How Yelp Runs Millions of Tests Every Day

-
Chunky G., Software Engineer
- Apr 26, 2017
Fast feature development is critical to a company’s success. We all strive to increase developer productivity by decreasing the time to test, deploy, and monitor changes. To enable developers to push code safely, we run more than 20 million tests every day using our in-house distributed system called Seagull.

What is Seagull?
Seagull is a fault tolerant and resilient distributed system which we use to parallelize our test suite execution. Seagull is built using the following:
- Apache Mesos (manages the resources of our Seagull cluster)
- AWS EC2 (provides the instances that make up the Seagull and Jenkins cluster)
- AWS DynamoDB (stores scheduler metadata)
- Docker (provides isolation for services required by the tests)
- Elasticsearch (tracks test run times and cluster usage data)
- Jenkins (builds code artifacts and runs the Seagull schedulers)
- Kibana and SignalFx (provide monitoring and alerting)
- AWS S3 (serves as the source-of-truth for test logs)
Challenge
Before deploying any new code to production for our monolithic web application,
yelp-main, Yelp developers run the entire test suite against a specific version
of yelp-main. To run the tests, the developer triggers a seagull-run job, which
schedules the tests on our cluster. There are two important things to consider:
- Performance: Each seagull-run has nearly 100,000 tests and running them sequentially takes approximately 2 days to finish.
- Scale: More than 300 seagull-runs are triggered on a typical day with 30-40 simultaneous runs in peak hours.
The challenge is to execute each seagull-run in minutes rather than days, while
still being cost-effective, at our scale.
How Does Seagull Work?
First, the developer triggers a seagull-run from the console. This starts a
Jenkins job to build code artifact and generate a test list. Tests are then
grouped together and passed to a scheduler to execute the tests on the Seagull
cluster. Finally, test results are stored in Elasticsearch and S3.
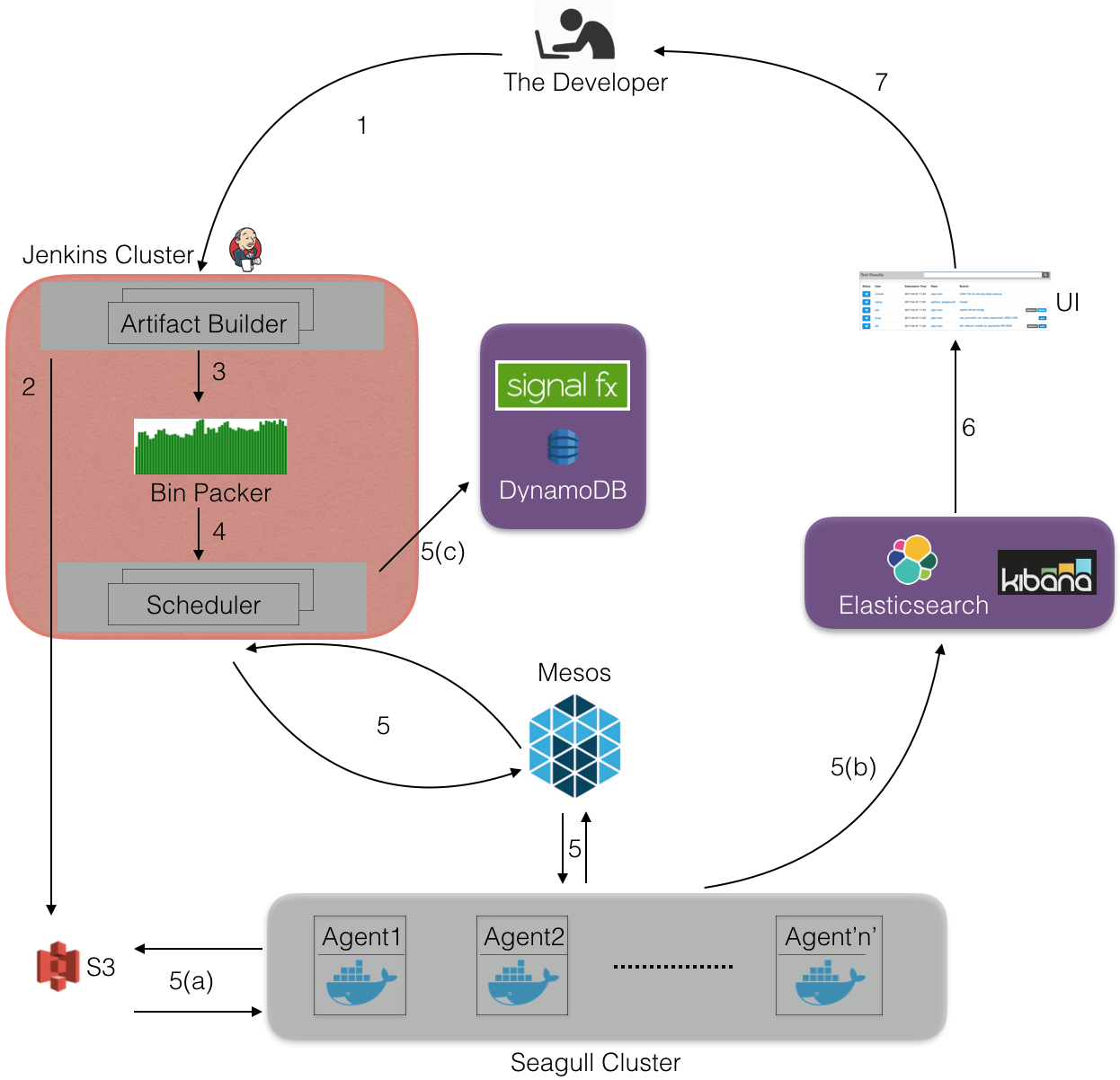
(1) A developer triggers a seagull-run for a specific version of code
(based on the git SHAs from their branch). Let’s say the git branch name is test_branch.
(2) A code artifact and a test list is generated for test_branch and uploaded to S3.
(3) Bin Packer fetches the test list along with test’s historic timing metadata to create multiple bundles containing tests. Efficient bundling is a bin packing problem and we use the following two algorithms to solve this problem, depending on the parameters passed to Seagull by the developer:
- Greedy Algorithm: Tests are first sorted based on their historic test durations. Then we start filling bundles with 10 minutes of work (tests).
- Linear Programming (LP): In case there is a test dependency,
a test needs to run with another test in a same bundle. For this, we use LP for bundling.
Objective function and constraints of the LP equation are defined as:
- Objective Function: Minimize the total number of bundles generated
- Main Constraints:
- A single bundle’s work should be less than 10 minutes
- A test is put in only one bundle
- Dependent tests are put in same bundle
We use Pulp LP solver to solve this equation
# Objective function:
problem = LpProblem('Minimize bundles', LpMinimize)
problem += lpSum([bundle[i] for i in range(max_bundles)]), 'Objective: Minimize bundles'
# One of the constraint, constraint (1), looks like:
for i in range(max_bundles):
sum_of_test_durations = 0
for test in all_tests:
sum_of_test_durations += test_bundle[test, i] * test_durations[test]
problem += (sum_of_test_durations) <= bundle_max_duration * bundle[i], ''Where, bundle and test_bundle are LpVariable, max_bundles and bundle_max_duration are integers.
Normally we consider the testcases’ setup teardown durations in our LP constraints but for simplicity’s sake we ignore them here.
(4) A scheduler process is started on a Jenkins host which fetches the bundles
and then starts a mesos framework. We create a new scheduler for each seagull-run.
Each run generates more than 300 bundles, grouping each bundle to be around 10 minutes worth of tests. For each bundle the scheduler creates one mesos executor and schedules it on the Seagull cluster whenever sufficient resources are offered by the Mesos master.
(5) Once an executor is scheduled on the cluster the following steps occur inside the executor:
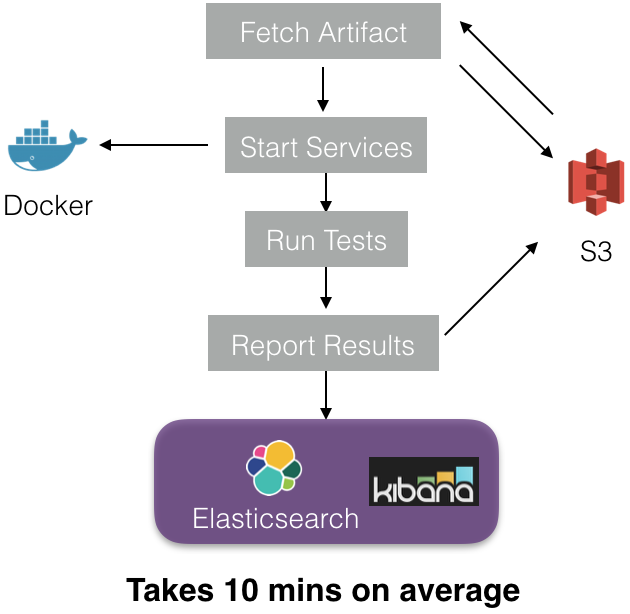
Each executor starts a sandbox and downloads the build artifact from S3 (uploaded in step 2). Docker images corresponding to test service dependencies are then downloaded to start the docker containers(services). When all the containers are up and running, the tests start executing. Finally, test results and metadata are stored in Elasticsearch (ES) and S3. To write to ES we use our in-house proxy service Apollo.
If you are living in a distributed systems world one thing you cannot avoid is host failure. Seagull is fault tolerant towards any instance failure.
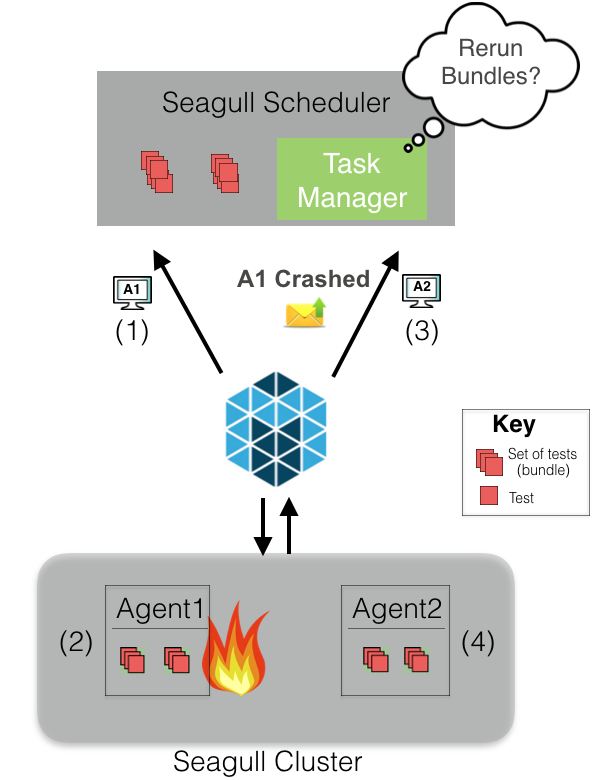
For example, suppose a scheduler has two bundles to run. Mesos will offer the
resources of an agent (A1) to the scheduler. Assuming the scheduler deems the
resources sufficient, the two bundles will be scheduled on A1. Suppose for
some reason A1 goes down, then Mesos will let the scheduler know that A1 is
gone. The scheduler’s task manager makes a decision to retry those bundles or abort.
If the bundles are retried, they will be re-scheduled when Mesos provides the
next sufficient resource offer (in this case, from agent A2). In case bundles
are aborted, scheduler will mark those bundle’s tests as not executed.
(6) Seagull UI fetches the results from ES using Apollo and loads it into a UI for developers to see their results. If they all pass, they’re ready to deploy!
What scale are we talking about?
There are around 300 seagull-runs every day with 30-40 per hour at peak time. They launch more than 2 million Docker containers in a day. To handle this, we need to have around 10,000 CPU cores in our seagull cluster during peak hours.
Challenges at this scale
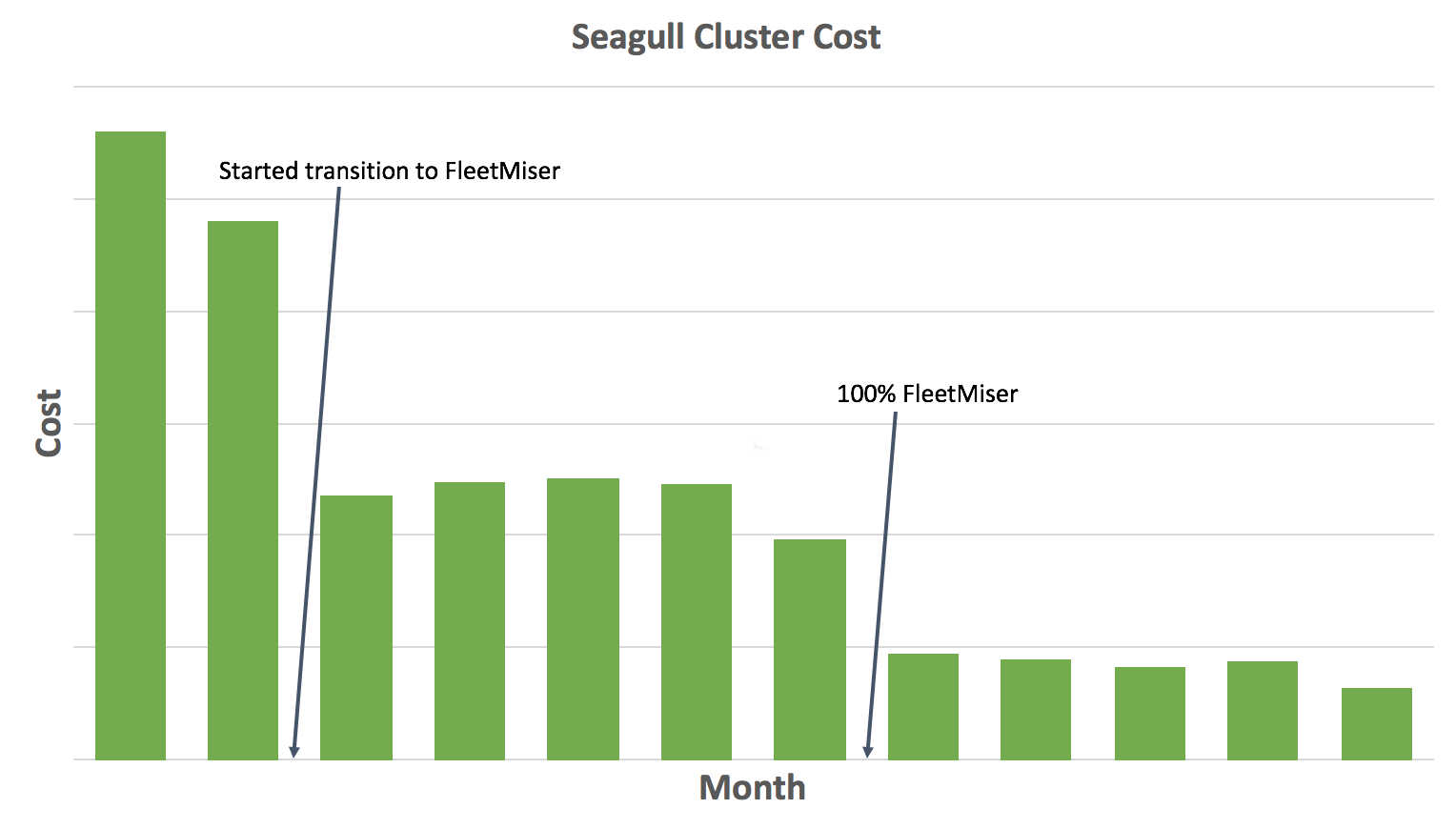
To maintain the timeliness of our test suite, especially at peak hours, we need to have hundreds of instances always available in Seagull Cluster. For a while we were using AWS ASGs with AWS On-Demand Instances but fulfilling this capacity was very expensive for us.
To reduce costs, we started using an internal tool, called FleetMiser, to maintain the Seagull Cluster. FleetMiser is an auto-scaling engine which we built to scale a cluster based on different signals such as current cluster utilization, number of runs in pipeline, etc. It has 2 main components:
- AWS Spot Fleet: AWS has Spot Instances which can be consumed at much lower prices than On-Demand instances and Spot Fleet provides an easier interface for using Spot Instances.
- Auto Scaling: Our cluster usage is volatile, with major utilization between 10:00 to 19:00 PST when developers do most of the work. To automatically scale up and down, FleetMiser uses the cluster’s current and historic utilization data with different priorities. Every day the seagull cluster scales up and down between approximately 1,500 cores to 10,000 cores.
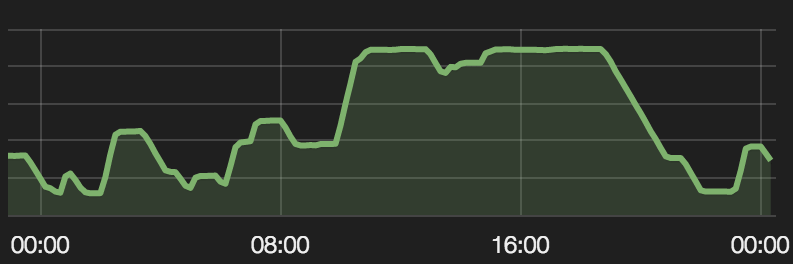
Auto Scaling: Cluster capacity for a few weeks ago
FleerMiser saved us ~80% in cluster cost. Before FleetMiser, the cluster was completely on AWS On-Demand Instances with no auto scaling.
What have we achieved?
Seagull has achieved a test result response time improvement from 2 days to 30 minutes and has also delivered a large reduction in execution costs. Our developers are able to confidently push their code without needing to wait hours or days to verify their changes haven’t broken anything.
If you are interested in learning more, check out the AWS re:invent talks on Seagull and FleetMiser.
Want to help build such distributed systems tools?
Like building this sort of thing? At Yelp we love building systems we can be proud of, and we are proud of Seagull and FleetMiser. Check out the Software Engineer - Distributed Systems positions on our careers page
View Job