Breaking down the monolith with AWS Step Functions

-
Scott Triglia, Tech Lead
- Nov 27, 2017
As we’ve discussed in earlier blog posts, Yelp Engineering has been working hard to break down our largest monolithic code base (yelp-main) for the past few years. We’ve made great progress but some of our oldest, most critical code remains within yelp-main. A great example of an older, more established system is our monthly subscription billing cycle. The system is core to how Yelp collects revenue and has proven technically challenging and risky to transition.
The Revenue engineering team knows these older systems should be moved into services, but the challenge of extracting tangled, business-critical code has proven expensive and dangerous. Luckily a new framework was announced by Amazon Web Services at the end of 2016, AWS Step Functions, that’s allowed us to make this transition a reality. This post covers how we’re leveraging Step Functions to achieve escape velocity from yelp-main, better represent our business processes, and build a more reliable, observable system along the way.
A subscription billing primer
To set the stage a bit, here’s a look at what made this process so technically challenging. The subscription billing process lies at the center of a large nightly chain of batches. This pipeline takes hours to run each night and its ownership spans several teams at Yelp. Subscription billing consists of three conceptual jobs in the center of this pipeline:
- Billing accounts (how much does each account owe?)
- Invoicing (rolling up these line items into a single bill)
- Collections (actually collecting payment for the invoices)
Each of these three steps runs over all relevant payment accounts before the next step proceeds. This fact has two implications for the stability and performance of these jobs:
- Each of these steps is doing significant work, so billing across more than 100k accounts takes hours to run in the best case.
- Since these steps operate over all accounts at once, one broken or slow account can block the entire rest of the pipeline. Making sure these steps complete cleanly and correctly is incredibly important!
As the number of advertisers at Yelp has grown, it has been a challenge to keep this process scaling successfully. We’ve introduced concurrency frameworks into our batch processing libraries, been very conservative when changing the code, and spent a ton of time maintaining the status quo.
A few key limitations have kept us from moving this code into services:
- These processes did not have clear APIs in our monolith. They were invoked by the daily billing pipeline and ran over all accounts in semi-parallel fashion.
- The data backing these various processing steps is entrenched in yelp-main. Moving the backing data out felt impossibly expensive, but if the data was left in yelp-main it wasn’t clear what value a service would provide.
- Some steps – like marking invoices as paid – currently leverage very stringent ACID guarantees (via MySQL transactions) to ensure our ledgers are consistent with payments we’ve collected from advertisers. Moving to a service would require devising an alternative way to maintain the same consistency guarantees.
These collective challenges prevented extraction of subscription billing. We saw no cost-effective way for a small team to decouple the system without unacceptable consequences. Luckily for us, a solution was right around the corner.
AWS Step Functions steps into the breach
AWS Step Functions released to the public in December 2016, offering state machine-based workflow coordination as a service. It implements basic primitives for you, including retries, branching, and timeouts. Step Functions delegates tasks to your code for more complex side effects, like writing to a database, or calling an internal service. These are called “activity tasks” when run from your own servers, instances, or containers. Step Functions can also dispatch tasks to AWS Lambda functions.
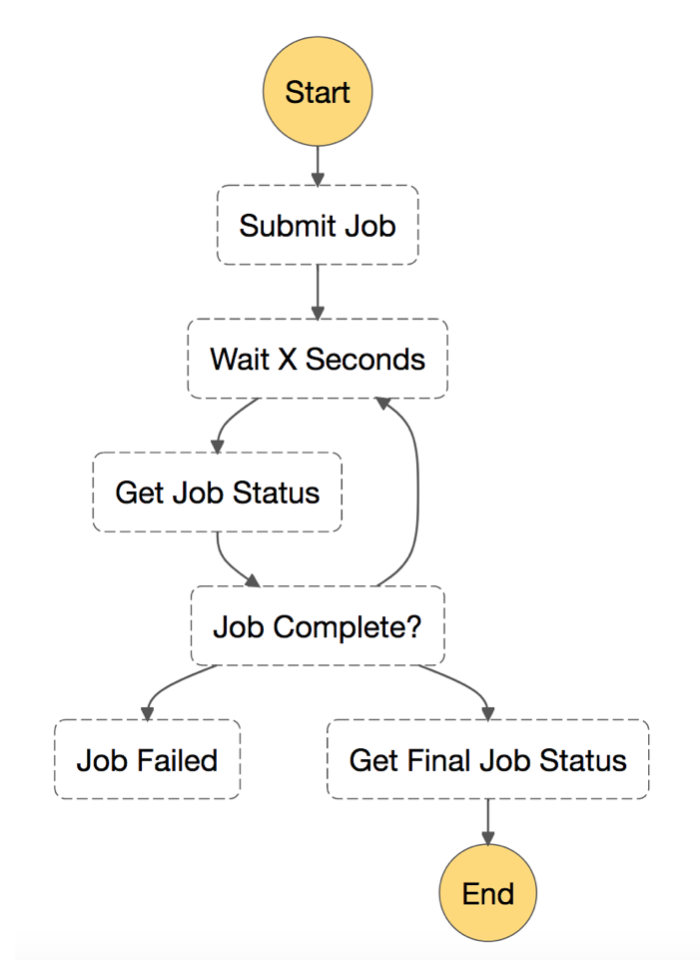
The flexibility of the state machine description language makes it applicable for a variety of use cases, but the core appeal for us came down to a few important features:
- There are few limitations on how long an activity task can run. If you aren’t ready to break up your code into many bite-sized activity tasks, you can run a few, very large activity tasks
- Activity tasks are codebase agnostic. This means your workflow can seamlessly coordinate multiple activity tasks that live across services.
- Retries and timeouts allow you to flexibly ensure individual activity tasks are robust and complete successfully.
- Concurrent executions can be run in parallel at significant scale. Up to a maximum of 1 million executions can be run at once.
Step Functions has a lot of potential as a framework that can support monolithic code that wants to act in a service-like way. It seemed like a great match for our workflow-like subscription billing process, so we launched an initial project to integrate it.
Our first pass - bookkeeping on Step Functions
The diagram of the subscription billing process showed three fundamental steps: bookkeeping, invoicing, and collections. For our first stab at this project, we decided to tackle moving the first step of this process behind a Step Functions workflow. This offered a relatively well-scoped amount of work and let us work on the interface of this process without scoping in the task of migrating invoicing and collections.
Our very first step was to choose the workflow’s interface. The old batch code looked roughly like this:
def runner(all_accounts):
for chunk in all_accounts:
dispatch_work(chunk)
def worker(chunk):
for account in chunk:
bill_account(account)
Our batch parallelism framework divided the set of all accounts into sections, and dispatched each chunk of accounts to a different worker process. We wanted to take advantage of the significant parallelism available in Step Functions, so we determined that a single workflow should perform subscription billing for a single account. To avoid a regression from our legacy system’s end-to-end performance, we could simply fire off many of these workflows concurrently.
Concurrency variation over time in the old framework:
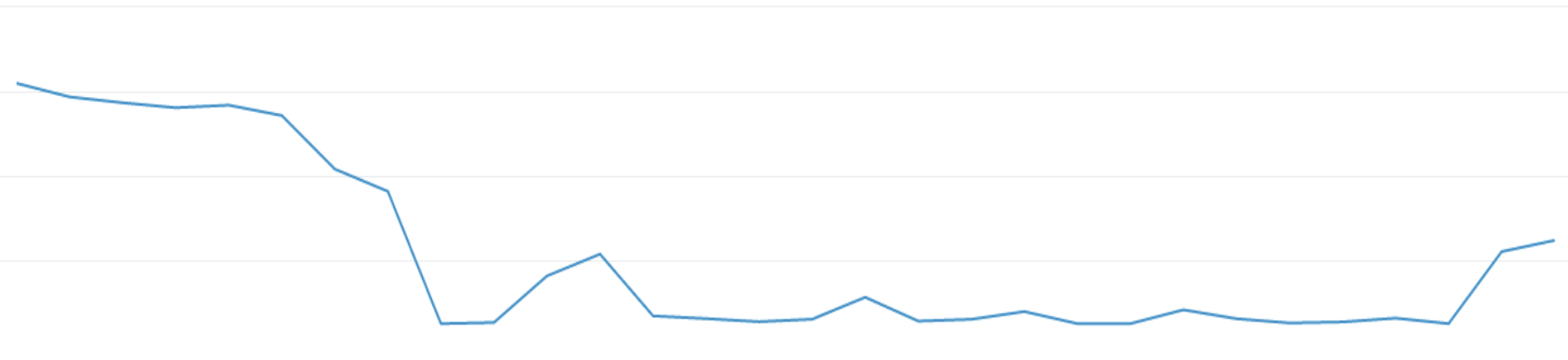 Concurrency staying stable over time with Step Functions:
Concurrency staying stable over time with Step Functions:

Once the interface was determined, we built an API for billing a single account which only required an account ID and a date for billing (in case we needed to re-run past days workflows). Now note the simplicity and beauty of this: we just made running subscription billing feel like talking to a service, even though we have yet to migrate the actual behavior out of our monolith. This isn’t quite as good as actual service migration, but it’s a big step in the right direction for very little effort! We had originally considered just wrapping the yelp-main function in a very small monolith-based API, but using Step Functions let us keep all API management code cleanly separated, which would prove essential as the workflow evolved.
Finally we need to implement our workflow’s state machine. We started by keeping it simple: making one large activity to match our old monolithic functionality! We knew this probably wouldn’t be a permanent solution, but it made migration incredibly straightforward and let us quickly and easily establish a baseline implementation for our Step Functions workflow.
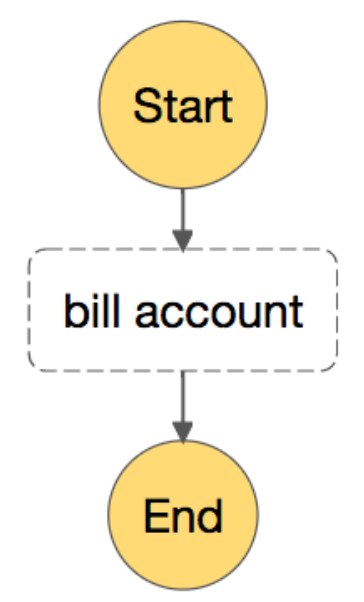
Polishing for observability and performance
We tested this in production and saw the pieces working together just as intended. We kept a careful eye on two historic pain points for subscription billing: making sure any issues in the pipeline were highly visible to on-call engineers, and that the pipeline stayed highly performant.
If there were any transient issues while billing an account, the retries we built into our workflow would simply re-run the bill_account activity. If an account had fundamental issues that caused billing to fail repeatedly, we’d eventually exhaust our retries or timeouts and Step Functions would mark the whole execution as failed. This execution failure was so important to us that we added an explicit state in the workflow to represent success and failure. These activities were solely there to push that success/failure fact into Yelp monitoring systems (like SignalFX) along with basic identifying information like account ID and execution ARN.
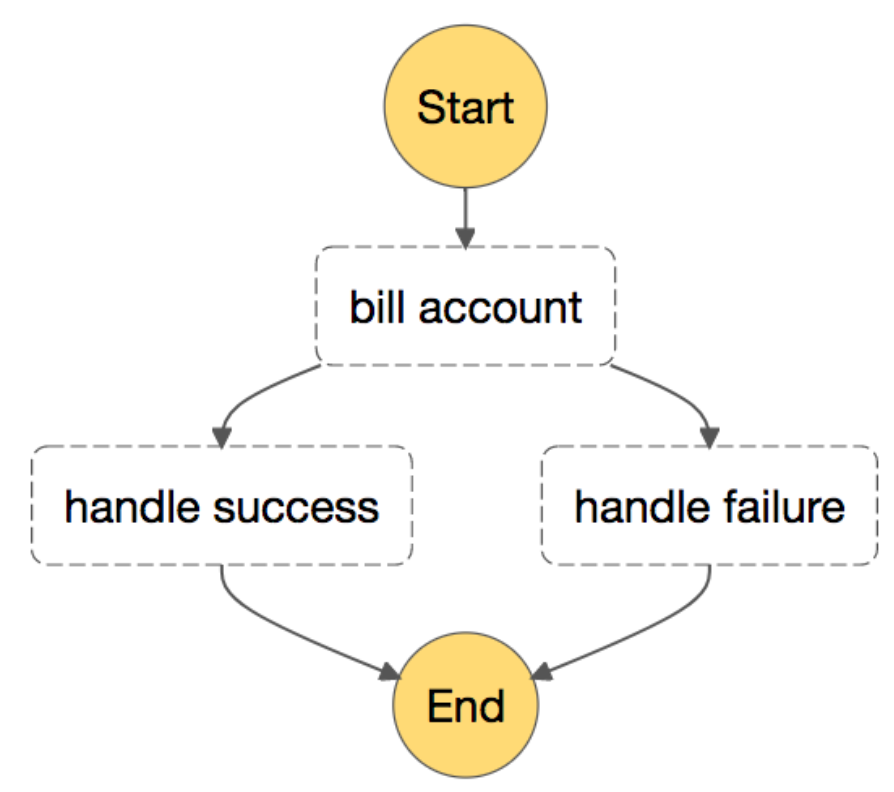
This set-up ensures that one-off errors are cleanly handled by retries but also ensures that on-call engineers stay aware of any issues that cause billing to fail systematically. That increased awareness also means if one account cannot be billed, we can continue billing other accounts in parallel while our on-call engineers are notified — no more blocking the whole pipeline for a single bad account!
We also saw performance wins. Execution concurrency worked well, even outperforming our own previous batch-based parallelism by avoiding some previous limitations. We further increased this advantage by revisiting our workflow design and breaking bill_account into a few parallel steps for different types of subscription products. It was the work of a couple hours to design a new workflow where these steps were done in parallel, and the associated changes to the activities were quite easy.
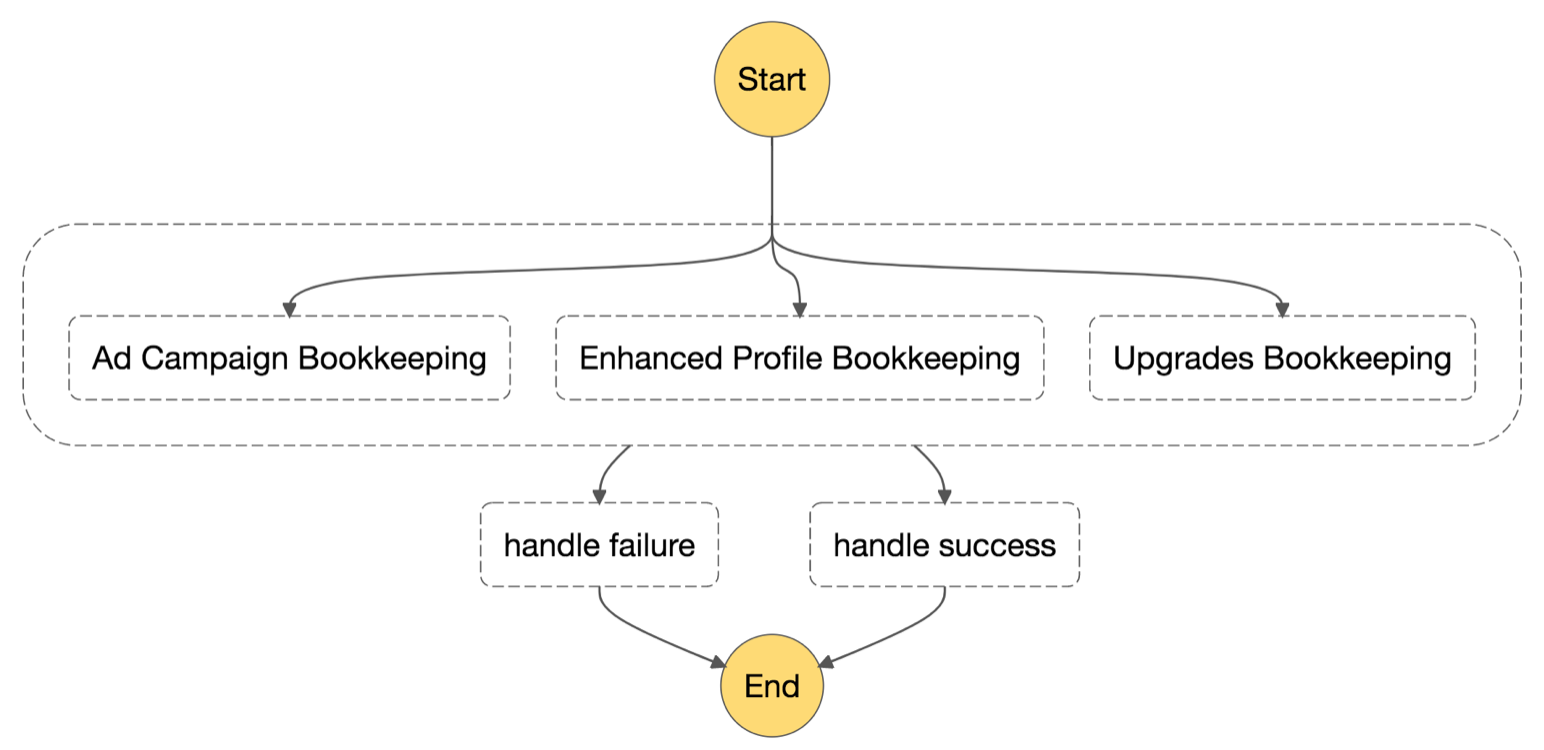
The result was a faster billing process with nearly no extra engineering effort. The role of Step Functions as a highly-scalable coordinator of these complex workflows worked very nicely. We proved our hypothesis that workflows would be easy to refactor down the line.
Results and future plans
We have installed this new subscription billing process alongside the old one and are rolling over all accounts to be processed by the Step Functions workflow. So far, we’ve found it to be very stable and capable of significant parallelism (after some adjustment of default API limits). We have gained a clear API to bill a single account, and the whole process is more resilient and observable.
To recap, the development process consisted of the following steps:
- Start with a single “bill account” function called from our monolithic batch process.
- Wrap a Step Functions API around the “bill account” function. Trigger concurrent executions for improved performance.
- Extract retries and failure handling from “bill account”. Move these into their own activities in Step Functions and build high quality metrics watching how often they are executed.
- Use this improved observability to make even more fundamental changes to the workflow (like breaking out parallel tasks). Functions get simpler and more decoupled while the overall workflow gets faster and easier to understand.
- Rinse and repeat until satisfied with the workflow’s design
Looking forward, we aim to continue incorporating invoice and collection steps into this workflow. Each of these is even more complicated internally, and we aim to simplify the number of dependent systems by leveraging the retries, timeouts, and parallelism built right into Step Functions. Look for us at re:Invent 2017, speaking in breakout session CMP319 on this project alongside the Step Functions team.