The Dream Query: How we scope projects with GraphQL

-
Mark Larah, Tech Lead
- Oct 7, 2020
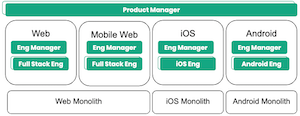
At Yelp, new web pages and app screens are powered by GraphQL for fetching data. This blog post describes the Dream Query – a pattern our feature teams use when refactoring or creating new pages. (Check out our previous blog post to see how we dynamically codegen DataLoaders to implement the server layer!) Scoping a new feature with GraphQL Let’s jump in with an example! Imagine your team is tasked with creating the new version of the “Header component” for the website (we’ll use the Yelp.com website in our example). You may receive a design mock that looks like this:...