Migrating Kafka's Zookeeper With No Downtime

-
Toby Cole, Engineering Manager
- Jan 17, 2019
Here at Yelp we use Kafka extensively. In fact, we send billions of messages a day through our various clusters. Behind the scenes, Kafka uses Zookeeper for various distributed coordination tasks, such as deciding which Kafka broker is in charge of assigning partition leaders and storing metadata about the topics in its brokers.
Kafka’s success within Yelp has also meant that our clusters have grown substantially from when they were first deployed. At the same time, our other heavy Zookeeper users (e.g., Smartstack and PaasTA) have increased in scale, putting more load on our shared Zookeeper clusters. To alleviate this situation, we made the decision to migrate our Kafka clusters to use dedicated ZooKeeper clusters.
Since we rely so heavily on Kafka, any downtime due to maintenance can cause knock-on effects, like delays in the dashboards we show to business owners and logs backing up on our servers. And so the question arose… can we switch Zookeeper clusters without Kafka and other ZooKeeper users noticing?
Zookeeper Mitosis
After a few rounds of discussion and brainstorming between the teams that look after Kafka and Zookeeper, we figured out an approach that seemed to allow us to achieve our goal: Migrate the Kafka clusters into their own dedicated Zookeeper clusters without any Kafka downtime.
The procedure we came up with can be compared to the process of cell mitosis in nature: At a high level, we replicate the Zookeeper hosts (our DNA), and then divide the duplicated hosts into two separate clusters using firewall rules (our cell walls).
Major events in mitosis, where chromosomes are divided in a cell nucleus
Let’s delve a bit deeper into the details, step by step. Throughout this post we’ll be referring to the source- and destination-clusters, with the source representing the cluster that already exists and the destination the new cluster that Kafka will be migrated to. The examples we’ll be using are for a three-node Zookeeper cluster, but the process itself works for any number of nodes.
Our examples will use the following IP addresses for the Zookeeper nodes:
| Source | 192.168.1.1-3 |
| Destination | 192.168.1.4-6 |
Stage One: DNA Replication
First, we need to fire up a new Zookeeper cluster. This destination-cluster MUST be entirely empty, as the contents will be wiped out during the migration process.
We’ll then take two of the destination nodes and add them to the source-cluster, giving us a five-node Zookeeper cluster. The reason for this is that we want the data (originally stored by Kafka on the source ZooKeeper cluster) to get copied onto the destination-cluster. By joining the two destination nodes to the source-cluster, the copy is performed automatically by ZooKeeper’s replication mechanism.
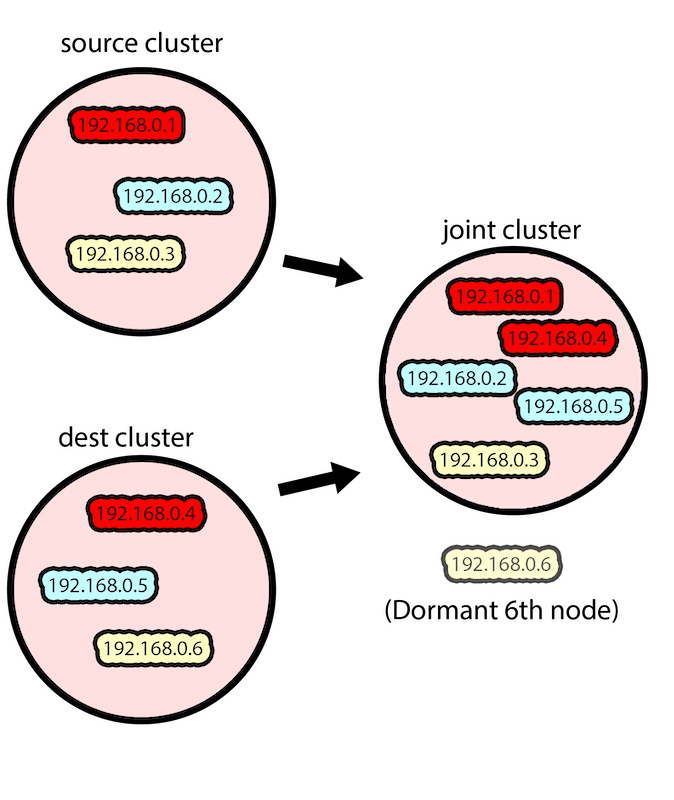
Nodes from the source- and destination-clusters are combined
Each of the nodes’ zoo.cfg file looks something like this now, with all of the source nodes and two of the destination nodes in the cluster:
server.1=192.168.1.1:2888:3888
server.2=192.168.1.2:2888:3888
server.3=192.168.1.3:2888:3888
server.4=192.168.1.4:2888:3888
server.5=192.168.1.5:2888:3888
Notice that one of the nodes from the destination ZooKeeper cluster (192.168.1.6 in the above example) remains dormant during the procedure; it does not become a part of the joint-cluster,and ZooKeeper is not running on it. The reason for this dormancy is to maintain quorum in the source ZooKeeper cluster.
At this point the joint ZooKeeper cluster has to be restarted. Make sure you perform a rolling restart (restart a single node at a time with at least 10-second intervals between each) starting with the two nodes from the destination-cluster. This order ensures that quorum is not lost in the source ZooKeeper cluster and ensures availability for other clients, e.g. Kafka, while the new nodes are joining the cluster.
After the rolling restart of ZooKeeper nodes, Kafka has no idea about the new nodes in the joint-cluster, as its Zookeeper connection string only has the original source-cluster’s IP addresses:
zookeeper.connect=192.168.1.1,192.168.1.2,192.168.1.3/kafka
Data being sent to Zookeeper is now being replicated to the new nodes without Kafka even noticing.
Now that the data is in sync between the source and destination Zookeeper clusters, we can update Kafka’s Zookeeper connection string to point to the destination-cluster:
zookeeper.connect=192.168.1.4,192.168.1.5,192.168.1.6/kafka
A rolling restart of Kafka is required for it to pick up the new connections, but this does not require any downtime for the cluster as a whole.
Stage Two: Mitosis
The first step of splitting the joint-cluster is restoring the original source and destination ZooKeeper configuration files (zoo.cfg), as they reflect the desired final state of the clusters. Note that none of the Zookeeper services should be restarted at this point.
We use firewall rules to perform our mitosis, splitting our joint ZooKeeper cluster into distinct source and destination-clusters, each with their own leader. In our case, we’re using iptables to achieve this, but any firewall system that you can enforce between the hosts in your two Zookeeper clusters should suffice.
For each destination node, we run the following commands to add iptables rules:
$source_node_list = 192.168.1.1,192.168.1.2,192.168.1.3
sudo /sbin/iptables -v -A INPUT -p tcp -d $source_node_list -j REJECT
sudo /sbin/iptables -v -A OUTPUT -p tcp -d $source_node_list -j REJECT
This rejects any incoming or outgoing TCP traffic to the source nodes from the destination nodes, achieving a separation of the two clusters.
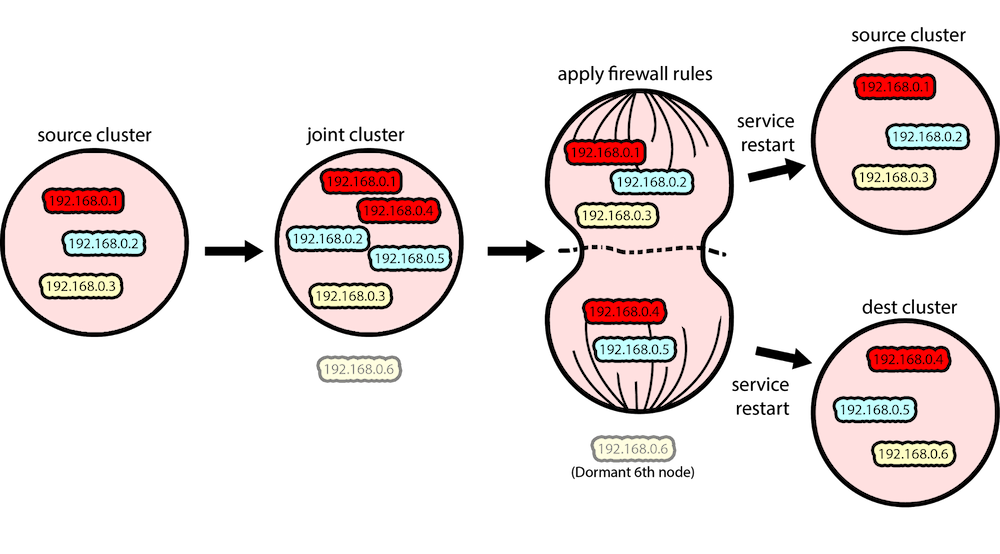
The source and destination clusters are separated by firewall rules and then restarted
The split means that we now have two destination nodes on their own. Since they think they’re part of a five-node cluster and cannot talk to a majority of their cluster, they will not elect a leader.
At this point, we simultaneously restart Zookeeper on every node in the destination-cluster, including the dormant node that was not part of the joint-cluster. This allows the Zookeeper processes to pick up their new configuration from step two. It also forces a leader election in the destination-cluster so that each cluster has its own leader.
From Kafka’s perspective, the destination-cluster is unavailable from the moment the network partition is added until the leader election completes. This is the only time ZooKeeper is unavailable to Kafka throughout the whole procedure. From now on, we have two distinct Zookeeper clusters, and there is no return! At least, not without copying data between clusters and possible data loss or downtime for Kafka.
All we have to do now is clean up after ourselves. The source-cluster still thinks it has two extra nodes, and we have some firewall rules in place that need to be cleared up.
Next, we restart the source cluster in order to pick up the zoo.cfg configuration containing only the original source-cluster nodes. This allows us to safely remove firewall rules, as the clusters are no longer trying to talk to each other. The following command drops the iptables rules:
$source_node_list = 192.168.1.1,192.168.1.2,192.168.1.3
sudo /sbin/iptables -v -D INPUT -p tcp -d $source_node_list -j REJECT
sudo /sbin/iptables -v -D OUTPUT -p tcp -d $source_node_list -j REJECT
Building Confidence
Distributed Stress Test
The main approach we took to test the correctness of the migration procedure was a distributed stress test. The script runs tens of instances of Kafka producers and consumers across multiple machines while the migration procedure is in progress. After traffic generation finishes, all consumed payloads are aggregated into a single host to check for data loss.
The distributed stress test works by creating a set of Docker containers for Kafka producers and consumers and running them in parallel on multiple hosts, the list of which is passed as one of the parameters of the experiment. All produced messages contain serial numbers that can be used to check for message loss.
Ephemeral Clusters
In order to prove that this migration procedure was going to work, we wanted to build some clusters specifically for testing. Rather than manually building Kafka clusters and tearing them down again, we built a tool to spin up new clusters within our infrastructure that could be torn down automatically, allowing us to script the whole test procedure.
The tool connects to the AWS EC2 API and fires up several hosts with specific EC2 instance tags, permitting our puppet code, via External Node Classifiers, to figure out how to configure the host and install Kafka. This ultimately allowed us to run and re-run our migration scripts, simulating the migration multiple times.
The Ephemeral Cluster script was later reused to create ephemeral Elasticsearch-clusters for our integration testing, proving to be an invaluable tool.
zk-smoketest
We found phunt’s simple Zookeeper smoketest scripts extremely useful in monitoring the state of each Zookeeper cluster while we were migrating. Throughout each stage of the migration we ran a smoketest in the background to ensure the Zookeeper clusters were behaving as expected.
zkcopy
Our first (naive) plans for the migration involved simply stopping Kafka, copying a subset of the Zookeeper data over to the new cluster, and starting Kafka with an updated Zookeeper connection. A more refined version of this procedure, which we called ‘block & copy’, is still used for moving Zookeeper clients to clusters with data stored in them, as the ‘mitosis’ procedure requires a blank destination Zookeeper cluster. A great tool for copying subsets of Zookeeper data is zkcopy, which copies a sub-tree of one Zookeeper cluster to another.
We also added transaction support, enabling us to batch Zookeeper operations and minimize the network overhead of creating one transaction per znode. This sped up our usage of zkcopy by about 10x!
Another feature that was core to our speedup was ‘mtime’ support, which allowed us to skip copying any nodes older than a given modification time. Through this, we were able to avoid a majority of the work for the second ‘catch-up’ copy required to get our Zookeeper clusters in sync. The downtime needed for Zookeeper went from 25 minutes to less than two!
Lessons Learned
Zookeeper clusters are pretty lightweight. When possible, try not to share them between different services, as they may start to cause performance issues in Zookeeper, which are hard to debug and usually require downtime to repair.
It is possible to migrate Kafka to a new Zookeeper cluster without any Kafka downtime, but it’s certainly not trivial.
If you can schedule Kafka downtime to do your Zookeeper migration, it’ll be a lot simpler.
Credits
Piotr Chabierski - Initial draft & reviews
Raghu Prabhu - Reviews
Toby Cole - Typing furiously & photoshoppery
Become an Engineer at Yelp
Come and work with the teams in London that wrangled these various moving parts!
View Job