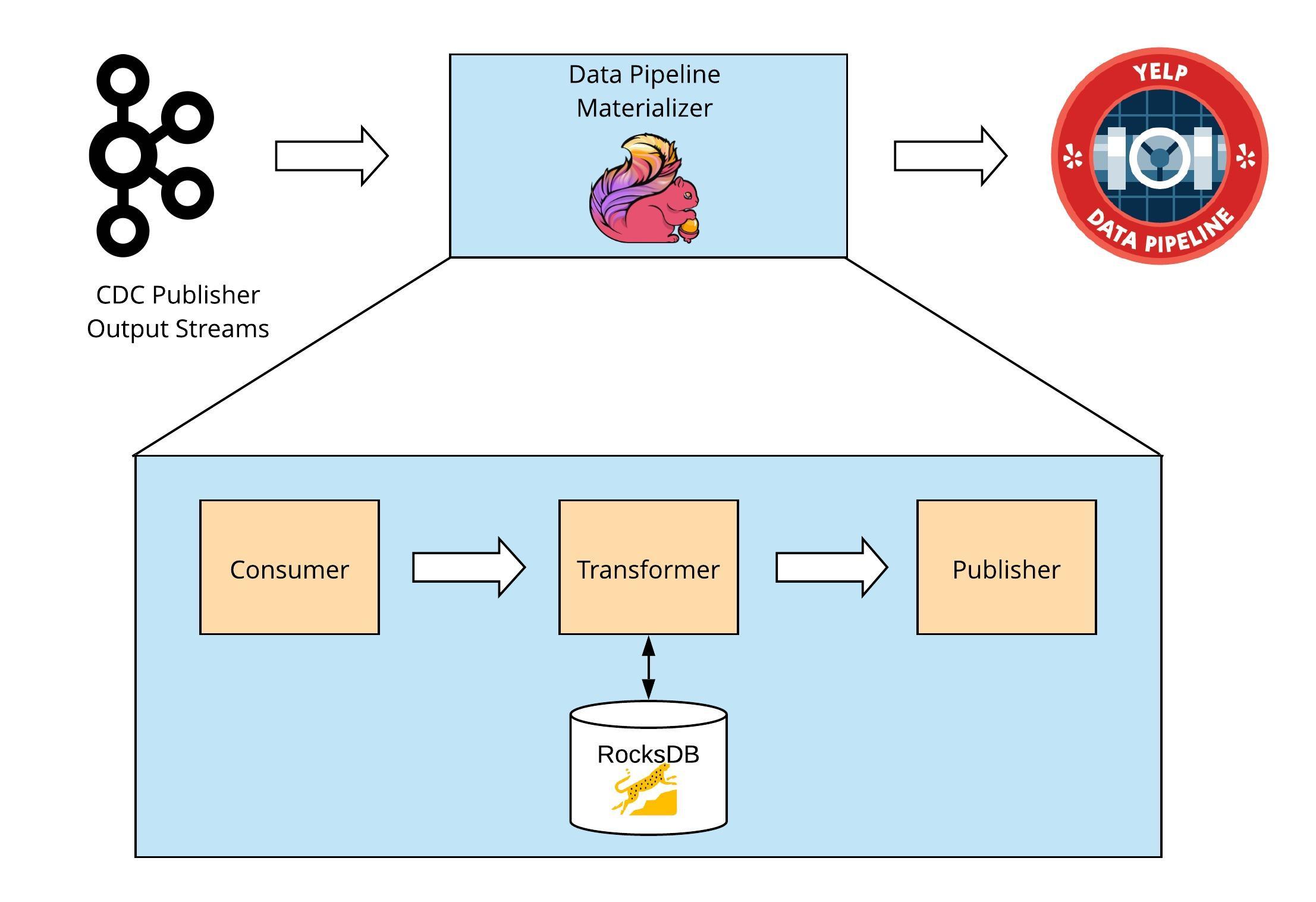
Data Pipeline Materializer
State Architecture
The transformer is backed by Flink’s RocksDB state. This state is abstracted as a collection of map objects, with each map corresponding to a partition key from the Cassandra table. Each map object has, as its keys, the clustering keys from that partition in Cassandra. A PartitionUpdate, containing at most one row, is stored as the value for its corresponding clustering key in the map. For tables which do not have defined clustering keys, each map contains a single entry with a null key.
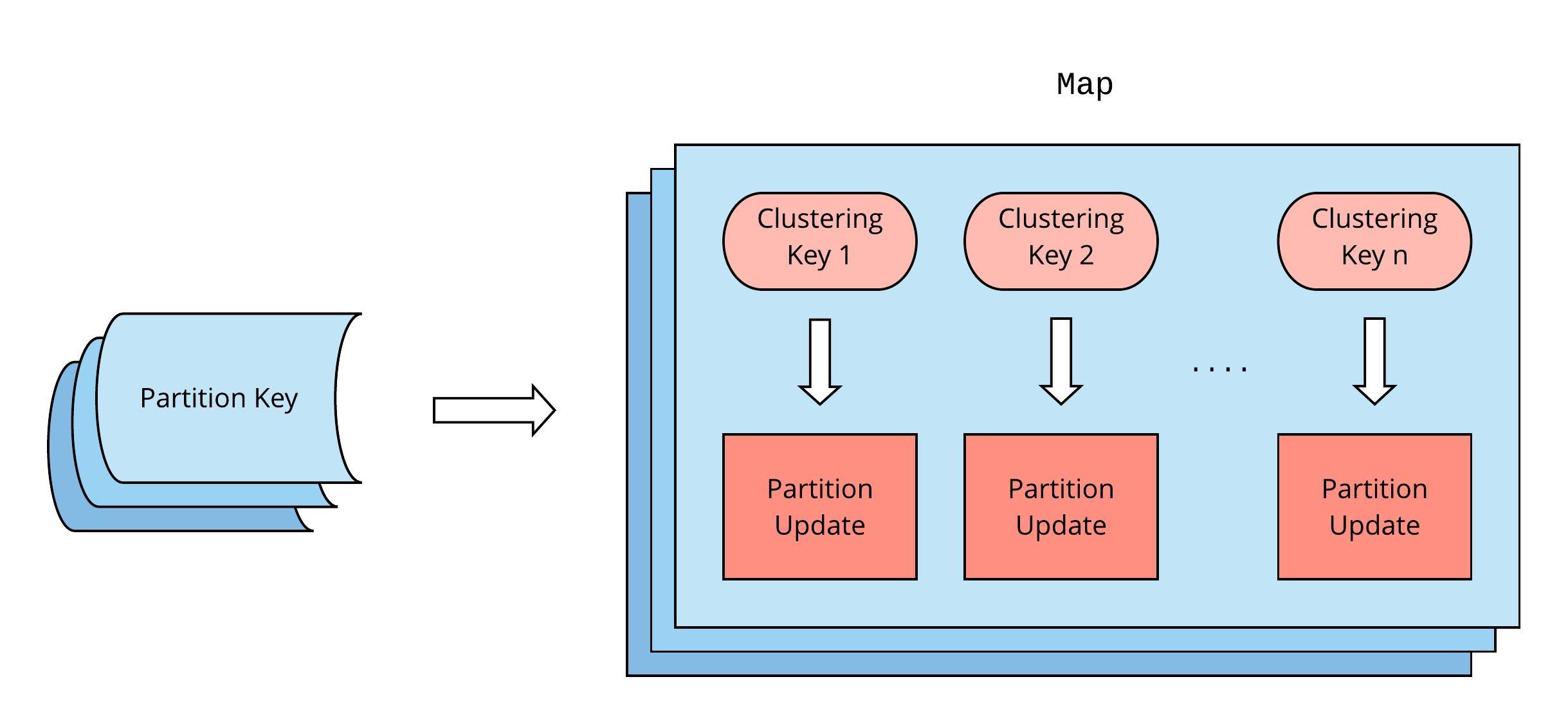
State Structure
State loading and memory management is handled internally by Flink. In addition, Flink’s stream keying mechanism guarantees that all updates for a partition key will be routed to the same worker and processed against the same map object persistently across application restarts.
Note that the PartitionUpdate objects from the CDC Publisher can be both duplicated multiple times and out-of-order (by writetime). In addition, oftentimes a PartitionUpdate may not contain the full content of a Cassandra row.
The Transformer
The central piece of the application is the transformer, which:
- Processes the Cassandra CDC data into a complete row (with preimage) for the given avro primary key (Cassandra partition key + clustering key[s]) for publishing to the Data Pipeline.
- Produces final output message with the appropriate Data Pipeline message type.
The transformer uses the row (PartitionUpdate) saved in the map objects in the state, along with the incoming PartitionUpdate objects from the CDC Publisher to generate the complete row content, the previous row content (in the case of UPDATE, DELETE messages), and the type of the output message.
This is achieved by deserializing the input PartitionUpdate and merging it with the saved PartitionUpdate. This is done using the same PartitionUpdate merge functionality Cassandra uses to combine data from SSTables during reads. The merge API takes in two PartitionUpdate objects, one from the Flink state and the other from the CDC Publisher’s output stream. This produces a merged PartitionUpdate which is used to build an avro record with the schema derived during the bootstrap phase. If the previous row value is needed, it is derived from the saved PartitionUpdate in the Flink state. In the end, the state is updated with the merged PartitionUpdate.
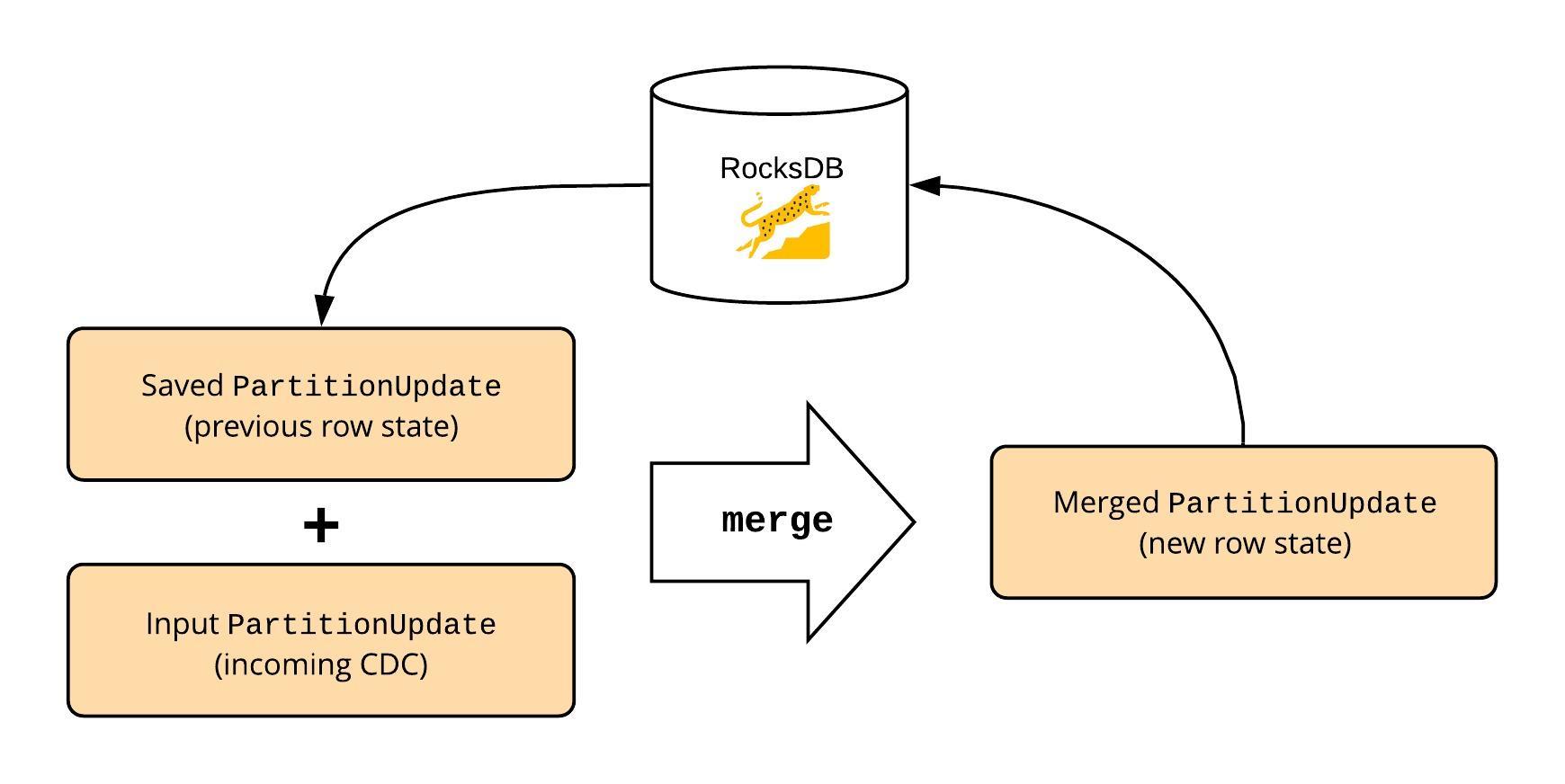
Determining Row States
This process handles duplicate and out-of-order PartitionUpdate objects. The use of Cassandra’s merge functionality results in the same “last write wins” conflict resolution as a Cassandra read. To avoid publishing duplicate messages, it is verified that the input PartitionUpdate changes the row state. This is done by computing the md5 digests of the saved and merged PartitionUpdate objects. If the digests are the same, the PartitionUpdate is ignored.
The merge, update state, and publish logic can be summarized below:
- The incoming PartitionUpdate is merged with the saved PartitionUpdate (if it exists) and the corresponding Data Pipeline message is determined:
- If the merged PartitionUpdate contains live (non-tombstoned) data and the saved does not, a CREATE message is published.
- If both the merged and saved PartitionUpdate objects contain live data, an UPDATE message is published if the md5 digests of the objects are different.
- If the merged PartitionUpdate contains tombstoned data but the saved one contains live data, a DELETE message is published.
- If the md5 digests of the saved and merged PartitionUpdate objects are different, then the merged PartitionUpdate is saved in the state.
Thus, at the end of the transform phase, a message with the appropriate Data Pipeline message type and the full row content is ready to be published into the Data Pipeline.
Supporting Backfills
Bootstrapping a Stream
A limited amount of CDC logs can be stored on a Cassandra node. Thus, when a table is set up to be streamed by the connector, only the data available in the CDC directory at the time (and going forward) will be processed. However, to maintain the stream-table duality, all of the existing data in the Cassandra table needs to be replayed into the stream.
To achieve this, the backfill bootstrap process reads through the data stored on disk as SSTables. To ensure that the set of SSTable files are not modified by compaction during the backfill, the table’s snapshot is taken and the SSTables are processed off of that snapshot. The Cassandra SSTable reader returns the scanned data as a series of PartitionUpdate objects. The CDC Publisher processes these PartitionUpdate objects in the same way as commit log segments and publishes them into Kafka, where they’re subsequently transformed into Data Pipeline messages by DP Materializer.
This process is followed whenever a Cassandra table is first set up to be tracked by the connector. This is also done if there’s a need to rebuild the state in the DP Materializer.
Rebuilding a Stream
If a tracked table’s output stream becomes corrupted or is deleted (unlikely but possible), the stream can be rebuilt by replaying the stored state of the DP Materializer. As all of the serialized PartitionUpdate objects are stored in the state, there’s no need to republish data from the SSTables.
Limitations and Future Work
Partition Level Operations
The current system design processes each row change independently. A single input message to the DP Materializer will emit at most one message into the Data Pipeline. Changes at a partition level that affect the value of multiple rows are not currently supported. These include:
- Full partition deletion (only when using clustering)
- Ranged tombstones
- Static columns
There is, however, a potential path to support. The DP Materializer stores all rows in a single Cassandra partition as entries of the same map object during processing. It is conceivable to also store the partition level state separately. When this state changes, the DP Materializer could iterate through the entire map (Cassandra partition) and produce Data Pipeline messages for all affected rows.
TTL
TTL’ed data is currently not supported by the connector. TTL values are ignored and data is considered as live based on its writetime.
Dropping Tombstones
There’s no support to drop tombstones from DP Materializer’s Flink state. They will remain there indefinitely unless overridden with new data. It may be possible to drop old tombstones when updating row state, similar to the gc_grace_seconds parameter on tables. However, this would not help for rows that are never updated. In addition, great care would need to be taken to ensure backfilling or repairing a table does not create zombie data in the output stream.
Publishing Latency
As mentioned earlier, commit log segments must be full and no longer referenced by memtables before being made available for processing by Cassandra. In spite of the CDC log filler implementation, some latency is introduced in publishing to the Data Pipeline. This limitation should be overcome in Cassandra 4, which introduces the capability to read live commit log segments and will thus ensure that the publishing latency is as close to real time as possible.
Learnings
The Cassandra Source Connector has been running in production at Yelp since Q4 2018. It supports multiple use cases, which have helped in surfacing some quirks about its design choices:
Avro as a Serialization Format
The maximum number of cells (rows * columns) allowed by Cassandra in a single partition is two billion. This means that a row could potentially have two billion columns. However, Avro serialization and deserialization becomes a bottleneck once the number of columns starts going into the hundreds and cannot hold up with the potential maximum number of columns. Horizontal scaling might be needed for consumers depending on the throughput requirements and size (in number of columns) of the Cassandra table being streamed.
In addition, a few Cassandra data types (such as DECIMAL) don’t have intuitive Avro data type equivalents. In such cases, either the columns cannot be supported or custom avro data types have to be defined.
Flink State Size
As every single row from the table is stored as a serialized PartitionUpdate in the state, the state size can grow up to be huge for large tables. The state size becomes a bottleneck for code pushes and maintenance as it has to be reloaded for every deployment and restart of the application. Additional work is required for minimizing the time for saving and loading state for huge tables.
TL;DR?
Yelp presented the Cassandra Source Connector at Datastax Accelerate 2019. You can watch it here.
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2